Опубликован: 28.07.2007 | Доступ: свободный | Студентов: 2047 / 514 | Оценка: 4.53 / 4.26 | Длительность: 25:10:00
ISBN: 978-5-9556-0096-3
Специальности: Программист
Лекция 9:
Параллельные методы сортировки
9.5.3.1. Программная реализация
Представим возможный вариант параллельной программы обобщенной быстрой сортировки. При этом реализация отдельных модулей не приводится, если их отсутствие не оказывает влияния на понимание общей схемы параллельных вычислений.
1. Главная функция программы. Реализует логику работы алгоритма, последовательно вызывает необходимые подпрограммы.
// Программа 9.1.
// Обобщенная быстрая сортировка
int ProcRank; // Ранг текущего процесса
int ProcNum; // Количество процессов
int main(int argc, char *argv[]) {
double *pProcData; // Блок данных процесса
int ProcDataSize; // Размер блока данных
MPI_Init(&argc, &argv);
MPI_Comm_rank(MPI_COMM_WORLD, &ProcRank);
MPI_Comm_size(MPI_COMM_WORLD, &ProcNum);
// Инициализация данных и их распределение между процессами
ProcessInitialization(&pProcData, &ProcDataSize);
// Параллельная сортировка
ParallelHyperQuickSort(pProcData, ProcDataSize);
// Завершение вычислений процесса
ProcessTermination(pProcData, ProcDataSize);
MPI_Finalize();
}Функция ProcessInitialization определяет исходные данные решаемой задачи (размер сортируемого массива), выделяет память для хранения данных, осуществляет генерацию сортируемого массива (например, при помощи датчика случайных чисел) и распределяет его между процессами.
Функция ProcessTermination осуществляет необходимый вывод результатов решения задачи и освобождает всю ранее выделенную память для хранения данных.
Реализация всех перечисленных функций может быть выполнена по аналогии с ранее рассмотренными примерами и предоставляется читателю в качестве самостоятельного упражнения.
2. Функция ParallelHyperQuickSort. Функция производит параллельную быструю сортировку согласно рассмотренному алгоритму.
// Функция для выполнения обощенного алгоритма быстрой сортировки
void ParallelHyperQuickSort ( double *pProcData,
int ProcDataSize) {
MPI_Status status;
int CommProcRank; // Ранг процессора, с которым выполняется
// взаимодействие
double *pData, // Часть блока, остающаяся на процессоре
*pSendData, // Часть блока, передаваемая процессору
// CommProcRank
*pRecvData, // Часть блока, получаемая от процессора
// CommProcRank
*pMergeData; // Блок данных, получаемый после слияния
int DataSize, SendDataSize, RecvDataSize, MergeDataSize;
int HypercubeDim = (int)ceil(log(ProcNum)/log(2));
// размерность гиперкуба
int Mask = ProcNum;
double Pivot;
// Первоначальная сортировка блоков данных на каждом процессоре
LocalDataSort(pProcData, ProcDataSize);
// Итерации обобщенной быстрой сортировки
for (int i = HypercubeDim; i > 0; i-- ) {
// Определение ведущего значения и его рассылка всем процессорам
PivotDistribution(pProcData, ProcDataSize, HypercubeDim,
Mask, i,&Pivot);
Mask = Mask >> 1;
// Определение границы разделения блока
int pos = GetProcDataDivisionPos(pProcData, ProcDataSize, Pivot);
// Разделение блока на части
if ( ( (rank & Mask) >> (i - 1) ) == 0 ) { // старший бит = 0
pSendData = &pProcData[pos + 1];
SendDataSize = ProcDataSize - pos – 1;
if (SendDataSize < 0) SendDataSize = 0;
CommProcRank = ProcRank + Mask
pData = &pProcData[0];
DataSize = pos + 1;
}
else { // старший бит = 1
pSendData = &pProcData[0];
SendDataSize = pos + 1;
if (SendDataSize > ProcDataSize) SendDataSize = pos;
CommProcRank = ProcRank – Mask
pData = &pProcData[pos + 1];
DataSize = ProcDataSize - pos - 1;
if (DataSize < 0) DataSize = 0;
}
// Пересылка размеров частей блоков данных
MPI_Sendrecv(&SendDataSize, 1, MPI_INT, CommProcRank, 0,
&RecvDataSize, 1, MPI_INT, CommProcRank, 0, MPI_COMM_WORLD, &status);
// Пересылка частей блоков данных
pRecvData = new double[RecvDataSize];
MPI_Sendrecv(pSendData, SendDataSize, MPI_DOUBLE,
CommProcRank, 0, pRecvData, RecvDataSize, MPI_DOUBLE,
CommProcRank, 0, MPI_COMM_WORLD, &status);
// Слияние частей
MergeDataSize = DataSize + RecvDataSize;
pMergeData = new double[MergeDataSize];
DataMerge(pMergeData, pMergeData, pData, DataSize,
pRecvData, RecvDataSize);
delete [] pProcData;
delete [] pRecvData;
pProcData = pMergeData;
ProcDataSize = MergeDataSize;
}
}
9.1.
Функция LocalDataSort выполняет сортировку блока данных на каждом процессоре, используя последовательный алгоритм быстрой сортировки.
Функция PivotDistribution определяет ведущий элемент и рассылает его значение всем процессорам.
Функция GetProcDataDivisionPos выполняет разделение блока данных относительно ведущего элемента. Ее результатом является целое число, обозначающее позицию элемента на границе двух блоков.
Функция DataMerge осуществляет слияние частей в один упорядоченный блок данных.
3. Функция PivotDistribution. Функция выбирает ведущий элемент и рассылает его все процессорам гиперкуба. Так как данные на процессорах отсортированы с самого начала, ведущий элемент выбирается как средний элемент блока данных.
// Функция выбора и рассылки ведущего элемента
void PivotDistribution (double *pProcData, int ProcDataSize, int Dim,
int Mask, int Iter, double *pPivot) {
MPI_Group WorldGroup;
MPI_Group SubcubeGroup; // Группа процессов — подгиперкуб
MPI_Comm SubcubeComm; // Коммуникатор подгиперкуба
int j = 0;
int GroupNum = ProcNum /(int)pow(2, Dim-Iter);
int *ProcRanks = new int [GroupNum];
// формирование списка рангов процессов для гиперкуба
int StartProc = ProcRank – GroupNum;
if (StartProc < 0) StartProc = 0;
int EndProc = ProcRank + GroupNum;
if (EndProc > ProcNum) EndProc = ProcNum;
for (int proc = StartProc; proc < EndProc; proc++) {
if ((ProcRank & Mask)>>(Iter) == (proc & Mask)>>(Iter)) {
ProcRanks[j++] = proc;
}
}
// Объединение процессов подгиперкуба в одну группу
MPI_Comm_group(MPI_COMM_WORLD, &WorldGroup);
MPI_Group_incl(WorldGroup, GroupNum, ProcRanks, &SubcubeGroup);
MPI_Comm_create(MPI_COMM_WORLD, SubcubeGroup, &SubcubeComm);
// Поиск и рассылка ведущего элемента всем процессам подгиперкуба
if (ProcRank == ProcRanks[0])
*pPivot = pProcData[ProcDataSize / 2];
MPI_Bcast(pPivot, 1, MPI_DOUBLE, 0, SubcubeComm);
MPI_Group_free(&SubcubeGroup);
MPI_Comm_free(&SubcubeComm);
delete [] ProcRanks;
}
9.2.
9.5.3.2. Результаты вычислительных экспериментов
Вычислительные эксперименты для оценки эффективности параллельного варианта обобщенной быстрой сортировки производились при тех же условиях, что и ранее выполненные (см. п. 9.3.6).
Результаты вычислительных экспериментов даны в табл. 9.8. Эксперименты проводились с использованием двух и четырех процессоров. Время указано в секундах.
| Количество элементов | Последовательный алгоритм | Параллельный алгоритм | |||
|---|---|---|---|---|---|
| 2 процессора | 4 процессора | ||||
| Время | Ускорение | Время | Ускорение | ||
| 10000 | 0,001422 | 0,001485 | 0,957576 | 0,002898 | 0,490683 |
| 20000 | 0,002991 | 0,002180 | 1,372018 | 0,003770 | 0,793369 |
| 30000 | 0,004612 | 0,003077 | 1,498863 | 0,004451 | 1,036172 |
| 40000 | 0,006297 | 0,003859 | 1,631770 | 0,004721 | 1,333828 |
| 50000 | 0,008014 | 0,005041 | 1,589764 | 0,005242 | 1,528806 |
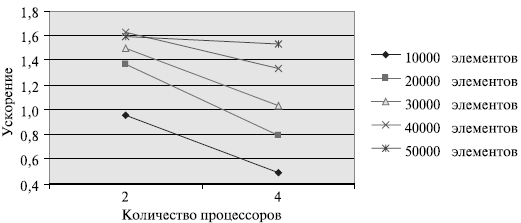
Рис. 9.9. Зависимость ускорения от количества процессоров при выполнении параллельного алгоритма обобщенной быстрой сортировки
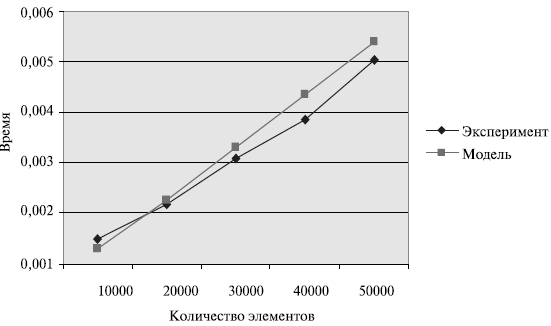
Сравнение времени выполнения эксперимента 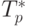 и
теоретической оценки Tp из (9.12)
приведено в таблице 9.9 и на
рис. 9.10.
и
теоретической оценки Tp из (9.12)
приведено в таблице 9.9 и на
рис. 9.10.
| Количество элементов | Параллельный алгоритм | |||
|---|---|---|---|---|
| 2 процессора | 4 процессора | |||
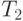 |
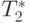 |
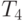 |
 |
|
| 10000 | 0,001281 | 0,001485 | 0,001735 | 0,002898 |
| 20000 | 0,002265 | 0,002180 | 0,002322 | 0,003770 |
| 30000 | 0,003289 | 0,003077 | 0,002928 | 0,004451 |
| 40000 | 0,004338 | 0,003859 | 0,003547 | 0,004721 |
| 50000 | 0,005407 | 0,005041 | 0,004176 | 0,005242 |