Опубликован: 28.07.2007 | Доступ: свободный | Студентов: 2062 / 523 | Оценка: 4.53 / 4.26 | Длительность: 25:10:00
ISBN: 978-5-9556-0096-3
Специальности: Программист
Лекция 4:
Принципы разработки параллельных методов
Аннотация: В лекции рассматриваются базовые принципы разработки параллельных алгоритмов. Описываются основные понятия, подробно разбираются все этапы создания и анализа параллельных алгоритмов. Приводится пример применения обсуждаемых методов
Ключевые слова: ПО, множества, вычисления программы, процесс, канал, процессор, система с распределенной памятью, механизмы, граф "подзадачи – сообщения", граф "процессы – каналы", выделение подзадач, определение информационных зависимостей, матричные вычисления, параллелизм по данным, функциональный параллелизм, конвейерная обработка данных, векторное произведение, контрольные списки, передача данных между процессами, структурный способ, операции передачи данных, мультипроцессор, топология сети передачи данных, разреженные матрицы, масштабирование и распределение подзадач по процессорам
Разработка алгоритмов (а в особенности методов параллельных вычислений) для решения сложных научно-технических задач часто представляет собой значительную проблему. Для снижения сложности рассматриваемой темы оставим в стороне математические аспекты разработки и доказательства сходимости алгоритмов – эти вопросы в той или иной степени изучаются в ряде "классических" математических учебных курсов. Здесь же мы будем полагать, что вычислительные схемы решения задач, рассматриваемых далее в качестве примеров, уже известны1Несмотря на то, что для многих научно-технических задач на самом деле известны не только последовательные, но и параллельные методы решения, данное предположение является, конечно, очень сильным, поскольку для новых возникающих задач, требующих для своего решения большого объема вычислений, процесс разработки алгоритмов составляет существенную часть всех выполняемых работ.. С учетом высказанных предположений последующие действия для определения эффективных способов организации параллельных вычислений могут состоять в следующем:
- выполнить анализ имеющихся вычислительных схем и осуществить их разделение ( декомпозицию ) на части ( подзадачи ), которые могут быть реализованы в значительной степени независимо друг от друга;
- выделить для сформированного набора подзадач информационные взаимодействия, которые должны осуществляться в ходе решения исходной поставленной задачи;
- определить необходимую (или доступную) для решения задачи вычислительную систему и выполнить распределение имеющего набора подзадач между процессорами системы.
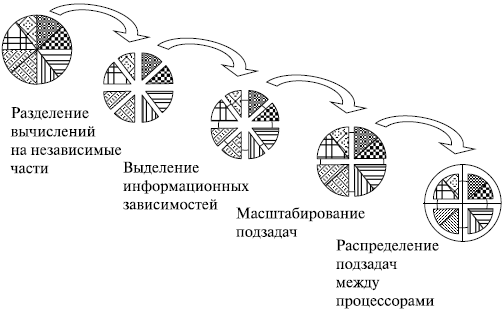
При самом общем рассмотрении понятно, что объем вычислений для каждого используемого процессора должен быть примерно одинаков – это позволит обеспечить равномерную вычислительную загрузку ( балансировку ) процессоров. Кроме того, также понятно, что распределение подзадач между процессорами должно быть выполнено таким образом, чтобы количество информационных связей ( коммуникационных взаимодействий ) между подзадачами было минимальным.
После выполнения всех перечисленных этапов проектирования можно оценить эффективность разрабатываемых параллельных методов: для этого обычно определяются значения показателей качества порождаемых параллельных вычислений ( ускорение, эффективность, масштабируемость ). По результатам проведенного анализа может оказаться необходимым повторение отдельных (в предельном случае всех) этапов разработки – следует отметить, что возврат к предшествующим шагам разработки может происходить на любой стадии проектирования параллельных вычислительных схем.
Поэтому часто выполняемым дополнительным действием в приведенной выше схеме проектирования является корректировка состава сформированного множества задач после определения имеющегося количества процессоров – подзадачи могу быть укрупнены ( агрегированы ) при наличии малого числа процессоров или, наоборот, детализированы в противном случае. В целом, данные действия могут быть определены как масштабирование разрабатываемого алгоритма и выделены в качестве отдельного этапа проектирования параллельных вычислений.
Чтобы применить получаемый в конечном итоге параллельный метод, необходимо выполнить разработку программ для решения сформированного набора подзадач и разместить разработанные программы по процессорам в соответствии с выбранной схемой распределения подзадач. Для проведения вычислений программы запускаются на выполнение (программы на стадии выполнения обычно именуются процессами ), для реализации информационных взаимодействий программы должны иметь в своем распоряжении средства обмена данными ( каналы передачи сообщений ).
Следует отметить, что каждый процессор обычно выделяется для решения единственной подзадачи, однако при наличии большого количества подзадач или использовании ограниченного числа процессоров это правило может не соблюдаться и, в результате, на процессорах может выполняться одновременно несколько программ ( процессов ). В частности, при разработке и начальной проверке параллельной программы для выполнения всех процессов может использоваться один процессор (при расположении на одном процессоре процессы выполняются в режиме разделения времени).
Рассмотрев внимательно разработанную схему проектирования и реализации параллельных вычислений, можно отметить, что данный подход в значительной степени ориентирован на вычислительные системы с распределенной памятью, когда необходимые информационные взаимодействия реализуются при помощи передачи сообщений по каналам связи между процессорами. Тем не менее данная схема может быть применена без потери эффективности параллельных вычислений и для разработки параллельных методов для систем с общей памятью – в этом случае механизмы передачи сообщений для обеспечения информационных взаимодействий должны быть заменены операциями доступа к общим (разделяемым) переменным.
4.1. Моделирование параллельных программ
Рассмотренная схема проектирования и реализации параллельных вычислений дает способ понимания параллельных алгоритмов и программ. На стадии проектирования параллельный метод может быть представлен в виде графа "подзадачи – сообщения", который представляет собой не что иное, как укрупненное (агрегированное) представление графа информационных зависимостей (графа "операции – операнды" – см. "Моделирование и анализ параллельных вычислений" ). Аналогично на стадии выполнения для описания параллельной программы может быть использована модель в виде графа "процессы – каналы", в которой вместо подзадач используется понятие процессов, а информационные зависимости заменяются каналами передачи сообщений. Дополнительно на этой модели может быть показано распределение процессов по процессорам вычислительной системы, если количество подзадач превышает число процессоров – см. рис. 4.2.

Использование двух моделей параллельных вычислений2В [ [ 32 ] ] рассматривается только одна модель - модель "задача - канал" для описания параллельных вычислений, которая занимает некоторое промежуточное положение по сравнению с изложенными здесь моделями. Так, в модели "задача - канал" не учитывается возможность использования одного процессора для решения нескольких подзадач одновременно. позволяет лучше разделить проблемы, которые проявляются при разработке параллельных методов. Первая модель – граф "подзадачи – сообщения" – позволяет сосредоточиться на вопросах выделения подзадач одинаковой вычислительной сложности, обеспечивая при этом низкий уровень информационной зависимости между подзадачами. Вторая модель – граф "процессы – каналы" – концентрирует внимание на вопросах распределения подзадач по процессорам, обеспечивая еще одну возможность снижения трудоемкости информационных взаимодействий между подзадачами за счет размещения на одних и тех же процессорах интенсивно взаимодействующих процессов. Кроме того, эта модель позволяет лучше анализировать эффективность разработанного параллельного метода и обеспечивает возможность более адекватного описания процесса выполнения параллельных вычислений.
Дадим дополнительные пояснения для используемых понятий в модели "процессы – каналы":
- под процессом будем понимать выполняемую на процессоре программу, которая использует для своей работы часть локальной памяти процессора и содержит ряд операций приема/передачи данных для организации информационного взаимодействия с другими выполняемыми процессами параллельной программы;
- канал передачи данных с логической точки зрения может рассматриваться как очередь сообщений, в которую один или несколько процессов могут отправлять пересылаемые данные и из которой процесс -адресат может извлекать сообщения, отправляемые другими процессами.
В общем случае, можно считать, что каналы возникают динамически в момент выполнения первой операции приема/передачи с каналом. По степени общности канал может соответствовать одной или нескольким командам приема данных процесса -получателя; аналогично, при передаче сообщений канал может использоваться одной или несколькими командами передачи данных одного или нескольких процессов. Для снижения сложности моделирования и анализа параллельных методов будем предполагать, что емкость каналов является неограниченной и, как результат, операции передачи данных выполняются практически без задержек простым копированием сообщений в канал. С другой стороны, операции приема сообщений могут приводить к задержкам ( блокировкам ), если запрашиваемые из канала данные еще не были отправлены процессами – источниками сообщений.
Следует отметить важное достоинство рассмотренной модели "процессы – каналы" – в ней проводится четкое разделение локальных (выполняемых на отдельном процессоре) вычислений и действий по организации информационного взаимодействия одновременно выполняемых процессов. Такой подход значительно снижает сложность анализа эффективности параллельных методов и существенно упрощает проблемы разработки параллельных программ.