
|
Добрый день!
Скажите, пожалуйста,планируется ли продолжение курсов по нанотехнологиям? Спасибо, Евгений
|
Опубликован: 01.10.2013 | Доступ: свободный | Студентов: 259 / 23 | Длительность: 24:58:00
ISBN: 978-5-9963-0223-9
Темы: САПР, Аппаратное обеспечение, Нанотехнологии
Специальности: Разработчик аппаратуры
Лекция 9:
Оценка производительности и живучести МКМД-БИТ-потокового предпроцессора системы астронавигации
Модуль контроля правильности работы логических устройств субпроцессора ( ICLM - рис. 8.22) осуществляет циклическое сравнение накопленных сумм в гистограммах первых двух строк обрабатываемого изображения, которые смешаны на входе по "ИЛИ" с потоком тест-данных.
Он осуществляет контроль правильности работы всех логических блоков вплоть до модуля формирования построчных гистограмм включительно, где арифметические действия превалируют над логическими действиями. Модуль ICLM ( см. рис. 8.22) содержит:
- блок управления циклом сравнения (CUICLM), который генерирует циклическую константу вида
 , в которой 8 "единиц", а остальные (214-8) - "нули";
, в которой 8 "единиц", а остальные (214-8) - "нули"; - блок генерации эталонной реакции (SRP) вида
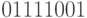 ;
; - блок выделения тестовых строк (SLC), который определяет момент появления на входе тестовой реакции;
- блок сравнения (CMPR), который вырабатывает признак "единица", если произошел сбой или отказ в тракте логической обработки.
Согласно схеме рис. 8.22, модуль ICLM не позволяет контролировать правильность работы входного интерфейса INS16, который работает параллельно до блока выделения тестовых строк SLC. При правильной работе контролируемой части субпроцессора накопленная сумма должна равняться 32, так как каждая из двух тестовых строк должна содержать 16 "единиц", которые отвечают правильной реакции медианного фильтра.
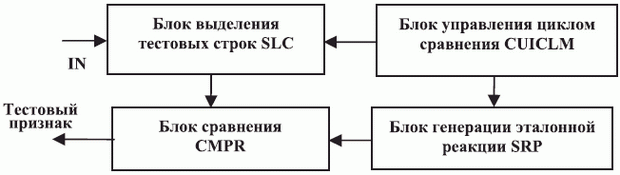
Рис. 8.22. Структурная схема модуля контроля работы логических блоков субпроцессора слежения за "центром масс" факела (ICLM)
Блок управления циклом сравнения CUICLM (БП (3, 1)-(6, 12) рис. 8.23) на выходе (4, 12, 2) периодически генерирует константу вида  , которая открывает доступ эталонному значению (БП (3, 11, 3) в блок сравнения, в котором хранится константа 79 ).
, которая открывает доступ эталонному значению (БП (3, 11, 3) в блок сравнения, в котором хранится константа 79 ).
Блок сравнения занимает бит-матрицу (1, 10)-(2, 13) (см. рис. 8.23). Его функциональный выход имеет координату (2, 13, 4), на котором с задержкой 813 тактов формируется переменная 00000000, если реальная реакция субпроцессора е совпала в БП (2, 10) по XOR с эталонной и 8-битный операнд с обязательной "единицей" в старшем бите - в противном случае. Содержимое этого бита запоминается в БП (3, 13, 3) и служит признаком (не)правильной работы логического тракта субпроцессора слежения за "центром масс" астроориентира.
Правильной работе канала логической обработки отвечает "нулевая" реакция тестового модуля ICLM, а при обнаружении ошибки на этом

Рис. 8.23. Топологическая схема модуля контроля работы логических блоков субпроцессора слежения за "центром масс" астроориентира (ICLM)
выходе начиная с 813-го такта устанавливается "тождественная единица" на всех последующих 214 тактах.
Из приведенных данных видно, что в модуле контроля работы логических блоков ( ICLM ) в одном 214- битном цикле выполняются:
- в блоке управления циклом сравнения (CUICLM): 212 генераций циклической константы
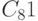 и 213 ее пересылок;
и 213 ее пересылок; - в блоке генерации эталонной реакции (SRP): 211 генераций циклической константы 79 и 211 ее пересылок; 211 операций "И" и 211 "пересылок" результата;
- в блоке выделения реакций на тестовые строки (SLC): 211 операций "И" и 211 "пересылок" результата;
- в блоке сравнения (CMPR): 211 операций "XOR", 214 операций "ИЛИ" с задержкой при формировании признака результата сравнения и 214 "пересылок" результата, 1 214-битная операция запоминания результата сравнения и 1 операция пересылки 214-битного результата сравнения.
Таким образом, пропускная способность модуля контроля работы логических блоков ( ICLM ) по потоку 214-битных слов-инструкций составляет:
![V_{I} = [(2^{12}+2^{13})+(2^{11}+2^{11}+2^{11})+(2^{11}+2^{11})+(2^{11}+2^{14}+1+1)+(8+8)]*F_{t} /8+ [(1+1+1+1+3)]*F_{t} /2^{14} \approx 2^{15}*F_{t} /2^{14} \approx 2 F_{t}.](/sites/default/files/tex_cache/e017aee17e250b2c044e5c02ab84b4d2.png)
Контроль правильности работы арифметических каналов субпроцессора ( CAM ) осуществляется по классической фон-неймановской схеме двойного резервирования, которая гарантирует темп реального времени для задачи стопроцентного обнаружения одиночных отказов.
Поэтому, несмотря на большие аппаратные затраты, каналы из арифметических модулей SMM и CMM продублированы, а их выходы объединены тестовым модулем сравнения по XOR с последующим выделением признака результата сравнения, принимающим значение "ноль", если в субпроцессоре отсутствуют функционально значимые отказы аппаратуры, и значение "единица" в противном случае. Функциональный состав дублирующих модулей SMM d и CMM d идентичен основным, но их топологические схемы все же разнятся в некоторых деталях.
Канал определения центра масс на горизонтальной оси изображения аналогичен по функциям описанному каналу с той разницей, что обрабатываемое изображение подается на его входы в транспонированном виде.
Распределение слов-инструкций по операционным модулям МКМД-бит-потокового субпроцессора приведено в табл. 8.1, из данных которой видно:
- Проблемно-ориентированный субпроцессор слежения за "центром масс" астроориентира состоит из 1 специализированного контроллера ( INS16 ) и 10 специализированных процессоров арифметико-логической обработки: DTM, SWM25, MMF25, CMZ 4(128), LHM, SMM, SMM d, CMM, CMM d, ICLM, в каждом из которых имеется одно или несколько операционных, управляющих и коммутационных устройств, поддерживающих 11 информационно связанных и одновременно протекающих процессов потоковой обработки операндов. При этом составляющие специализированные процессоры сами являются многопроцессорными RISC -подобными системами, имеющими по несколько устройств управления и обработки с постоянными циклами исполнения всех команд и независимыми шинами передачи всех управляющих и информационных потоков. Например, модуль медиа нной фильтрации MMF25 состоит из 8 идентичных процессоров, а модуль свертки SMM - из одного умножителя и двух сумматоров.
- Формат преобразуемых операндов колеблется от 1 до 128 бит, причем количество операций пересылки обрабатываемых и управляющих операндов почти в 5 раз превосходит количество операций, затрачиваемых на управление, и почти в 10 раз - количество операций, затрачиваемых на функциональную обработку потоков данных.
- Максимальный вклад в пропускную способность по потокам исполняемых инструкций и преобразуемых потоков данных вносят модули "скользящего окна" ( SWM25 ) и медианной фильтрации ( MMF25 ), в которых обрабатываются однобитные операнды. Реализация этих поток-операторов представляет проблему и в классических архитектурах, не столько из-за сложности выполняемых преобразований, сколько из-за резкого возрастания интенсивности потоков преобразуемых
и управляющих данных, обеспечивающих циклы "перемещения" "скользящего окна" по кадру изображения. Только задача управления перемещением "скользящего окна" имеет 4 вложенных цикла: модификация индекса строки изображения, модификация индекса столбца изображения, модификация индекса строки "скользящего окна", модификация индекса столбца "скользящего окна". В результате размерность задачи управления скольжением по исходному изображению оценивается как
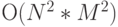 , где
, где  и
и  - линейные размеры изображения и "скользящего окна" соответственно.
- линейные размеры изображения и "скользящего окна" соответственно.
| Тип Тип блока и Тип Количество слов-инструкций | ||||||
|---|---|---|---|---|---|---|
| модуля | размеры модуля | операнда | ОУ | Управление | Пересылки | Итого |
| INS16 | ICU1(16) | 8, 16 бит | - | 3 | 2 | 5 |
| INNS16 | 16 бит | 1 1 - | - 3 1 | 17 19 2 | 18 | |
| 3 18=54 БП | 8, 16 бит | 23 | ||||
| DTM | NG | 8 бит | 3 | |||
| SG | 8 бит | - | 1 | 1 | 2 | |
| CG | 8 бит | - | 5 | 6 | 11 | |
| TG | 8 бит | 2 | - | 2 | 4 | |
| ASU | 8 бит | 2 4 - - 25*8=120 2*8=16 136 - | - 7 - 26*8=208 - - 208 1 | 3 14 542 54*8=432 50*8=400 2*8=16 848 2 | 5 | |
| 3*24=72 БП | 8 бит | 25 | ||||
| SWM25 | 6*25=150 БП | 1 бит | 542 | |||
| MMF25 | CUADD1(8)) | 8 бит | 640 | |||
| ADD | 1 бит | 520 | ||||
| THU | 8 бит | 32 | ||||
| 3*8*28=672 БП | 1, 8 бит | 1192 | ||||
| CMZ 4(128) | NG | 8бит | 3 | |||
| CG | 8бит | - | 1 | 1 | 2 | |
| SG | 8бит | - | 1 | 3 | 4 | |
| AND | 8бит | 1 | - | 3 | 4 | |
| LHM | ADDA | 2-16 бит | 15 | 4 | 30 10 9 | 49 |
| CADDA16(128) | 8, 16 бит | - | 7 | 17 | ||
| DWH | 16 бит | 1 | - | 10 | ||
| SMM | 4*28=112 БП ML | 2-16 бит 128 бит | 16 1 | 11 1 | 49 1 | 76 3 |
| WGU | 16,128 бит | 1 | 1 | 1 | 3 | |
| CCU1(128) | 8,128 бит | - | 20 | 68 | 88 | |
| ADDRV32 | 128 бит | 3 | - | 3 | 6 | |
| CADDR32 | 8, 32, 128 бит | - | 28 | 48 | 76 | |
| ADDRH32 | 128 бит | 3 | - | 3 | 6 | |
| DWHCU | 128 бит | 1 9 9 | - 50 50 | 1 125 125 | 2 | |
| 24*13=312 БП | 8, 32, 128 бит | 184 | ||||
| SMM_{d} | 24*13=312 БП | 8, 32, 128 бит | 184 | |||
| CMM | DL | 32 бита 1 - | 1 | 2 | ||
| DCC | 32 бита 2 - | 1 | 3 | |||
| CG | 8, 32 бит | -5 35 3 | 3 5 5 1 | 8 | ||
| 8*62=496 БП | 8, 32 бит | 13 | ||||
| CMM_{d} | 8*62=496 БП | 8, 32 бит | 13 | |||
| ICLM | CUICLM | 8 бит | - | 1 | 2 | |
| SRP | 8 бит | - | 2 | 2 | 4 | |
| SLC | 8-1 1 | 2 | ||||
| CMPR | 1 кадр | 10 | - | 10 14 1755 | 20 | |
| 6*13=78 БП 2776 БП | 8 бит, 1 кадр | 10 4 | 28 | |||
| Итого | 192 346 | 2293 | ||||
На основе приведенных данных можно утверждать:
- Задача слежения за "центром масс" астроориентира содержит достаточно богатую смесь МКМД-бит-потоковых арифметико-логических, интерфейсных, управляющих и диагностических процедур как по форматам и разрядности операндов, так и по алгоритмам их реализации. Поэтому ее можно рассматривать как представительную смесь при анализе потребительских характеристик МКМД-бит-потоковых субпроцессоров.
- Чем выше коэффициент распараллеливания вычислений по потоку команд, тем ближе параллельные (Б)ВС к работе в режиме интерпретации, а не трансляции (компиляции) исполняемых программ, так как в этом случае все большему числу процессоров необходимо задать параметры настройки исполняемых команд и преобразуемых ими данных.
- В МКМД-бит-потоковых субпроцессорных трактах достаточно просто сопрягается обработка данных разного формата и разной разрядности при сохранении общего темпа поступления входного потока, который регламентируется теоремой Котельникова. Этот эффект достигается не только за счет глубокой конвейеризации по потоку команд, но и за счет векторизации по потоку данных.
Наиболее четко данный эффект проявился в модулях "скользящего окна" и медианной фильтрации, в первом из которых коэффициент векторизации должен равняться "площади скользящего окна" (в данном случае она равна 25 пикселям), а во втором этот коэффициент возрастает почти в 4 раза за счет векторно-конвейерной обработки в 8 блоках суммирования. В этом и только в этом случае можно выровнять темпы поступления потока входных данных и их обработки в макроконвейере, содержащем 12 специализированных процессоров.
- Разрядность операндов нарастает по мере приближения к выходу субпроцессора, а фактическая (пользовательская) интенсивность использования оборудования при этом падает практически до нуля, как это имеет место в делителе, который с учетом дублирующего модуля занимает бит-матрицу 16*62 = 992 БП, что составляет 33,6 % от общего размера бит-матрицы 44*67 = 2948 БП.
Основной вклад в аппаратные затраты и в повышение пропускной способности (производительности) МКМД-бит-потоковых субпроцессоров вносят массовые операции управления и (сверх)массо-вые пересылки управляющих и преобразуемых операндов, которые составляют соответственно 15,1 % и 76,54 %, в то время как арифметико-логические операции составляют всего лишь 8,36 % от общего количества операций (см. табл. 8.1).
- Управление МКМД-бит-потоковыми субпроцессорами в основном сводится к организации работы различного рода таймеров, что больше свойственно процессорам, ориентированным на задачи управления устройствами электро- и радиоавтоматики, а не арифметико-логической обработки потоков данных.
Евгений Акимов