

|
Здравствуйте прошла курсы на тему Алгоритмы С++. Но не пришел сертификат и не доступен.Где и как можно его скаачат? |
Инспектор
Вы можете этот курс.
Опубликован: 05.01.2015 | Доступ: платный | Студентов: 56 / 0 | Длительность: 63:16:00
Специальности: Программист, Системный архитектор, Тестировщик, Архитектор программного обеспечения
Лекция 7:
Быстрая сортировка
Аннотация: Рассмотрен алгоритм быстрой сортировки и примеры его реализации и использования.
Ключевые слова: алгоритм, quicksort, быстрая сортировка, стек, производительность, анализ, программа, утилита, время выполнения, приложение, сортировка
Темой настоящей главы является алгоритм сортировки, который, возможно, используется гораздо чаще любых других - алгоритм быстрой сортировки (quicksort). Первоначальный вариант этого алгоритма был изобретен в 1960 г. Ч. Хоаром (C.A.R. Hoare) и с той поры исследовался многими специалистами (см. раздел ссылок). Быстрая сортировка популярна прежде всего потому, что ее нетрудно реализовать, она хорошо работает на различных видах входных данных и во многих случаях требует меньше ресурсов по сравнению с другими методами сортировки.
Алгоритм быстрой сортировки обладает и другими привлекательными особенностями: он принадлежит к категории обменных сортировок (использует лишь небольшой вспомогательный стек), на упорядочение N элементов в среднем затрачивает время, пропорциональное N log N, и имеет исключительно короткий внутренний цикл. Его недостатком является то, что он неустойчив, выполняет в худшем случае N 2 операций и ненадежен в том смысле, что простая ошибка в реализации может остаться незамеченной, но существенно понизить производительность на некоторых видах файлов.
Работа быстрой сортировки проста для понимания. Алгоритм был подвергнут тщательному математическому анализу, и существуют точные оценки его эффективности. Этот анализ был подтвержден обширными эмпирическими экспериментами, а сам алгоритм отшлифован до такой степени, что ему отдается предпочтение в широком диапазоне практических применений сортировки. Поэтому эффективной реализации алгоритма быстрой сортировки стоит уделить гораздо большее внимание, чем реализациям других алгоритмов. Аналогичные методы реализации пригодны и для других алгоритмов; но для быстрой сортировки их можно применять с полной уверенностью, поскольку точно известно их влияние на эффективность сортировки.
Многие пытаются разработать способы улучшения быстрой сортировки: ускорение алгоритмов сортировки играет роль "изобретения велосипеда" в компьютерных науках, а быстрая сортировка представляет собой почтенный метод, который так и хочется улучшить. Его усовершенствованные версии стали появляться в литературе практически с момента опубликования Хоаром. Предлагалось и анализировалось множество идей, но при оценке этих улучшений легко ошибиться, поскольку данный алгоритм настолько удачно сбалансирован, что небольшое усовершенствование одной части программы может привести к резкому ухудшению работы другой ее части. Мы подробно изучим три модификации, которые существенно повышают эффективность быстрой сортировки.
Тщательно настроенная версия быстрой сортировки обычно работает быстрее любого другого метода сортировки на большинстве компьютеров, поэтому быстрая сортировка широко используется как библиотечная программа сортировки и в других серьезных приложениях сортировки. Утилита сортировки из стандартной библиотеки С++ называется qsort, т.к. ее различные реализации обычно основаны на алгоритме быстрой сортировки. Однако время выполнения быстрой сортировки зависит от организации входных данных и колеблется между линейной и квадратичной зависимостью от количества сортируемых элементов, и пользователи иногда бывают неприятно удивлены неожиданно неудовлетворительной работой сортировки на некоторых видах входных данных, особенно при использовании хорошо отлаженных версий этого алгоритма. Если приложение работает настолько плохо, что возникает подозрение в наличии дефектов в реализации быстрой сортировки, то более надежным выбором может оказаться сортировка Шелла, хорошо работающая при меньших затратах на реализацию. Однако в случае особо крупных файлов быстрая сортировка обычно выполняется в пять-десять раз быстрее сортировки Шелла, а для некоторых видов файлов, часто встречающихся на практике, ее можно адаптировать для еще большего повышения эффективности.
Базовый алгоритм
Быстрая сортировка функционирует по принципу " разделяй и властвуй " . Она разбивает сортируемый массив на две части, затем сортирует эти части независимо друг от друга. Как будет показано далее, точное положение точки разбиения зависит от первоначального порядка элементов во входном файле. Суть метода заключается в процессе разбиения, который переупорядочивает массив таким образом, что выполняются следующие три условия:
- Элемент a[i] для некоторого i занимает свою окончательную позицию в массиве.
- Ни один из элементов a[i], ..., a[i-1] не является большим a[i].
- Ни один из элементов a[i+1], ..., a[r] не является меньшим a[i].
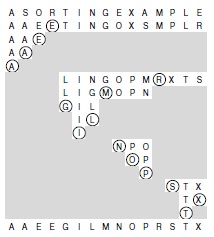
Полная упорядоченность достигается разбиением файла на подфайлы с последующим рекурсивным применением к ним этого же метода (см. рис. 7.1). Поскольку процесс разбиения всегда помещает хотя бы один элемент в окончательную позицию, нетрудно вывести по индукции формальное доказательство того, что этот рекурсивный метод достигает нужного результата. Программа 7.1 содержит рекурсивную реализацию этой идеи.
Быстрая сортировка выполняет процесс рекурсивного разбиения. Вначале некоторый элемент (центральный элемент) помещается на свое место, а остальные элементы переупорядочиваются таким образом, что меньшие элементы находятся слева от центрального элемента, а большие - справа. Затем выполняется рекурсивная сортировка левой и правой частей массива. На этой диаграмме каждая строка отображает результат разбиения показанного подфайла вокруг элемента, обведенного кружком. По завершении процесса получается полностью упорядоченный файл.
Программа 7.1. Быстрая сортировка
Если массив содержит один или ноль элементов, то ничего делать не надо. Иначе массив обрабатывается процедурой partition (см. программу 7.2), которая помещает на свое место элемент a[i] для некоторого i между l и r включительно и переупорядочивает остальные элементы таким образом, что рекурсивные вызовы этой процедуры завершают сортировку.
template <class Item>
void quicksort(Item a[], int l, int r)
{
if (r <= l) return;
int i = partition(a, l, r);
quicksort(a, l, i-1);
quicksort(a, i+1, r);
}
Мы будем использовать следующую общую стратегию реализации разбиения. Сначала в качестве центрального элемента (partitioning element) произвольно выбирается элемент a[r] - тот, который будет помещен в окончательную позицию.
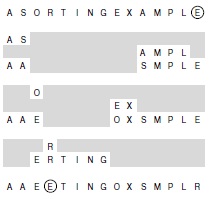
Далее выполняется просмотр с левого конца массива, пока не будет найден элемент, больший центрального, а затем выполняется просмотр с правого конца массива, пока не будет найден элемент, меньший центрального. Два элемента, на которых остановился просмотр, очевидно, находятся не на своих местах в разбитом массиве, и потому они меняются местами. Продолжаем в том же духе, пока не убедимся в том, что ни один элемент слева от левого указателя не больше центрального элемента, и ни один элемент справа от правого указателя не меньше центрального элемента, как показано на следующей диаграмме:
Здесь v - значение центрального элемента, i - левый индекс, а j - правый индекс. Как показано на этой диаграмме, лучше остановить просмотр слева для элементов, больших или равных центральному элементу, и просмотр справа - для элементов, меньших или равных центральному элементу, даже если это правило породит ненужные перестановки с элементами, равными центральному (мы обсудим причины появления этого правила ниже в этом разделе). После перекрещивания индексов все, что остается сделать, чтобы завершить процесс разбиения - это обменять элемент a[r] с крайним левым элементом правого подфайла (элемент, на который указывает левый индекс). Программа 7.2 является реализацией этого процесса, а примеры приведены на рис. 7.2 и рис. 7.3.
Внутренний цикл быстрой сортировки увеличивает индекс на единицу и сравнивает элементы массива с постоянной величиной. Именно эта простота и делает быструю сортировку быстрой: трудно представить себе более короткий внутренний цикл в алгоритме сортировки.
Программа 7.2 использует явную проверку прекращения просмотра, если центральный элемент является наименьшим элементом массива. Чтобы избежать этой проверки, можно использовать сигнальное значение: внутренний цикл быстрой сортировки настолько мал, что даже одна лишняя проверка может оказать заметное влияние на производительность. Сигнальное значение не требуется в данной реализации, если центральный элемент является наибольшим элементом в массиве, т.к. тогда он сам находится на правом краю массива и останавливает просмотр.
Разбиение, выполняемое в процессе быстрой сортировки, начинается с (произвольного) выбора центрального элемента. В программе 7.2 для этого берется самый правый элемент E. Затем слева пропускаются все меньшие элементы, а справа - все большие, выполняется обмен элементов, остановивших просмотр, и т.д. до встречи индексов. Вначале выполняется просмотр массива слева, который останавливается на элементе S, потом выполняется просмотр справа, который останавливается на элементе A, а затем элементы S и A меняются местами. Потом просмотр продолжается: слева - до остановки на элементе O, а справа - на элементе E, после чего O и E меняются местами. После этого индексы просмотра перекрещиваются: просмотр слева останавливается на R, а просмотр справа останавливается на E. Для завершения процесса центральный элемент (левая E) обменивается с R.
Программа 7.2. Разбиение
Переменная v содержит значение центрального элемента a[r], а i и j - соответственно левый и правый индексы просмотра. Цикл разбиения увеличивает i и уменьшает j на 1, соблюдая условие, что ни один элемент слева от i не больше v и ни один элемент справа от j не больше v. После встречи указателей процедура разбиения завершается перестановкой a[r] и a[i], при этом в a[i] заносится значение v, и справа от v не останется меньших его элементов, а слева - больших. Цикл разбиения реализован в виде бесконечного цикла с выходом по break после перекрещивания указателей. Проверка j==1 вставлена на случай, если центральный элемент окажется наименьшим в файле.
template <class Item>
int partition(Item a[], int l, int r)
{ int i = l-1, j = r; Item v = a[r];
for (;;)
{
while (a[++i] < v) ;
while (v < a[-j]) if (j == l) break;
if (i >= j) break;
exch(a[i], a[j]);
}
exch(a[i], a[r]);
return i;
}
Другие реализации разбиения, которые встретятся далее в этом разделе и в ряде мест главы, не обязательно прекращают просмотр на ключах, равных центральному элементу - в таких реализациях, возможно, потребуется добавить проверку индекса, чтобы он не вышел за правую границу массива. А усовершенствование быстрой сортировки, которое будет рассмотрено в разделе 7.5, хорошо еще и тем, что не нуждается ни в проверке, ни в сигнальном значении.
Процесс разбиения неустойчив, поскольку во время любой перестановки любой ключ может быть перемещен через большое количество равных ему ключей (еще не проверенных). Простые способы сделать быструю сортировку массива устойчивой пока не известны.
Реализацию процедуры разбиения следует выполнять с особой осторожностью. В частности, наиболее простой способ гарантировать завершение рекурсивной программы заключается в том, чтобы она (1) не вызывала себя для файлов размером 1 или менее и (2) вызывала себя только для файлов, размер которых строго меньше размеров входного файла. Эти правила кажутся очевидными, однако легко упустить из виду такое свойство входных данных, которое повлечет за собой катастрофическую ошибку.
Например, обычная ошибка при реализации быстрой сортировки заключается в отсутствии проверки того, что элемент всегда помещается на окончательное место, и если центральный элемент оказывается наибольшим или наименьшим элементом в файле, программа уходит в бесконечный рекурсивный цикл.
При наличии повторяющихся ключей фиксация момента перекрещивания индексов сопряжена с определенными трудностями. Процесс разбиения можно слегка усовершенствовать, заканчивая просмотр при i < j, а затем используя j вместо i-1, для определения правого конца левого подфайла в первом рекурсивном вызове. В этом случае лучше допустить лишнюю итерацию, т.к. если циклы просмотра прекращаются, когда j и i указывают на один тот же элемент, то в результате два элемента находятся в окончательных позициях: элемент, остановивший оба просмотра и поэтому равный центральному элементу, и сам центральный элемент. Подобная ситуация могла бы возникнуть, например, если бы на рис. 7.2 вместо R было E. Это изменение стоит внести в программу, т.к. иначе программа в том виде, в каком она здесь представлена, оставляет запись с ключом, равным центральному, в a[r], что приводит к вырожденному первому разбиению в вызове quicksort(a, i+1, r), поскольку его правый ключ оказывается наименьшим. Однако реализация разбиения в программе 7.2, несколько проще для понимания, так что в дальнейшем мы будем считать ее базовым методом разбиения. Если в файле может быть значительное число повторяющихся ключей, то на передний план выступают другие факторы, которые будут рассмотрены ниже.
Возможны три основных стратегии обработки ключей, равных центральному элементу: останавливать оба индекса на таких ключах (как в программе 7.2); останавливать один индекс, а другим пропустить их при просмотре; или пропустить их обоими индексами. Вопрос о том, какая из этих стратегий лучше, детально изучен математически, и результаты показывают, что лучше останавливать оба индекса - главным образом потому, что эта стратегия лучше балансирует разбиения при наличии большого количества повторяющихся ключей, в то время как две другие для некоторых файлов приводят к плохо сбалансированным разбиениям. В разделе 7.6 мы рассмотрим несколько более сложный и гораздо более эффективный способ работы с повторяющимися ключами.
В конечном счете эффективность сортировки зависит от качества разбиения файла, которое, в свою очередь, зависит от значения центрального элемента.
Процесс разбиения делит файл на два подфайла, которые можно упорядочить независимо. Ни один из элементов левее левого индекса не больше центрального элемента, поэтому нет точек левее и выше его. Аналогично ни один из элементов правее правого индекса не меньше центрального элемента, поэтому нет точек правее и ниже его. Как видно из этих двух примеров, разбиение случайно упорядоченного массива делит его на два меньших случайно упорядоченных массива и один (центральный) элемент, находящийся на диагонали.
На рис. 7.2 видно, что разбиение делит большой случайно упорядоченный файл на два меньших случайно упорядоченных файла, но реально точка раздела может оказаться в любом месте файла. Лучше было бы выбирать элемент, который разделит файл близко к середине, однако необходимая для этого информация отсутствует. Если файл случайно упорядочен, то выбор элемента a[r] в качестве центрального эквивалентен выбору любого другого конкретного элемента; и в среднем разбивает файл близко к середине. В разделе 7.4 мы проведем анализ алгоритма, который позволит сравнить этот выбор с идеальным выбором, а в разделе 7.5 увидим, как этот анализ поможет нам при выборе центрального элемента, повышающем эффективность алгоритма.
Упражнения
7.1. Покажите в стиле вышеприведенного примера, как быстрая сортировка сортирует файл E A S Y Q U E S T I O N.
7.2. Покажите, как производится разбиение файла 1 0 0 1 1 1 0 0 0 0 0 1 0 1 0 0, используя для этой цели программу 7.2 и поправки, предложенные в тексте.
7.3. Реализуйте разбиение без использования операторов break или goto.
7.4. Разработайте устойчивую быструю сортировку для связных списков.
7.5. Какое максимальное количество раз может быть перемещен наибольший элемент во время выполнения быстрой сортировки файла из N элементов?
Бактыгуль Асаинова
Александра Боброва
|
Я прошла все лекции на 100%. Но в https://www.intuit.ru/intuituser/study/diplomas ничего нет. Что делать? Как получить сертификат? |