|
"...Изучение и анализ примеров.
В и приведены описания и приложены исходные коды параллельных программ..." Непонятно что такое - "В и приведены описания" и где именно приведены и приложены исходные коды. |
Опубликован: 15.10.2009 | Доступ: свободный | Студентов: 909 / 255 | Оценка: 4.42 / 4.20 | Длительность: 08:22:00
Специальности: Программист
Лекция 3:
Планирование исполнения процессов
Аннотация: В лекции рассматриваются вопросы планирования исполнения задач применительно к многопроцессорным вычислительным системам.
Ключевые слова: многопроцессорные вычислительные системы, отображение множества, Вычислительный элемент, алгоритм, планировщик , scheduling, загрузки процессоров, пропускная способность, FIFO, LIFO, доступ к процессору, вытеснение, приоритет процесса, многопроцессорная система, состояние процесса, WS-I, deque, parallelize, цикла, итератор, список
Планирование исполнения процессов является одним из ключевых теоретических и практических понятий, относящихся к многопроцессорным вычислительным системам. Планирование исполнения процессов или, в общем случае, задач, заключается в построении отображения множества задач на множество вычислительных элементов (ядер, процессоров) системы с учетом динамики ее работы. Программу, которая реализует тот или иной алгоритм планирования исполнения задач, называют планировщиком (scheduler).
Планировщик обычно пытается обеспечить максимальную загрузку процессоров, высокую пропускную способность системы - количество выполненных задач за единицу времени, минимальное время нахождения задачи в очереди на выполнение, справедливость распределения процессорного времени между задачами, и др.
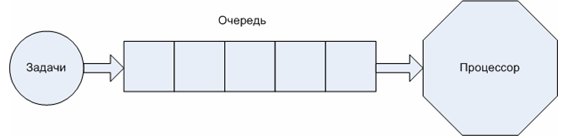
В рамках однопроцессорной вычислительной системы обычно используются следующие классические дисциплины планирования:
-
LIFO - очередь задач (стек) (Last In, First Out)
Варианты LIFO и FIFO иллюстрируют статическое планирование исполнения процессов в однопроцессорной системе под управлением операционной системы с монопольным доступом к процессору (операционная система без вытеснения процесса).
-
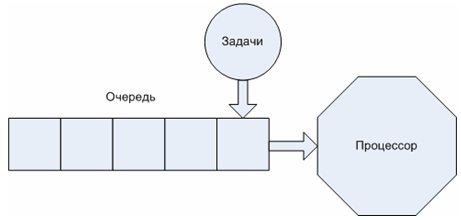
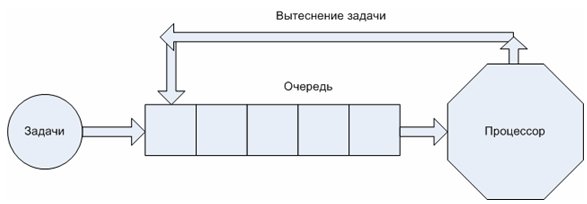
Круговое обслуживание задач на базе FIFO очереди
Данный вариант иллюстрирует принцип работы планировщика однопроцессорной системы с вытеснением процессов, зачастую поддерживается сортировка процессов в очереди согласно определенным приоритетам процессов. Принципы назначения или вычисления приоритета процесса определяются типом планировщика.
Перейдем теперь к рассмотрению более сложных дисциплин планирования, применяющихся в многопроцессорных системах и использующих динамическое планирование - т.е. планирование с учетом состояния процессов системы в текущий момент времени.
3.1 Work stealing
Можно выделить два подхода к планированию исполнения процессов в многопроцессорных системах:
- Work Sharing - централизованное планирование, при котором планировщик контролирует единый пул задач в системе и назначает задачи процессорам;
- Work Stealing - децентрализованное планирование, при котором единый планировщик отсутствует, а процессоры сами выбирают какие задачи им исполнять;
Ниже описывается алгоритм, который используется в планировщике библиотеки PFX, и в основе которого лежит идея заимствования работ (work stealing, коротко WS).
Идея WS-планирования заключается в том, что каждый процессор имеет собственный пул потоков, которые он должен исполнить. При наличии в пуле потоков, процессор изымает один из потоков и начинает исполнять его. Как только пул процессора оказывается пуст, процессор становиться "вором" и крадет (steal) потоки из пулов других процессоров.
Пул потоков процессора представляет собой двустороннюю очередь (часто называемую WS-deque). Для того чтобы начать исполнять следующий поток из пула, процессор извлекает поток с одной стороны очереди - будем называть этот конец очереди bottom. После извлечения потока, процессор исполняет поток до тех пор, пока поток не завершится или исполнение потока не будет блокировано каким-то внешним событием. В этом случае процессор извлекает новый поток из bottom, а блокированный поток помещает назад в bottom. Таким образом, пока очередь не пуста, процессор работает с ней по принципу LIFO (по принципу стека).
В том случае, когда в очереди процессора нет потоков, он произвольно выбирает другой процессор и извлекает из очереди этого процессора поток с противоположной от bottom стороны (назовем ее top ). Если же очередь другого процессора также пуста, то процессор-вор ищет другую "жертву".
Дополнительные сведения о планировании исполнения процессов будут приведены в "Программирование с использованием Task Parallel Library (TPL)" .
Максим Полищук