



|
поддерживаю выше заданые вопросы
|
Нижегородский государственный университет им. Н.И.Лобачевского
Опубликован: 02.10.2012 | Доступ: свободный | Студентов: 1770 / 204 | Длительность: 17:47:00
Специальности: Программист
Лекция 2:
Архитектурные аспекты параллелизма
Модели многопоточных процессоров
Модели многопоточного процессора, который может выдавать до, например, восьми инструкций за такт, отличаются способами использования слотов выдачи и функциональных устройств.
Модель Fine-Grain Multithreading – классическая тонкая многопоточность, скрывающая все источники вертикальных потерь, но не горизонтальных. Только один поток выдает инструкции каждый такт, зато может использовать всю ширину выдачи процессора.
Модель SM: Limited Connection – ограниченные связи в конвейере. Каждый аппаратный контекст напрямую соединен только с некоторыми функциональными устройствами. Например, если аппаратура поддерживает восемь потоков и имеет четыре целочисленных устройства, каждое целочисленное устройство может получать инструкции в точности от двух потоков. Разбиение функциональных устройств по потокам в результате менее динамично, чем в других SMT моделях, но каждое функциональное устройство разделяемо (критический фактор при достижении высокой утилизации ресурсов).
Модели SM: Single/Dual/Four Issue. В этих трех моделях ограничивается количество инструкций, которое каждый поток может выдать или иметь активными в окне планирования на каждом такте. Например, в SM: Dual Issue каждый поток может выдать максимум две инструкции за такт, и потребуется минимум четыре потока для заполнения восьми слотов выдачи в одном такте.
Модель SM: Full Simultaneous Issue – полностью одновременная выдача – самая гибкая модель суперскалярного процессора с конвейерной многопоточностью. Все восемь потоков конкурируют за каждый из восьми слотов выдачи каждый такт. Наивысшая сложность аппаратной реализации.
В [5] произведено количественное сравнение производительности этих моделей (рис.2.10).
Стратегии планирования выборки инструкций
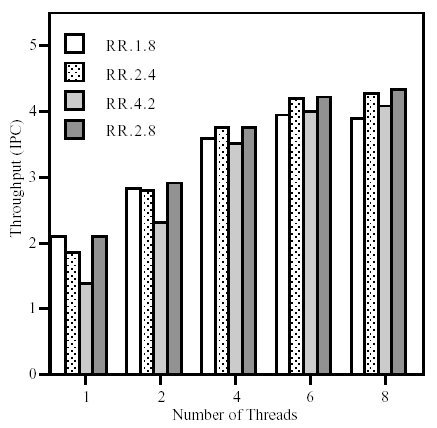
Стратегия Round Robin – выборка по регулярному графику. Например, в RR 1.8 каждый такт из одного потока выбирается до восьми инструкций, а в RR 2.4 каждый такт из двух потоков выбирается до четырех инструкций.
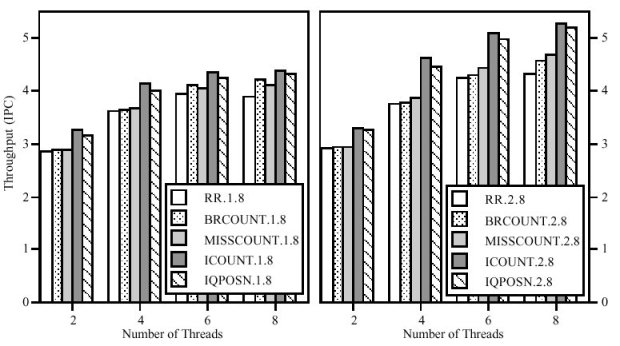
Стратегия BR-Count. Наивысший приоритет у потоков с наименьшей вероятностью ложной спекуляции исполнения (с наименьшим числом невычисленных переходов).
Стратегия MISS-Count. Наивысший приоритет у потоков с наименьшей частотой промахов в кеше данных.
Стратегия I-Count. Наивысший приоритет у потоков с наименьшим числом инструкций в статической части конвейера (в очереди декодированных инструкций).
В [6] произведено количественное сравнение производительности этих стратегий (рис.2.11 и рис.2.12). Так, например, ICOUNT 2.8 увеличивает производительность по сравнению с RR 2.8 на 23% за счет уменьшения помех в потоке инструкций, выбирая лучшую смесь инструкций.
Пример многопоточного процессора: Sun UltraSPARC Niagara II
- 8 ядер _ 8 потоков
- кеш I уровня кода 16K, данных 8K
- кеш II уровня 4M для каждого ядра
- ядро: 1.4 ГГц, 8 SMT, 65 нм, 11 слоев, 342 мм
Пример многопоточного процессора: IBM Power 6
- 32 ядра _ 2 потока
- кеш I уровня кода 64K, данных 64K
- кеш II уровня 8M для каждого ядра
- кеш III уровня 32M (16-входовый)
- ядро: 4.7 ГГц, 2 SMT, 65 нм, 10 слоев, 341 мм
Пример MPP системы: IBM BlueGene/L
- всего 131072 процессора
- производительность 400 TFLOPS
- узлы IBM PowerPC 440 – 2 _ 0.7 ГГц, 5.6 GFLOPS
- 3D Torus network: 2.1 Gb/s
- площадь: 1225 м
- энергопотребление: 1.7 МВатт
Пример MPP системы: IBM BlueGene/P
- всего 294912 процессора
- производительность 1 PFLOPS
- узлы IBM PowerPC 450 – 4 _ 0.85 ГГц, 13.9 GFLOPS
- 3D Torus network: 5.1 Gb/s
- площадь: 1728 м
- энергопотребление: 2.3 МВатт
Эра Multicore и коррекция тенденций развития
2007 год оказался революционным в процессоростроении: теперь на рынке нет серверов с одноядерными микропроцессорами. Началась эра многоядерного процессоростроения. Процессоры штурмуют TeraFLOP-ный рубеж, а MPP системы – PetaFLOP-ный рубеж [8].
До эры Multicore вычислительная техника развивалась согласно известным трендам, называемыми законами Мура [1]:
- удвоение плотности элементов процессорных СБИС каждые два года,
- удвоение частоты процессорных СБИС каждые два года,
- удвоение количества элементов запоминающих СБИС каждые полтора года,
- двукратное уменьшение времени доступа запоминающих СБИС каждые десять лет,
- удвоение емкости внешней памяти каждый год,
- двукратное уменьшение времени доступа во внешней памяти каждые десять лет,
- удвоение скорости передачи данных в глобальных сетях каждый год.
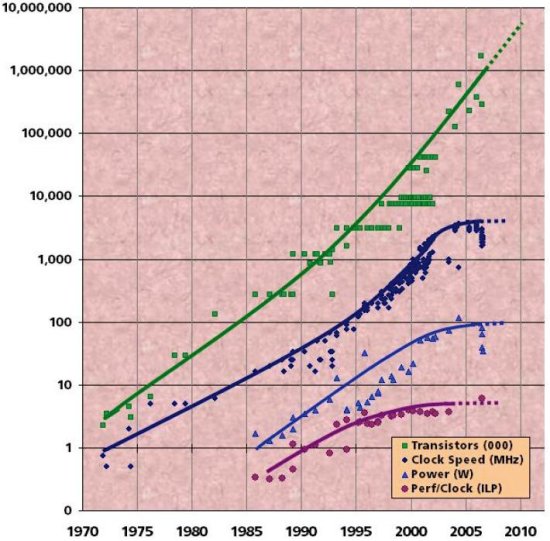
Однако 15 лет экспоненциального роста тактовой частоты закончились [7].
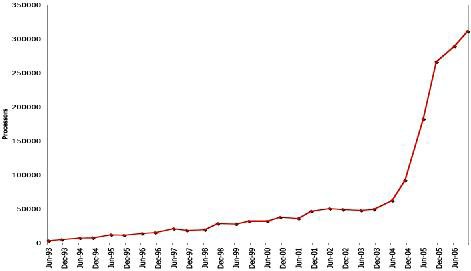
Энергопотребление удалось стабилизировать. ILP достиг предела. Хотя экспоненциальный рост числа транзисторов сохраняется (рис. 2.13).
Таким образом, традиционные источники повышения производительности (тактовая частота, IPC) стабилизировались. Теперь работает новый закон Мура: число ядер удваивается каждые 18 месяцев (вместо удвоения частоты). То есть, по сути, процессор стал новым транзистором!
Энергопотребление мультипроцессоров тесно связано с их производительностью [9] (рис. 2.14).
Малые ядра
В настоящее время у передовых процессоров со сложными ядрами сложилось несколько ключевых проблем: жесткие ограничения по энергопотреблению, драматичное падение темпов роста производительности, крайне сложное тестирование работоспособности.
Назовем малыми ядрами упрощенные ядра с короткими конвейерами и упорядоченной обработкой на небольших частотах.
Оказывается, малые ядра избавлены от проблем передовых ядер: они имеют меньшее энергопотребление и их легче проверять. Кроме того, малые ядра не на много медленнее больших, а на чипе их может быть существенно больше.
Новое понятие вычислительной эффективности
Передовые MPP системы потребляют мегаватты энергии! Стоимость энергии больше стоимости оборудования! Энергопотребление ограничивает будущий рост систем. Поэтому актуально введение нового понятия вычислительной эффективности: performance/watt (вместо пиковой производительности).
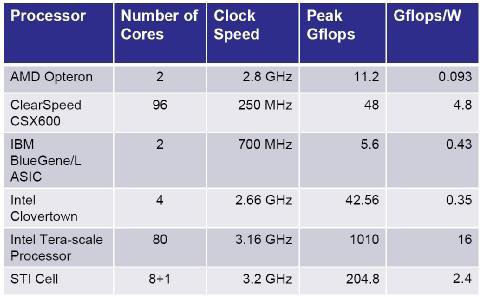
Сравнительный анализ современных многоядерных процессоров различных производителей (рис. 2.16) демонстрирует преимущество процессоров, построенных на малых ядрах. Именно такие процессоры достигают большей вычислительной эффективности в пересчете на один ватт затраченной энергии.
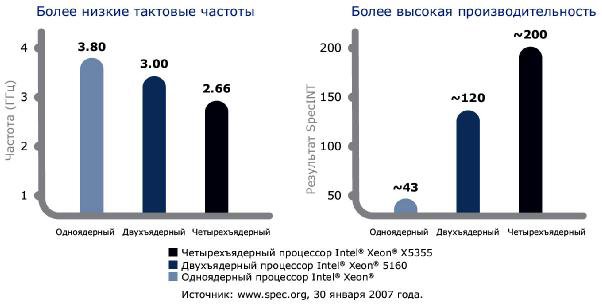
Таким образом, сравнение процессоров по шкале FLOPS уходит в прошлое (так же как и по MIPS и тем более по тактовой частоте). Например, компания Intel в линейке многоядерных процессоров Xeon ориентируется на новую шкалу вычислительной эффективности (рис. 2.17 и 2.18).
Переход от Multicore к Manycore
Итак, Multicore процессоры (например, Intel Core2 Duo) используют прогрессивные ядра (архитектуры) и ориентированы на типичную вычислительную нагрузку (workload). Согласно новому закону Мура число ядер на таких процессорах будет удваиваться каждые 18 месяцев. Имея хорошую характеристику пиковой производительности, Multicore процессоры уступают Manycore процессорам с точки зрения энергоэффективности.
Manycore процессоры (например, Nvidia G80 (128 cores), Intel Polaris (80 cores), Cisco/Tensilica Metro (188 cores)), напротив, используют упрощенные ядра (короткие конвейеры, небольшие частоты, in-order обработка). Согласно новому закону Мура число ядер на таких процессорах также будет удваиваться каждые 18 месяцев. Преимущества Manycore процессоров: наилучшая вычислительная эффективность на ватт, простое тестирование, низкая вероятность дефектов производства, малая стоимость разработки.
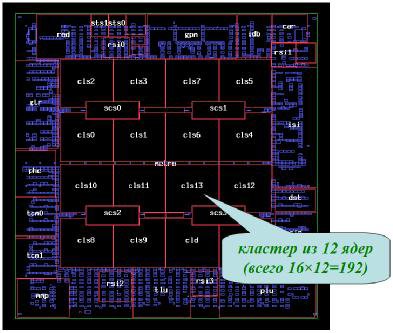
На рис. 2.19 приведен пример 192-х ядерного процессора Tensilica Xtensa, используемого в Cisco CRS-1 Terabit Router. 188 ядер общего назначения доступны для программного обеспечения. На случай выхода их из строя аппаратно зарезервированы еще четыре ядра.
Препятствия на пути многоядерных и многопроцессорных систем
Согласно [7] совсем скоро будет преодолен рубеж в один миллион ядер в системе. Однако на пути развития многоядерных и многопроцессорных систем имеется ряд проблем.
Во-первых, обеспечение баланса системы. Традиционная проблема SMP систем – доступ к RAM. Полоса пропускания RAM – ключевой ограничивающий фактор числа ядер в SMP серверах. Эффективность же массивно-параллельных и кластерных систем ограничена пропускной способностью сети передачи данных.
Во-вторых, обеспечение надежности системы. Чем больше ядер, тем больше вероятность отказов (надежность пропорциональна числу чипов в системе).
В-третьих, обеспечение программной поддержки. Software отстал от hardware. В настоящее время для системы с миллионом ядер нет ни эффективных операционных систем, ни эффективных языков программирования. Прикладного программного обеспечения крайне мало.
Необходимо создать ОС нового типа: не с временным, а с пространственным мультиплексированием; с симметричным доступом не только к памяти, но и к устройствам ввода/вывода; с новым многоядерным механизмом прерываний; с новым механизмом обеспечения отказоустойчивости по ядрам.
Последовательные программы теперь стали медленными программами! Ни SMP, ни OpenMP модели программирования не поддерживают потенциал сцепленных ядер. Программирование необходимо изобрести заново.
Павел Каширин
|
Скачал архив и незнаю как ничать изучать материал. Видео не воспроизводится (скачено очень много кодеков, различных плееров -- никакого эффекта. Максимум видно часть изображения без звука). При старте ReplayMeeting и Start в браузерах google chrome, ie возникает script error с невнятным описанием. В firefox ситуация еще интереснее. Выводится: Meet Now: Кукаева Светлана Александровна. Meeting Start Time: 09.10.2012, 16:58:04 Downloading... Your Web browser is not configured to play Windows Media audio/video files. Make sure the features are enabled and available.
|