|
Символы кириллицы выводит некорректно. Как сделать чтобы выводился читабельный текст на русском языке? Тип приложения - не Qt, Qt Creator 4.5.0 основан на Qt 5.10.0. Win7.
|
Компания ALT Linux
Опубликован: 07.03.2015 | Доступ: свободный | Студентов: 2215 / 538 | Длительность: 24:14:00
Тема: Программирование
Специальности: Программист, Архитектор программного обеспечения
Лекция 10:
Объектно-ориентированное программирование
10.4.6 Пример иерархии классов — библиотека потокового ввода-вывода
В заключение рассмотрим, как используется наследование для решения реальных задач программирования.
Технологии наследования классов, входящие в стандарт C++, предсказуемо были использованы и при разработке библиотек, входящих в стандарт этого языка. Включённая в стандарт реализация сама по себе является прекрасным примером, т. к. в данном случае не приходится сомневаться в грамотном и целесообразном проектировании как иерархии классов, так и их внутренней реализации. По этой причине рассмотрим в качестве примера сложной структуры классов, созданных для решения конкретных практических задач, объектно- ориентированную библиотеку потокового ввода-вывода.
В предыдущих разделах мы касались использования операторов << и >> вместе с объектами cin и cout, а также отметили, что эти объекты на самом деле являются экземплярами классов istream и ostream. Однако прежде чем рассматривать внутреннее устройство этих и других классов, вовлечённых в реализацию ввода-вывода, необходимо разобраться в самой предметной области. Поэтому рассмотрим подробнее, какие стадии включает в себя принятая в C++ кросс-платформенная реализация ввода-вывода.
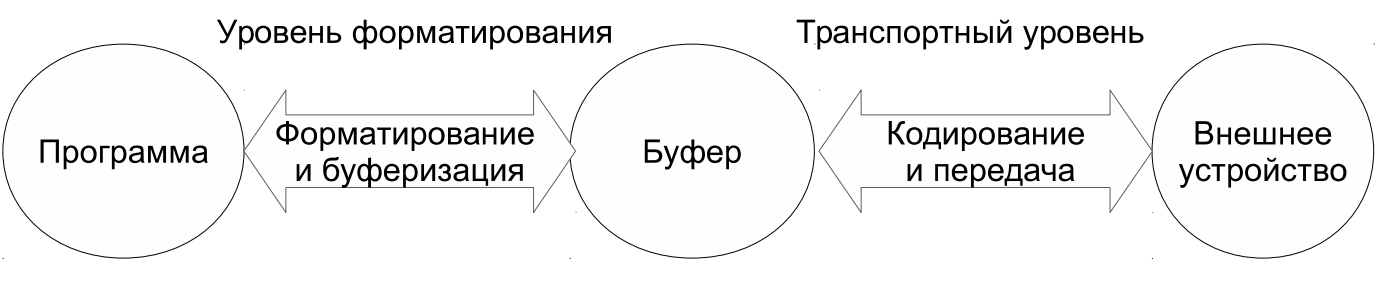
При разработке средств потокового ввода-вывода в C++ была использована следующая двухуровневая модель (см. рис. 10.3), предназначенная для передачи символьных данных между программой и каким-либо внешним устройством.
При этом представление данных в программе и на внешнем устройстве может отличаться: по необходимости данные могут отображаться в форме, удобной для восприятия человеком, либо преобразовываться в какой-либо формат обмена данными. Как видно из рисунка, собственно обработка текстовых данных выполняется на двух уровнях: форматирования и транспортном. Под форматированием понимается преобразование внутренних данных программы в человекочитаемую последовательность символов. Например, значение целочисленной или вещественной переменной на этом этапе должно быть преобразовано в последовательность цифр, а управляющие символы в строковых данных должны быть заменены соответствующими им символьными последовательностями (например, код табуляции "\t" превращается в заданное число пробелов). Под кодированием понимается трансляция из одной кодировки символов в другую. Например, транспортный уровень может выполнять преобразование символов в кодировку Unicode для их использования за пределами программы (данная кодировка является стандартом де-факто, но неудобна для непосредственного использования в программе, т. к. символы разных языков имеют в ней различное количество байт).
В рамках двухуровневой модели ввода-вывода, принятой в C++, уровень форматирования делает возможным выполнение следующих процедур:
- преобразование вещественных значений в последовательность цифр с заданной точностью и формой представления;
- преобразование целочисленных значений в последовательность цифр в шестнадцатеричной, восьмеричной либо десятичной системе счисления;
- исключение лишних пробелов из входных данных;
- задание ширины поля (т. е. максимального количества знаков) для выводимых данных;
- адаптация представления чисел к конкретной локали (т. е. учёт национальной специфики их отображения).
Транспортный уровень отвечает непосредственно за получение и выдачу символов. На этом уровне инкапсулируется специфика конкретных внешних устройств. К числу таковых помимо возможности преобразования в многобайтные кодировки относится также блочный вывод в файлы с использованием системных вызовов операционной системы, под которую компилируется программа.
Для уменьшения числа обращений к внешнему устройству используется потоковый буфер. При выводе последовательность символов после форматирования попадает в потоковый буфер, а реальная передача данных внешнему устройству выполняется когда буфер оказывается заполнен, или когда принудительно вызвана операция опустошения буфера. При вводе данных транспортный уровень считывает последовательность символов из внешнего устройства в буфер, после чего уровень форматирования извлекает данные из буфера. Когда буфер оказывается пуст, задачей транспортного уровня является его повторное наполнение данными.
Реализованный в C++ форматированный потоковый ввод-вывод можно разделить на две группы: файловый ввод-вывод и ввод-вывод в памяти. Файловый ввод-вывод предполагает передачу данных между программой и внешним устройством. При этом внешнее устройство только представлено файлом; помимо обычного файла на диске оно может в действительности быть каналом обмена данными или любым реальным устройством, файловая абстракция которого реализована в операционной системе.
Ввод-вывод в памяти в действительности не задействует никакого внешнего устройства. Благодаря этому отпадает необходимость в уровне кодирования и передачи, а уровень форматирования просто формирует строку символов.
Расширяемость библиотеки потокового ввода-вывода позволяет программисту добавлять свои элементы на любом из её уровней. Например, операторы ввода-вывода могут быть перегружены для новых типов данных, программист может создавать собственные элементы, управляющие форматированием (т. н. манипуляторы). Можно создавать собственные локали для специфического представления чисел и т. д.
Теперь мы можем рассмотреть, как выглядит иерархия классов потокового ввода-вывода с точки зрения программиста.
Мы будем рассматривать упрощённое представление для случая, когда символы представлены в программе в однобайтной кодировке с использованием типа char. В реальности библиотека iostream реализует более универсальное представление данных на основе шаблонов, позволяющее не указывать заранее при описании классов тип данных, используемый для хранения символа. Благодаря этому подходу тот же самый код может применяться, например, для многобайтных кодировок, представленных специальным типом wchar_t. Также мы на данном этапе опустим специальные средства обработки ошибок и других исключительных ситуаций, применённые в данной библиотеке. Подробнее о шаблонах и обработке исключительных ситуаций можно будет узнать в следующих разделах; там же будут пояснены опущенные на данном этапе элементы, и в т. ч. то, как на самом деле объявлены типы библиотеки iostream.
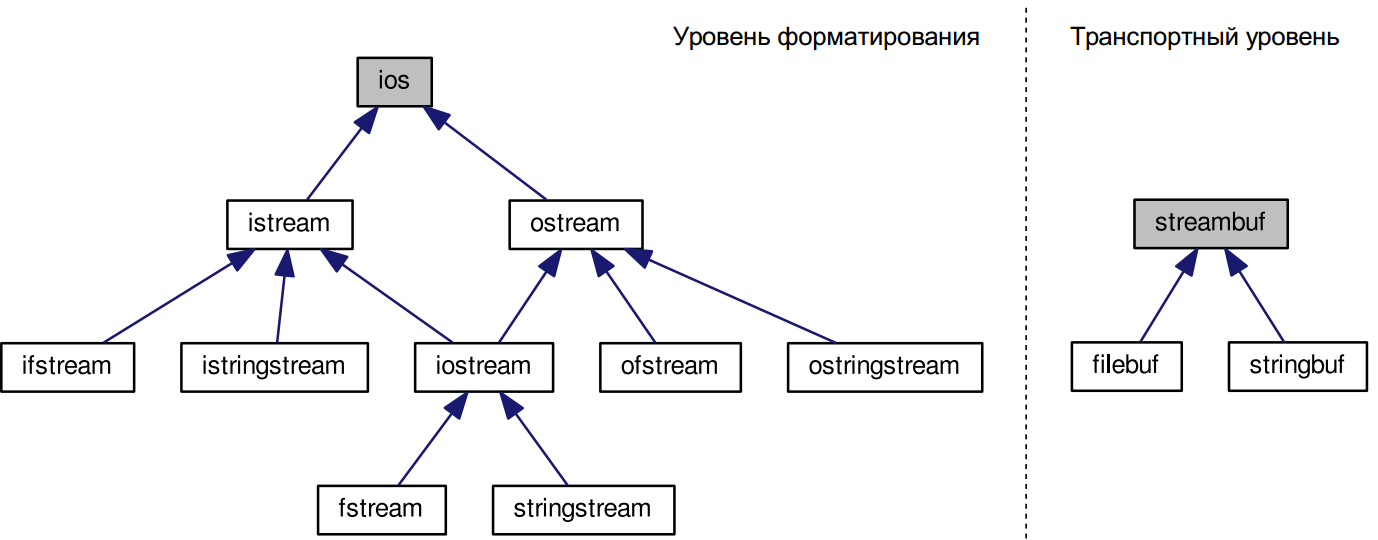
Пока достаточно знать, что иерархия классов iostream выглядит для программиста, использующего обычные символы типа char, следующим образом (см. рис. 10.4).
Из приведённой иерархии можно заметить, что структура классов уровня форматирования заметно более разветвлённая, хотя основные отличия между файловыми потоками и потоками в памяти кроются на транспортном уровне. Кажущийся дисбаланс легко объясним, если вспомнить, что программист, пользующийся библиотекой iostream, непосредственно взаимодействует в основном с уровнем форматирования. Использование универсальных классов, которые после существенной предварительной настройки выполняли бы ввод-вывод с любыми объектами транспортного уровня, менее удобно, чем специализированные классы для каждого типа ввода-вывода, не требующие или почти не требующие настройки для выполнения требуемых операций.
Будучи базовым для всех потоковых классов уровня форматирования, класс ios содержит информацию, присущую любым потокам: управляющую информацию для разбора и форматирования, возможности для расширения иерархии собственными потоками пользователя, а также локали. Здесь же объявляются некоторые типы, используемые остальными классами: флаги форматирования, биты состояния, режим открытия и т. д. Здесь же содержится указатель на потоковый буфер (который в свою очередь включает собственно символьный буфер и служебную информацию, отражающую состояние буфера и обеспечивающую целостность информации).
Как читатель успел заметить из собственной практики программирования на C++, активнее всего потоки используются для стандартного ввода-вывода (т. е. ввода с клавиатуры и вывода на дисплей). Для обработки стандартного ввода предусмотрен класс istream, а для обработки стандартного вывода — ostream; оба класса наследуются от ios, приобретая благодаря этому всю специфику, связанную с форматированием, и указатель на потоковый буфер. Для взаимодействия с потоковым буфером в классе istream объявлен перегруженный оператор потокового ввода >>, а в классе ostream — перегруженный оператор потокового вывода <<. Для возможности неформатированного ввода и вывода в этих классах объявлен также ряд методов — таких как read() и write(). Наконец, для случаев, когда необходим двунаправленный ввод-вывод (по аналогии с тем, как файл может открываться одновременно для чтения и записи) с помощью множественного наследования от этих двух классов порождён класс iostream, автоматически приобретающий свойства как входных, так и выходных потоков и используемый как базовый для классов, в которых двунаправленный ввод-вывод действительно востребован.
Строковые потоки, осуществляющие ввод-вывод в памяти, представлены классами istringstream и ostringtstream, порождёнными соответственно от istream и ostream, а также универсальным классом двунаправленного ввода- вывода stringtream, порождённым от iostream. Эти классы включают функции (геттеры и сеттеры) для использования строки в качестве буфера.
Файловый ввод-вывод осуществляют классы ifstream и oftstream, порождённые соответственно от istream и ostream, а также универсальный класс fstream, порождённый от iostream. Эти классы содержат методы для открытия и закрытия файлов, аналогичные функциям fopen() и fclose() языка С.
Очевидно, что значительная часть различий между стандартным вводом- выводом, файловыми и строковыми потоками скрыта на транспортном уровне.
Базовый класс streambuffer олицетворяет собой универсальный потоковый буфер. Будучи абстрактным классом, он не содержит в себе специфики конкретных оконечных устройств; однако в нём объявлены две чисто виртуальные функции: overflow() и underflow(), которые должны быть перегружены в производных классах, чтобы выполнять действительную передачу символов между символьным буфером и конкретными оконечными устройствами.
Класс потокового буфера поддерживает две символьные последовательности: область получения (get), представляющую последовательность символов, получаемых из оконечного устройства, и область выдачи (put), т. е. выходную последовательность для записи на устройство. Также в классе предусмотрены функции, извлекающие очередной символ из буфера (sgetc() и т. д.) и помещающие очередной символ в буфер (sputc() и т. д.), которые обычно используются уровнем форматирования. Дополнительно потоковый буфер содержит также объект локали.
Производный от streambuf класс filebuf используется для работы с файлами и содержит для этого ряд функций, таких как open() и close(). Он также наследует объект локали от базового класса для перекодирования между внешней и внутренней кодировками (например, как уже упоминалось, между кодировкой Unicode и внутренним представлением мультиязычных символов значениями типа wchar_t).
Класс stringbuf также является производным от streambuf. Поскольку он предназначен для работы со строками, внутренний буфер одновременно является и оконечным устройством. По мере необходимости внутренний буфер может динамически изменять свой размер, чтобы принять все записанные в него символы. Класс позволяет получить копию внутреннего буфера, а также скопировать в него строку.
Взаимодействие между уровнем форматирования и транспортным уровнем осуществляется следующим образом. Класс ios, как мы уже упоминали, содержит в себе указатель на потоковый буфер. В производных от него классах (таких как fstream или stringstream) содержатся указатели на объекты соответствующих классов транспортного уровня (filebuf или stringbuf). Классы транспортного уровня можно также использовать и непосредственно, для неформатированного ввода-вывода — точно так же, как их использует уровень форматирования.
Представленная на рисунке иерархия могла бы быть описана следующим образом:
class ios {...};
class ostream : public ios {...};
class istream : public ios {...};
class ofstream : public ostream {...};
class ifstream : public istream {...};
class ostringstream : public ostream {...};
class istringstream : public istream {...};
class iostream : public ostream, public istream {...};
class fstream : public iostream {...};
class stringstream : public iostream {...};
Сергей Радыгин
Юрий Герко
|
Кому удалось собрать пример из раздела 13.2 Компоновка (Layouts)? Если создавать проект по изложенному алгоритму, автоматически не создается файл mainwindow.cpp. Если создавать этот файл вручную и добавлять в проект, сборка не получается - компилятор сообщает об отсутствии класса MainWindow. Как правильно выполнить пример? |