



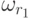

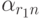


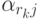



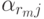



|
Неоднократно находил ошибки в тестах, особенно в экзаменационных вопросах, когда правильно данный ответ на вопрос определялся в итоге как не правильно отвеченный... Из-за этого сильно страдает конечный бал! Да еще в заблуждение студентов вводит! Они-то думают, что это они виноваты!!! Но они тут не причем! Я много раз проверял ответы на некоторые такие "ошибочные" вопросы по нескольким источникам - результат везде одинаковый! Но ИНТУИТ выдавал ошибку... Как это понимать? Из-за подобных недоразумений приходиться часами перерешивать экзамен на отличную оценку...!!! Исправьте, пожалуйста, такие "ошибки"... |
Опубликован: 18.05.2005 | Уровень: специалист | Доступ: свободно | ВУЗ: Московский государственный технологический университет «Станкин»
Лекция 4:
Распознавание изображений
Аннотация: В лекции рассматриваются характеристики задач распознавания
образов и их типы, основы теории анализа и распознавания изображений
(признаковый метод), распознавание по методу аналогий. Среди множества
интересных задач по распознаванию рассмотрены принципы и подход к
распознаванию в задачах машинного чтения печатных и рукописных текстов.
Ключевые слова: распознавание, признаковый метод распознавания, признак, значение, объект, система распознавания, характеристика задачи распознавания, распознавание образов, типы задач, обучение без учителя, разбиение множества, таксономия, кластерный анализ, разбиение, множества, таблица обучения, распознавание изображений, порог, алгоритм, таблица, алфавит, распознавание по методу аналогий, знание, вес, программа, распознавание машинописных и рукописных текстов, управляющая система, принцип целостности, сегментация, список
Современные роботы, снабженные телевизионными камерами, способны достаточно хорошо видеть, чтобы работать с реальным миром. Они могут делать заключения о том, какого типа объекты присутствуют, в каких они находятся отношениях между собой, какие группы образуют, какой текст содержат и т. д. Однако сложные задачи распознавания, например, распознавание похожих трехмерных быстродвижущихся объектов или неразборчивого рукописного текста требуют совершенствования методов и средств для своего решения. В этой лекции мы рассмотрим основы некоторых традиционных методов распознавания. Наше рассмотрение мы начнем с наиболее часто применяемого признакового метода распознавания [ 1.4 ] , [ 4.1 ] .
Общая характеристика задач распознавания образов и их типы.
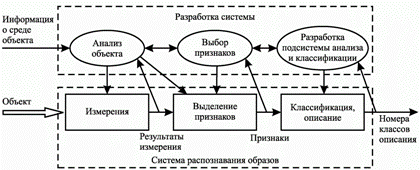
Под образом понимается структурированное описание изучаемого объекта или явления, представленное вектором признаков, каждый элемент которого представляет числовое значение одного из признаков, характеризующих соответствующий объект. Общая структура системы распознавания и этапы в процессе ее разработки показаны на рис. 4.1.
Суть задачи распознавания - установить, обладают ли изучаемые объекты фиксированным конечным набором признаков, позволяющим отнести их к определенному классу.
Задачи распознавания имеют следующие характерные черты.
- Это информационные задачи, состоящие из двух этапов: а) приведение исходных данных к виду, удобному для распознавания ; б) собственно распознавание (указание принадлежности объекта определенному классу).
- В этих задачах можно вводить понятие аналогии или подобия объектов и формулировать понятие близости объектов в качестве основания для зачисления объектов в один и тот же класс или разные классы.
- В этих задачах можно оперировать набором прецедентов-примеров, классификация которых известна и которые в виде формализованных описаний могут быть предъявлены алгоритму распознавания для настройки на задачу в процессе обучения.
- Для этих задач трудно строить формальные теории и применять классические математические методы (часто недоступна информация для точной математической модели или выигрыш от использования модели и математических методов не соизмерим с затратами).
- В этих задачах возможна "плохая" информация (информация с пропусками, разнородная, косвенная, нечеткая, неоднозначная, вероятностная).
Целесообразно выделить следующие типы задач распознавания.
- Задача распознавания - отнесение предъявленного объекта по его описанию к одному из заданных классов (обучение с учителем).
- Задача автоматической классификации - разбиение множества объектов (ситуаций) по их описаниям на систему непересекающихся классов (таксономия, кластерный анализ, обучение без учителя).
- Задача выбора информативного набора признаков при распознавании.
- Задача приведения исходных данных к виду, удобному для распознавания.
- Динамическое распознавание и динамическая классификация - задачи 1 и 2 для динамических объектов.
- Задача прогнозирования - это задачи 5, в которых решение должно относиться к некоторому моменту в будущем.
Основы теории анализа и распознавания изображений.
Пусть дано множество M объектов ;
на этом множестве существует разбиение на
конечное число подмножеств (классов)  i = {1,m},
i = {1,m},  Объекты
Объекты 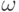 задаются значениями некоторых признаков xj, j= {1,N}. Описание объекта
задаются значениями некоторых признаков xj, j= {1,N}. Описание объекта 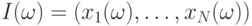 называют стандартным, если
называют стандартным, если  принимает значение из множества допустимых значений.
принимает значение из множества допустимых значений.
Пусть задана таблица обучения (
таблица
4.1). Задача распознавания состоит в том, чтобы для заданного
объекта и набора классов 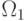 , ...,
, ...,  по обучающей
информации в таблице обучения
по обучающей
информации в таблице обучения  о классах и описанию
о классах и описанию  вычислить предикаты:
вычислить предикаты:

где i= {1,m},  - неизвестно.
- неизвестно.
Рассмотрим алгоритмы распознавания, основанные на вычислении оценок. В их основе лежит принцип прецедентности (в аналогичных ситуациях следует действовать аналогично).
Пусть задан полный набор признаков x1, ..., xN.
Выделим систему подмножеств множества признаков S1, ..., Sk. Удалим произвольный набор признаков из строк  ,
,  , ...,
, ...,  и обозначим
полученные строки через
и обозначим
полученные строки через  ,
,  , ...,
, ...,  ,
,  .
.
Правило близости, позволяющее оценить
похожесть строк и  состоит в следующем.
Пусть "усеченные" строки содержат q первых
символов, то есть
состоит в следующем.
Пусть "усеченные" строки содержат q первых
символов, то есть 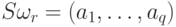 и
и  Заданы пороги
Заданы пороги  ...
...  ,
,  Строки и
считаются похожими, если выполняется не менее
чем
Строки и
считаются похожими, если выполняется не менее
чем 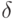 неравенств вида
неравенств вида

Величины ... , входят в качестве параметров в модель
класса алгоритмов на основе оценок.
Пусть  - оценка объекта
- оценка объекта  по классу
по классу  .
.
Описания объектов  , предъявленные для распознавания, переводятся в числовую матрицу
оценок. Решение о том, к какому классу отнести
объект, выносится на основе вычисления степени
сходства распознавания объекта (строки) со
строками, принадлежность которых к заданным
классам известна.
, предъявленные для распознавания, переводятся в числовую матрицу
оценок. Решение о том, к какому классу отнести
объект, выносится на основе вычисления степени
сходства распознавания объекта (строки) со
строками, принадлежность которых к заданным
классам известна.
Проиллюстрируем описанный алгоритм распознавания на примере. Задано 10 классов объектов (рис. 4.2а). Требуется определить признаки таблицы обучения, пороги и построить оценки близости для классов объектов, показанных на рис. 4.2б. Предлагаются следующие признаки таблицы обучения:
x1 - количество вертикальных линий минимального размера;
x2 - количество горизонтальных линий;
x3 - количество наклонных линий;
x4 - количество горизонтальных линий снизу объекта.
На рис. 4.3 приведена таблица обучения и пороги

Из этой таблицы видно, что неразличимость символов 6 и 9 привела к необходимости ввода еще одного признака x4.
Теперь может быть построена таблица распознавания для объектов на рис. 4.2б.
| Объект | x1 | x2 | x3 | x4 | Результат распознавания |
|---|---|---|---|---|---|
| Объект 1 | 1 | 2 | 1 | Цифра 2 | |
| Объект 2 | 3 | 3 | 0 | 1 | Цифра 8 или 5 |
| Объект 3 | 4 | 1 | 0 | ||
| Объект 4 | 4 | 2 | 0 | 1 |
Читателю предлагается самостоятельно ответить на
вопрос: что будет, если увеличить пороги ,  ,
, 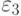 ,
, 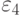 ,
, 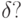 Как изменится качество распознавания в данной задаче?
Как изменится качество распознавания в данной задаче?
Заключая данный раздел лекции, отметим важную мысль, высказанную А. Шамисом в работе [ 4.2 ] : качество распознавания во многом зависит от того, насколько удачно создан алфавит признаков, придуманный разработчиками системы. Поэтому признаки должны быть инвариантны к ориентации, размеру и вариациям формы объектов.
Дмитрий Черепанов
Анжелика Шлома
|
Огромная просьба сделать проще тесты, это просто ужас какой-то! Слишком сложно! |