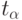 -
- 
|
Подскажите, пожалуйста, планируете ли вы возобновление программ высшего образования? Если да, есть ли какие-то примерные сроки? Спасибо! |
Опубликован: 16.11.2010 | Доступ: свободный | Студентов: 5241 / 2914 | Оценка: 4.43 / 4.14 | Длительность: 27:21:00
Специальности: Программист, Системный архитектор
Лекция 6:
Обработка результатов имитационного эксперимента
5.9. Сущность корреляционного анализа
Часто при исследовании объекта или его модели необходимо наблюдать за характеристиками двух и более случайных величин. Например, за двумя откликами одного эксперимента. При этом может возникнуть вопрос: есть ли связь между этими случайными величинами? Существенна или несущественна эта связь, если она есть?
Корреляционный анализ - это совокупность методов обнаружения зависимости (корреляции) между двумя или более случайными признаками или процессами.
Под корреляцией будем понимать статистическую зависимость между двумя случайными величинами, не имеющую, вообще говоря, строго функционального характера.
Заметим, что корреляционный анализ не позволяет определить вид функциональной связи между случайными величинами, а только наличие или отсутствие предполагаемой связи, например, линейной, параболической, экспоненциальной и т. д. В рамках этого учебного пособия мы ограничимся рассмотрением гипотезы о наличии линейной корреляции.
Определение вида функциональной связи между величинами рассматривается в регрессионном анализе, элементы которого и практическое использование будут рассмотрены в следующем п. 5.10.
Название "корреляционный анализ" происходит от латинского слова correlatio - согласование, связь, соотношение, взаимосвязь. Термин впервые введен Гальтоном (Galton) в 1888 г.
Обычно исследуют парную корреляцию, то есть зависимость между двумя случайными величинами (процессами), хотя возможны и более сложные ситуации, когда необходимо обнаружить наличие или отсутствие связей между тремя или более случайными величинами.
Мы ограничимся исследованием парной корреляции.
Как известно, связь между двумя случайными величинами можно описать с помощью двумерной функции распределения. Однако такое описание часто очень сложно, а для практических целей можно удовлетвориться определением зависимостей средних значений.
Итак, целью имитационного эксперимента является определение характеристик двух случайных величин 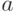 и
и 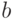 . Например:
. Например:

|

|
|---|---|
| Средний балл успеваемости учебной группы по математике | Средний балл выполнения упражнения по стрельбе |
| Рассеивание точки падения заряда по дальности | Рассеивание точки падения заряда по боковому отклонению |
| Вес курсантов (студентов). | Успеваемость по физподготовке. |
Необходимо проверить: есть ли связь между величинами и ?
Проверка наличия (или отсутствия) связи - корреляции - между случайными величинами выполняется так.
Проводится два эксперимента, каждый - с соответствующей моделью. В каждом эксперименте - 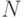 наблюдений (напоминаем, что компьютерный эксперимент состоит из наблюдений, а наблюдение - из реализаций (прогонов) модели, число которых рассчитывается с учетом требуемой точности и достоверности получаемых результатов моделирования). В результате экспериментов получаются два множества значений измеряемых параметров и :
наблюдений (напоминаем, что компьютерный эксперимент состоит из наблюдений, а наблюдение - из реализаций (прогонов) модели, число которых рассчитывается с учетом требуемой точности и достоверности получаемых результатов моделирования). В результате экспериментов получаются два множества значений измеряемых параметров и : 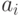 и
и 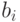 ,
,  .
.
Из этих множеств формируются пары:

Каждая пара интерпретируется как координаты случайной точки в системе координат , .
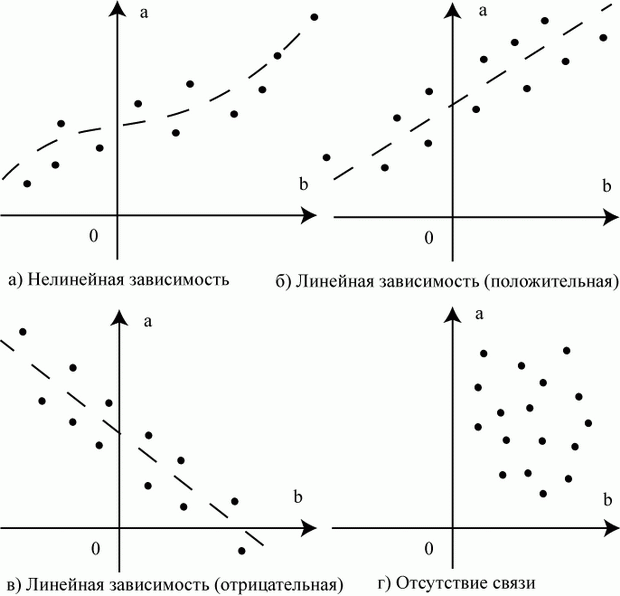
Первичное исследование можно провести графически. Возможны следующие варианты размещения точек на графиках (рис. 5.5).
Корреляция - важное понятие. Научитесь визуально определять по расположению данных, насколько тесно они коррелированны.
Говорят, что две переменные положительно коррелированны, если при увеличении значений одной переменной увеличиваются значения другой переменной (рис. 5.5б).
Две переменные отрицательно коррелированны, если при увеличении одной переменной другая переменная уменьшается (рис. 5.5в).
Отсутствие корреляции - совместного поведения переменных - обнаруживается хаотическим нагромождением точек, исключающим проведение какой-либо аппроксимирующей линии (см. рис. 5.5г).
Но такое качественное исследование недостаточно. Необходимо иметь количественную оценку степени корреляции между величинами и .
Если совместное распределение вероятностей случайных величин и нормальное, то количественной характеристикой степени линейной связи между ними является коэффициент корреляции r (введен Пирсоном (Pearson), 1896 г.):
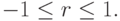
Если 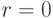 , то между
, то между  и линейная независимость.
и линейная независимость.
Равенство  свидетельствует о наличии однозначной функциональной связи между и , то есть
свидетельствует о наличии однозначной функциональной связи между и , то есть  .
.
При  между и существует стохастическая связь, причем, чем ближе коэффициент корреляции
между и существует стохастическая связь, причем, чем ближе коэффициент корреляции 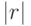 к единице, тем эта связь сильнее. Стохастическая связь означает, что при изменении имеется лишь тенденция к изменению .
к единице, тем эта связь сильнее. Стохастическая связь означает, что при изменении имеется лишь тенденция к изменению .
Коэффициент корреляции 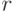 определяется по данным эксперимента, следовательно, можно определить только его оценку
определяется по данным эксперимента, следовательно, можно определить только его оценку 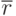 . В качестве оценки принят выборочный коэффициент корреляции:
. В качестве оценки принят выборочный коэффициент корреляции:
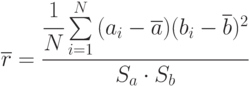
где 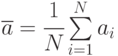 оценки математических ожиданий и
оценки математических ожиданий и ![M[a]](/sites/default/files/tex_cache/84f1c6a6971e2c862d7a52fbfb072a62.png) и
и ![M[b]](/sites/default/files/tex_cache/f2f0df453c7bde2b215c3e438907b4fd.png) ;
;
 - оценки среднеквадратических отклонений
- оценки среднеквадратических отклонений  и
и 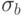
Выборочный коэффициент корреляции , так же как и теоретический, принимает значения: 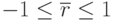 .
.
Если  , то наблюдается положительная корреляция (см. рис. 5.5б). Если
, то наблюдается положительная корреляция (см. рис. 5.5б). Если 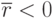 - отрицательная корреляция (см. рис. 5.5в). Если
- отрицательная корреляция (см. рис. 5.5в). Если  - линейная корреляция отсутствует (но не исключена нелинейная). Если
- линейная корреляция отсутствует (но не исключена нелинейная). Если 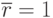 , то между случайными величинами существует жесткая функциональная связь.
, то между случайными величинами существует жесткая функциональная связь.
Заметим, что рассматриваемый коэффициент корреляции определяет степень линейной связи между случайными величинами и . Эта корреляция наиболее популярна, поэтому часто, когда говорят о корреляции, имеют в виду именно корреляцию Пирсона.
Однако этот линейный коэффициент корреляции не является пригодным для оценки нелинейной связи, если таковая присутствует. При нелинейной зависимости степень связи между случайными величинами устанавливается более сложными характеристиками, например, корреляционным отношением (К. Пирсон).
Числитель выражения (5.1) иногда называют ковариацией - 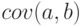 .
.
Если случайные величины и независимы, они и не коррелированны 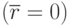 . Но некоррелированность и не всегда свидетельствует об их независимости. Но если и имеют нормальное распределение, то условие является необходимым и достаточным условием независимости этих величин.
. Но некоррелированность и не всегда свидетельствует об их независимости. Но если и имеют нормальное распределение, то условие является необходимым и достаточным условием независимости этих величин.
И еще. Наличие корреляции между случайными величинами и не всегда свидетельствует об их взаимосвязи. Дело в том, что при независимости и каждая из них в отдельности зависит от некоторого случайного фактора 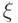 , но эта зависимость нами не замечена.
, но эта зависимость нами не замечена.
Поэтому хорошим тоном после вычисления корреляций является построение диаграмм рассеяния, которые позволяют понять, действительно ли между двумя исследуемыми переменными имеется связь.
Оценка коэффициента корреляции должна быть определена с требуемыми точностью и достоверностью, которые зависят от числа реализаций модели. Найдем эту связь.
В предположении нормальности распределения можно написать:
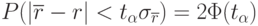
С выражение (5.2) мы уже знакомы. Здесь:
- точное значение коэффициента корреляции;
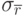 - среднеквадратическое отклонение случайной величины ;
- среднеквадратическое отклонение случайной величины ;
Обычно среднеквадратическое отклонение неизвестно, поэтому нужно брать ее оценку.
При больших выборках 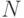 оценка среднеквадратического отклонения
оценка среднеквадратического отклонения  :
:

Из (5.2) следует:
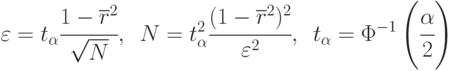
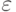 - абсолютная величина ошибки.
- абсолютная величина ошибки.
Предварительное определение  осуществляется по данным пробного эксперимента в количестве
осуществляется по данным пробного эксперимента в количестве  реализаций модели.
реализаций модели.
На основании изложенного и в силу случайного характера исследуемых величин и мы можем утверждать лишь следующее: истинное значение коэффициента корреляции лежит в пределах

с заданной достоверностью  .
.
В заключение отметим, что если совместное распределение случайных величин и не является нормальным, то оценка коэффициента корреляции может выступать в качестве ориентировочной оценки степени тесноты связи и .
Пример 5.7 [2]. Для оценки конструкции нового крупнокалиберного пулемета было произведено 96 выстрелов по щиту, отстоявшему на расстоянии 300 метров.
Результаты отклонений попаданий от точки прицеливания (боковые  , по высоте
, по высоте  ) объединены в десятисантиметровые диапазоны и сведены в таблицу (табл. 5.9).
) объединены в десятисантиметровые диапазоны и сведены в таблицу (табл. 5.9).
Для оценки конструктивных особенностей пулемета необходимо узнать: есть ли какая-то связь между боковыми отклонениями и отклонениями по высоте.
Решение
Ответ на поставленный вопрос может дать коэффициент корреляции. Предварительно заметим, что группировка измерений в десятисантиметровые диапазоны вносит некоторую ошибку в дальнейшие расчеты, однако можно показать, что при данной группировке ошибка несущественна.
В табл. 5.9 указаны не реальные отклонения, а центры диапазонов (-25…-15, -15…-5, -5…5 и т. д.).
 |
Боковые отклонения 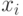 |
Всего  |
||||||
|---|---|---|---|---|---|---|---|---|
| -20 | -10 | 0 | 10 | 20 | 30 | 40 | ||
| -50 | 0 | 0 | 1 | 0 | 2 | 0 | 0 | 3 |
| -40 | 0 | 1 | 1 | 1 | 2 | 0 | 0 | 5 |
| -30 | 1 | 1 | 3 | 5 | 2 | 1 | 0 | 13 |
| -20 | 1 | 3 | 7 | 3 | 2 | 2 | 0 | 18 |
| -10 | 0 | 2 | 6 | 10 | 3 | 0 | 0 | 21 |
| 0 | 0 | 1 | 6 | 6 | 6 | 1 | 1 | 21 |
| 10 | 0 | 0 | 3 | 3 | 3 | 1 | 0 | 10 |
| 20 | 0 | 1 | 1 | 2 | 1 | 0 | 0 | 5 |
Всего 
|
2 | 9 | 28 | 30 | 21 | 5 | 1 | 96 |
Для определения коэффициента корреляции понадобятся следующие характеристики:
 , ковариация
, ковариация  .
.
Все эти характеристики вычисляются по данным измеренных отклонений боковых 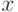 и по высоте
и по высоте 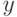 .
.
Для примера, расчет  :
:
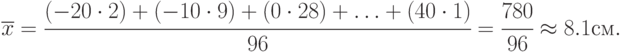
Результаты расчета остальных характеристик:
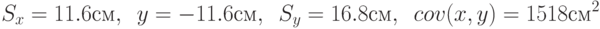
Теперь оценка коэффициента корреляции:
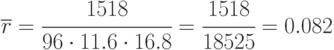
Среднеквадратическое отклонение этой оценки:

Из-за малого количества выстрелов оценка определена с ошибкой, которая в предположении о нормальном распределении случайной величины и достоверности, например, 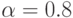 (
( 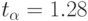 ) равна:
) равна:
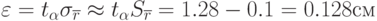
Отсюда следует, что истинное значение коэффициента корреляции 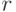 лежит в пределах:
лежит в пределах:

Обнаружена небольшая линейная зависимость отклонений боковых и по высоте. Баллистики, отвергая непосредственную корреляцию между отклонениями  и
и  , объясняют значение влиянием конструктивных особенностей пулемета. Обнаружена также систематическая ошибка в прицеле:
, объясняют значение влиянием конструктивных особенностей пулемета. Обнаружена также систематическая ошибка в прицеле: 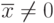 ,
,  .
.
Владислав Нагорный
Лариса Парфенова
|
1) Можно ли экстерном получить второе высшее образование "Программная инженерия" ? 2) Трудоустраиваете ли Вы выпускников? 3) Можно ли с Вашим дипломом поступить в аспирантуру?
|