|
Подскажите, пожалуйста, планируете ли вы возобновление программ высшего образования? Если да, есть ли какие-то примерные сроки? Спасибо! |
Спонсор: Microsoft
Вы можете этот курс.
Опубликован: 20.12.2010 | Доступ: свободный | Студентов: 2412 / 165 | Оценка: 4.27 / 3.91 | Длительность: 39:39:00
ISBN: 978-5-9963-0353-3
Тема: Базы данных
Специальности: Администратор баз данных
Теги:
Лекция 12:
Создание модели хранилища данных на основе корпоративной модели данных
Обсуждение примера
Таким образом, мы выполнили построение многомерной модели киоска данных на основе корпоративной модели данных.
Скрипт для создания киоска данных в СУБД MS SQL Server приведен ниже.
/* Table: Sale */
create table Sale (
SALE_ID integer not null,
STOR_ID char(12) null,
TITLE_ISBN char(10) null,
SALE_DATE datetime null,
SALE_AMOUNT numeric(8,2) null,
SALE_TERMS varchar(80) null,
SALE_QTY numeric null,
constraint PK_SALE primary key (SALE_ID)
)
go
/* Table: Store */
create table Store (
STOR_ID char(12) not null,
STOR_NAME varchar(40) null,
CITY varchar(20) null,
STATE varchar(80) null,
POSTALCODE char(6) null,
STOR_ADDRESS varchar(80) null,
constraint PK_STORE primary key (STOR_ID)
)
go
/* Table: Title */
create table Title (
TITLE_ISBN char(10) not null,
PUB_ID char(12) null,
TITLE_TEXT varchar(80) null,
TITLE_TYPE varchar(20) null,
TITLE_PRICE numeric(8,2) null,
TITLE_NOTES varchar(1) null,
TITLE_PUBDATE datetime null,
PERIODICAL char20) null,
PER_FREQUENCY char(20n) null,
NONP_COLLECTION varchar(80) null,
constraint PK_TITLE primary key (TITLE_ISBN)
)
go
alter table Sale
add constraint FK_SALE_REFERENCE_STORE foreign key (STOR_ID)
references Store (STOR_ID)
go
alter table Sale
add constraint FK_SALE_REFERENCE_TITLE foreign key (TITLE_ISBN)
references Title (TITLE_ISBN)
go
Листинг
.
Построенный кисок данных предназначен для анализа продаж компании розничной торговли издательской продукцией через сеть своих магазинов (бизнес-процесс 1).
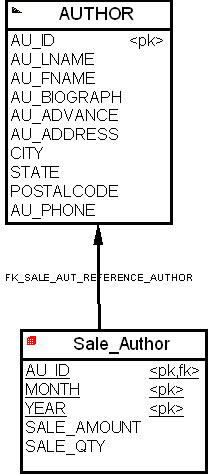
Проводя аналогичные рассуждения для бизнес-процесса 2, мы получим схему многомерной модели, состоящую из таблицы фактов "Продажи по автору" ( Sale_Author ) и измерения "Авторы" ( Author ), как показано на рис. 16.25.
Заметим, что в этой многомерной модели киоска данных гранулированность определена как продажи автора за месяц, а поля таблицы фактов "Сумма продаж" ( SALE_AMOUNT ) и "Количество продаж" ( SALE_QTY ) являются производными полями, вычисляемыми как соответствующие суммы за месяц.
Секционирование таблиц многомерной модели данных в PowerDesigner
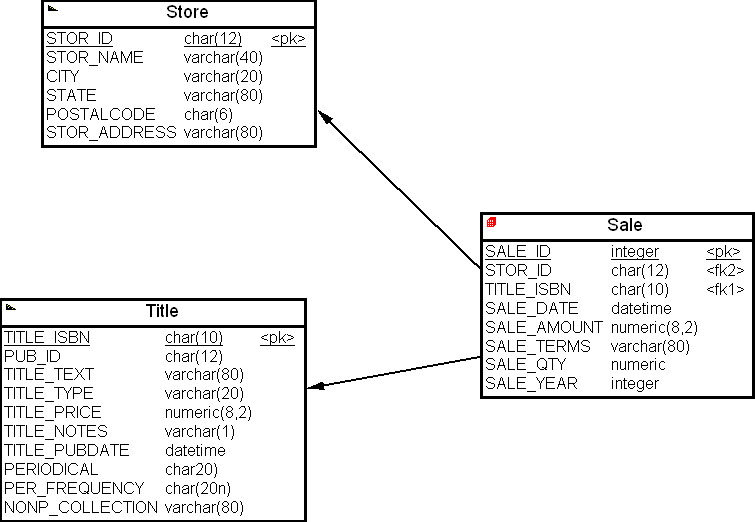
Рассмотрим, как CASE-средства помогают проектировщику данных выполнять секционирование таблиц многомерной модели данных. Обратимся к примеру из предыдущего раздела настоящей лекции и рассмотрим многомерную модель киоска данных на рис. 16.24.
Предположим, что маркетинговая служба анализирует постоянно продажи изданий текущего года, а по годам анализ продаж выполняется один раз в год. Тогда целесообразно с целью увеличения производительности запросов выполнить горизонтальное секционирование таблицы фактов "Продажи" ( Sale ) по годам. Для этого введем в таблицу фактов атрибут "Год продажи" ( SALE_YEAR ) ( рис. 16.26). Предположим также, что киоск данных будет наполняться данными, начиная с 2007 года.
Заметим, что вместо этого действия мы могли ввести еще одну таблицу измерения "Время" с атрибутом "Год" и установить связь этого измерения с таблицей фактов модели.
Напомним, что горизонтальное секционирование таблицы состоит в разбиении исходной таблицы на несколько таблиц, каждая из которых содержит подмножество строк исходной таблицы.
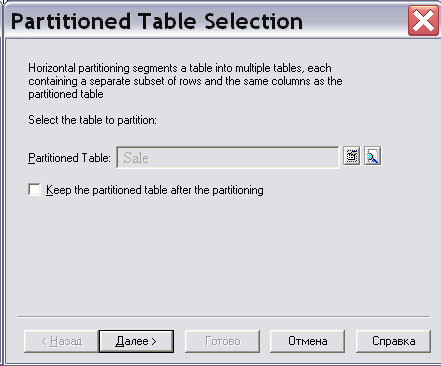
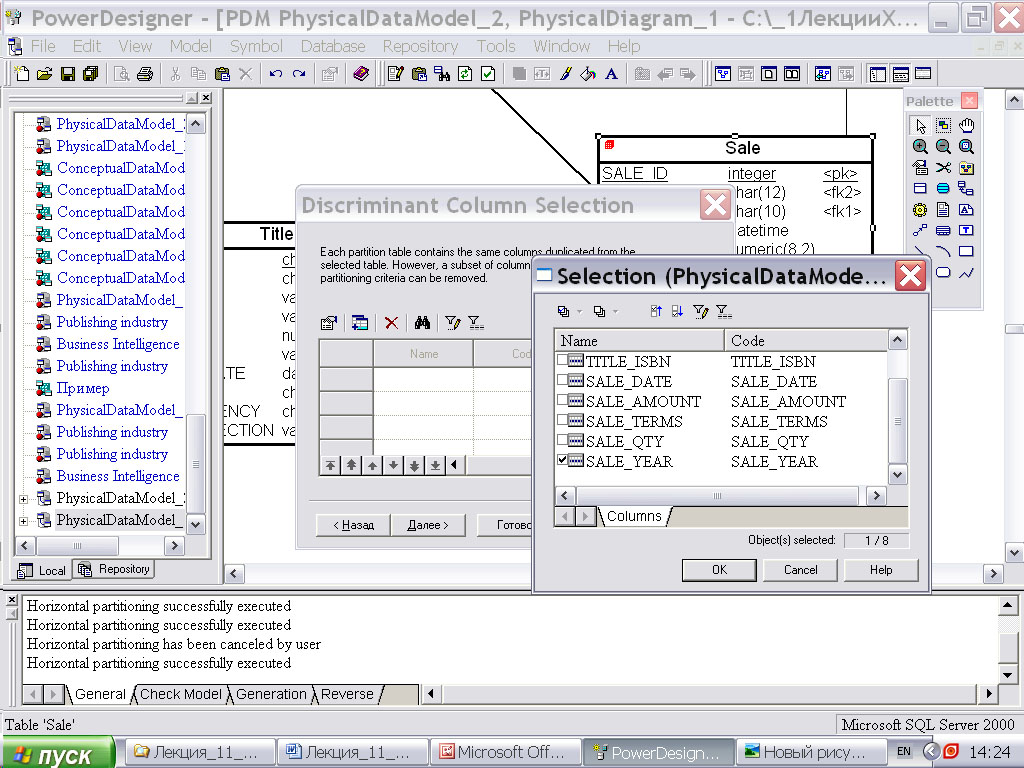
Для того чтобы выполнить горизонтальное секционирование таблицы фактов "Продажи" ( Sale ) при помощи CASE PowerDesigner, можно щелкнуть правой кнопкой мыши на таблице фактов и из всплывающего меню выбрать пункт "Горизонтальное секционирование" ( Horizontal Partitioning ). На экране появится диалоговое окно "Выбор таблицы для секционирования" ( Partitioned Table Selection ). Выбрав таблицу "Продажи" ( Sale ), нажмите на кнопку " Далее " ( рис. 16.27).
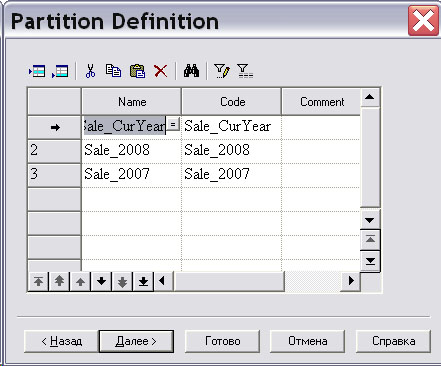
На экране появится диалоговое окно "Определение секций" ( Partition Definitions ), в котором необходимо определить имена секций (пусть это будут имена Sale_CurYear, Sale_2008 и Sale_2007 ) и нажать на кнопку " Далее " ( рис. 16.28).
На экране появится диалоговое окно "Выбор дискриминантной колонки" ( Discriminant Column Selection ). Дискриминантная колонка – это колонка таблицы, которая входит в критерий секционирования, поэтому ее не обязательно хранить в секциях. Щелкнув левой кнопкой мыши на пиктограмме " Добавить строку ", вы активизируете диалоговое окно "Выбор" ( Selection ). Выберем в списке колонок колонку "Год продажи" ( SALE_YEAR ), по которой будет выполняться секционирование, и нажмем кнопки " ОК " и " Далее " ( рис. 16.29).
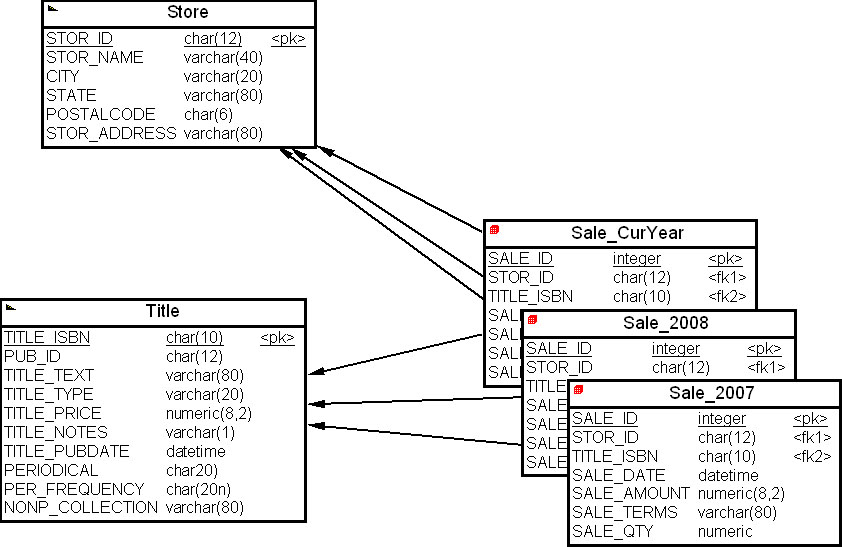
На экране появится диалоговое окно "Информация о секционировании" ( Partitioning Information ). Далее нажмем кнопку " Готово ". После расстановки на рабочем пространстве секций получим многомерную модель данных нашего киоска данных с секционированной таблицей "Продажи" ( Sale ), как на рис. 16.30.
увеличить изображение
Рис. 16.30. Многомерная модель киоска данных учебного примера с секционированной таблицей "Продажи" (Sale)
Таким образом, мы на примере рассмотрели, как можно использовать CASE-средство для преобразования корпоративной модели данных в многомерную модель ХД.
Резюме
При создании ХД в масштабе организации корпоративная модель данных, как правило, выступает отправной точкой проектирования модели ХД. В этом случае процедуру проектирования модели ХД можно разбить на следующие шаги.
- Выбрать данные данных корпоративной модели, которые будут сохраняться в ХД.
- Исследовать временные зависимости данных и, если необходимо, добавить элемент времени в ключи сущностей ХД.
- Добавить в модель производные элементы данных.
- Преобразовать взаимосвязи между данными.
- Определить уровень структуризации ( гранулированности ) данных в ХД.
- Перенести данные из таблиц корпоративной модели данных в таблицы выбранной схемы ХД.
- Выявить периодические группы данных или массивы данных.
- Разделить атрибуты согласно параметрам стабильности.
С точки зрения конкретного диалекта SQL, в рассмотренный алгоритм можно добавить еще несколько шагов, также связанных с обеспечением производительности ХД на проектном уровне — в частности, иерархии измерений и материализуемые представления.
Выполнять проектирование модели ХД на основе корпоративной модели данных организации целесообразно с помощью CASE-инструментария. Использование CASE-инструментария увеличивает производительность труда проектировщика ХД, особенно в случае крупных и средних проектов.
Владислав Нагорный
Лариса Парфенова
|
1) Можно ли экстерном получить второе высшее образование "Программная инженерия" ? 2) Трудоустраиваете ли Вы выпускников? 3) Можно ли с Вашим дипломом поступить в аспирантуру?
|