|
"Теоретически канал с адресацией EUI 64 может соединить порядка запись вида ее можно заменить например на записи вида 264 или 1,8 * 1019
|
Опубликован: 30.07.2013 | Доступ: свободный | Студентов: 1897 / 161 | Длительность: 24:05:00
Тема: Сетевые технологии
Специальности: Архитектор программного обеспечения
Лекция 9:
Управление групповым трафиком
Хотя этих двух типов уже вполне хватило бы, перезагружать с нуля весь список каждый раз, когда надо послать отчет, было бы излишне. Поэтому мы предусмотрим еще два случая.
В первом из них слушатель хочет разрешить или блокировать несколько дополнительных источников, не меняя остальной их список. Так возникают типы записи ALLOW_NEW_SOURCES (тип 5) и BLOCK_OLD_SOURCES (тип 6), сокращенно ALLOW(S) и BLOCK(S).
Второй заслуживающий оптимизации случай — это периодический ответ на запрос маршрутизатора, которым слушатель сообщает свой текущий фильтр, хотя тот остается без изменений. Для этого он использует отдельные типы записи, MODE_IS_INCLUDE (тип 1) и MODE_IS_EXCLUDE (тип 2), сокращенно IS_IN(S) и IS_EX(S) . Благодаря этому маршрутизаторы могут оптимизировать обработку фильтров, пока те остаются постоянными. Кроме того, маршрутизатор не должен реагировать на эти записи дополнительными запросами, чтобы не вызвать зацикливание протокола.
Чтобы не повторять все время "запись отчета" и не путать ее с записью о группе в оперативной памяти узла, впредь мы будем говорить просто "отчет", например, "отчет IS_EX", памятуя при этом, что соответствующее сообщение MLDv2 составное и может содержать в себе более одного отчета, каждый из них об определенной группе.
Слушатель вполне может комбинировать разные отчеты об одной и той же группе, чтобы гибко уведомлять маршрутизаторы об изменениях в состоянии своего фильтра данной группы, используя при этом минимум сообщений MLDv2. К примеру, когда фильтр группы Г переходит из состояния INCLUDE( ) в состояние INCLUDE( ), где  и
и 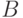 — вообще говоря, разные множества источников, допущенных к данной группе Г, можно выделить два подмножества источников, затронутых этой операцией. Множество за вычетом множества , в математической нотации
— вообще говоря, разные множества источников, допущенных к данной группе Г, можно выделить два подмножества источников, затронутых этой операцией. Множество за вычетом множества , в математической нотации  больше не интересно слушателю, и его можно заблокировать. Напротив, множество , за вычетом множества , то есть
больше не интересно слушателю, и его можно заблокировать. Напротив, множество , за вычетом множества , то есть  , раньше не интересовало слушателя, так что его надо разблокировать и допустить к группе. В то же время, пересечение множеств и , то есть
, раньше не интересовало слушателя, так что его надо разблокировать и допустить к группе. В то же время, пересечение множеств и , то есть  , остается интересным слушателю, и его статус не изменяется. Поэтому, чтобы объявить о данном переходе, достаточно два отчета в любом порядке: BLOCK( ) и ALLOW( ). Эти отчеты можно объединить в одно сообщение MLDv2, если позволяет их длина.
, остается интересным слушателю, и его статус не изменяется. Поэтому, чтобы объявить о данном переходе, достаточно два отчета в любом порядке: BLOCK( ) и ALLOW( ). Эти отчеты можно объединить в одно сообщение MLDv2, если позволяет их длина.
Пусть читатель наглядно изобразит этот пример с помощью кругов Эйлера.
В принципе, то же самое изменение можно было бы выразить всего одним отчетом TO_IN(B), однако этот отчет подразумевает, что изменился режим работы фильтра. В ответ маршрутизаторы начнут дополнительные проверки. Кроме того, если фильтр сам по себе длинный, а изменился он всего на пару источников, то суммарная длина двух отчетов ALLOW и BLOCK будет меньше, чем длина одного TO_IN, так как ALLOW и BLOCK передают только изменения, а TO_IN и TO_EX — фильтр целиком. Поэтому слушателю будет лучше воздержаться от применения TO_IN или TO_EX, когда подстраивается уже существующий фильтр.
Используя наши соображения, составим сводку основных правил для слушателя группы в Табл. 8.2. Здесь 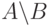 обозначает разность множеств и (множество всех элементов , которые не принадлежат также ), а (
обозначает разность множеств и (множество всех элементов , которые не принадлежат также ), а ( — пустое множество.
— пустое множество.
| Текущее состояние | Новое состояние | Отчет |
|---|---|---|
| начало приема или EXCLUDE( ) |
INCLUDE( ) |
TO_IN( ) |
| начало приема или INCLUDE( ) |
EXCLUDE( ) |
TO_EX( ) |
| INCLUDE( ) |
INCLUDE( ) |
BLOCK(), ALLOW(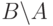 ) ) |
| EXCLUDE( ) |
EXCLUDE( ) |
ALLOW(), BLOCK() |
| INCLUDE( ) или EXCLUDE( ) |
конец приема | TO_IN() |
На практике дополнительная сложность возникает из-за того, что источник должен повторить свой отчет несколько раз. Если группа изменит свое состояние во время повтора отчета о ней, надо объединить старый и новый отчет, используя все те же соображения теории множеств [§6.1 RFC 3810].
Очевидная особенность SSM состоит в том, что о групповых адресах FF3x::/96 не должно быть отчетов IS_EX или TO_EX. Дело в том, что слушатель SSM заведомо заинтересован в ограниченном числе источников, и поэтому он может вести прием группы только в режиме INCLUDE [§2.2.2 RFC 4604].
Теперь нам осталось понять, как маршрутизатор сведет вместе отчеты разных слушателей об одной и той же группе. Поскольку это довольно непростая задача, давайте начнем ее исследование с частных случаев, легче поддающихся анализу.
Пока все слушатели работают только во включающем или только в исключающем режиме, решение нам дает элементарная теория множеств. Как мы уже
говорили, маршрутизатор обязан допустить к группе объединение первичных множеств источников, чтобы случайно не заблокировать желательный источник,
а окончательную фильтрацию проведут сами слушатели. При включающем режиме искомая операция и есть объединение включающих фильтров
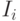 :
:
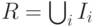 .
.
Если же все источники работают в исключающем режиме, то лучшее, что может сделать маршрутизатор, это блокировать пересечение всех исключающих фильтров :
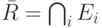 .
.
Ведь для множеств справедливо такое следствие законов де Моргана:
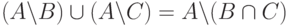 .
.
Если A — это множество всех адресов IPv6, а B и C — множества двух исключающих фильтров, то смысл этого равенства именно в том, что пересечение исключающих фильтров эквивалентно объединению включающих фильтров.
А как быть, когда на канале есть слушатели группы в разных режимах? Снова применим правило объединения первичных множеств для создания удовлетворительного фильтра. При объединении множеств число элементов не уменьшается, а первичное множество любого исключающего фильтра, пока он разумной длины, уже содержит почти все адреса IPv6. Значит, и суммарный фильтр в своем первичном виде будет содержать почти  элементов. Как мы знаем, в этом случае надо просто блокировать остальные адреса, чтобы не иметь дела с фильтром чудовищной длины. Поэтому подходящим режимом суммарного фильтра будет именно исключающий. Иными словами, как только хотя бы один из слушателей переходит в исключающий режим, то же самое вынуждены сделать и маршрутизаторы. При этом блокировать надо пересечение всех исключающих фильтров за вычетом объединения всех включающих фильтров:
элементов. Как мы знаем, в этом случае надо просто блокировать остальные адреса, чтобы не иметь дела с фильтром чудовищной длины. Поэтому подходящим режимом суммарного фильтра будет именно исключающий. Иными словами, как только хотя бы один из слушателей переходит в исключающий режим, то же самое вынуждены сделать и маршрутизаторы. При этом блокировать надо пересечение всех исключающих фильтров за вычетом объединения всех включающих фильтров:
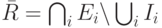 .
.
В частности, пока есть слушатели в режиме ASM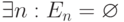 , этот фильтр будет пустой и маршрутизатор не сможет блокировать ни один источник. Когда же последний слушатель в исключающем режиме прекратит прием группы, маршрутизатору следует вернуться во включающий режим, чтобы эффективнее фильтровать трафик группы. Если затем и слушатели во включающем режиме завершат прием, включающий фильтр опустеет:
, этот фильтр будет пустой и маршрутизатор не сможет блокировать ни один источник. Когда же последний слушатель в исключающем режиме прекратит прием группы, маршрутизатору следует вернуться во включающий режим, чтобы эффективнее фильтровать трафик группы. Если затем и слушатели во включающем режиме завершат прием, включающий фильтр опустеет:  , — что отвечает концу продвижения группы в данный канал.
, — что отвечает концу продвижения группы в данный канал.
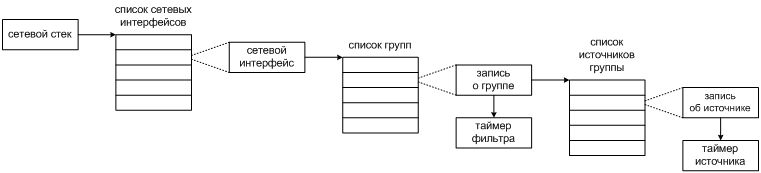
Это и есть теоретико-множественная основа поддержки SFM и SSM в MLDv2. Все остальное в ней — суть важные, но не несущие фундаментального значения детали. Среди них выделяется вопрос о том, как маршрутизатор станет управлять текущей информацией о группе, чтобы она оставалась актуальной. В MLDv1 для этого было достаточно связать с группой один таймер, а когда кто-то из слушателей прекращал прием группы, запросом о данной группе проверить, остались ли в ней другие слушатели. То есть элементарным объектом управления выступала группа. Теперь же разные слушатели изъявляют желание, или нежелание, принимать трафик группы из разных источников, но маршрутизатор по-прежнему не ведет поименного списка слушателей и не запоминает, кто именно из них заинтересован в данном источнике. Поэтому отдельный таймер потребуется каждой записи об источнике группы в памяти маршрутизатора [§7.2 RFC 3810], а элементарным объектом управления в MLDv2 станет источник данной группы, как это показано на рис. 8.6.
Обратите внимание: у разных групп могут быть разные предпочтения насчет одного и того же источника, а их фильтры независимы друг от друга. Поэтому один и тот же адрес IP источника вполне может фигурировать в разных записях, если они связаны с разными группами.
Когда слушатель группы заявляет отчетом IS_IN(A), TO_IN(A) или ALLOW(A) о своем желании принимать пакеты из некоторого множества источников A, маршрутизатор обязан немедленно допустить трафик из источников A в канал. Напротив, когда слушатель группы не желает вести прием из данного множества источников B и включает в свой отчет элемент IS_EX(B), TO_EX(B) или BLOCK(B) , маршрутизатор не вправе тут же заблокировать все множество источников B, потому что, возможно, у некоторых источников в нем есть и другие слушатели. Точно так же в MLDv1 маршрутизатор не мог прекратить продвижение трафика группы, едва получив итоговое сообщение от одного слушателя, — он был обязан проверить, остались ли у группы другие слушатели. Это вызвано тем, что маршрутизатор не ведет поименного учета слушателей.
Тем не менее, по приходу отчета IS_EX(B), TO_EX(B) или BLOCK(B) маршрутизатору не обязательно проверять все множество блокируемых источников B. Ведь в этот момент у маршрутизатора уже есть определенное первичное множество допущенных источников S, закодированное в терминах INCLUDE или EXCLUDE . (Как мы говорили, во включающем режиме (INCLUDE ) первичное множество просто равно фильтру, который маршрутизатор хранит в своей памяти:  , — а в исключающем режиме (EXCLUDE ) оно равно дополнению этого фильтра до множества всех адресов IPv6, нашего универсума:
, — а в исключающем режиме (EXCLUDE ) оно равно дополнению этого фильтра до множества всех адресов IPv6, нашего универсума: 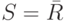 .) Поэтому проверить запросом необходимо только пересечение множеств B и S:
.) Поэтому проверить запросом необходимо только пересечение множеств B и S: 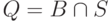 , — так как адреса вне этого подмножества в любом случае сохраняют свое состояние: подмножество
, — так как адреса вне этого подмножества в любом случае сохраняют свое состояние: подмножество 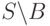 по-прежнему остается допущенным к группе, а
по-прежнему остается допущенным к группе, а 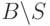 уже заблокировано.
уже заблокировано.
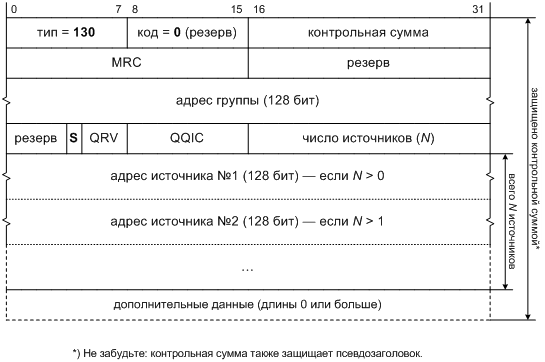
Чтобы провести проверку источников направленно, маршрутизатору понадобится уточнить запрос MLD не только группой, о которой идет речь, но и
множеством источников Q, состояние которых его интересует. Поэтому в MLDv2 у запроса появляется новая разновидность: запрос, ограниченный
группой и источниками ( Multicast Address and Source Specific Query ). Нужно ли уточнять в таком запросе режим фильтрации,
INCLUDE или EXCLUDE ? На самом деле, групповой маршрутизатор всегда спрашивает только о желательных источниках — он никогда не
ставит вопрос: "Кто блокирует данный источник?" — потому что блокировка происходит по умолчанию. Это следует из самого предназначения MLD:
избавиться от как можно большей доли ненужного группового трафика. Множество же содержит не больше элементов, чем
множество B, приведенное в отчете. Поэтому множество Q тоже можно указать простым перечислением его элементов. Следовательно, запрос MLDv2
ставится только в режиме INCLUDE , и явное указание режима в нем излишне. Такой запрос о группе Г, ограниченный списком источников
Q, мы будем обозначать Q(Г,Q), а запрос, ограниченный только группой Г — просто Q(Г). Запрос Q(Г) отличается от Q(Г,Q) тем, что содержит ноль
источников, то есть список Q в нем пуст. Их общий формат показан на рис. 8.7 и содержит несколько полей, которые понадобятся нам чуть позднее.
Хотя ограниченность запроса Q(Г,Q) режимом INCLUDE вполне обоснована, она приходит в противоречие с исключающим режимом работы фильтра и вызывает дополнительную сложность в управлении проверкой источников. Пока фильтр самого маршрутизатора работает во включающем режиме, отслеживать состояние проверки множества источников Q просто: Q — это заведомо подмножество фильтра 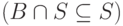 , о каждом элементе Q уже есть запись в памяти маршрутизатора, и потому при проверке достаточно понизить тайм-ауты на всех записях Q. Напротив, в исключающем режиме элементы Q заведомо отсутствуют в фильтре
, о каждом элементе Q уже есть запись в памяти маршрутизатора, и потому при проверке достаточно понизить тайм-ауты на всех записях Q. Напротив, в исключающем режиме элементы Q заведомо отсутствуют в фильтре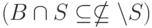 , и маршрутизатору придется хранить записи об элементах Q отдельно от рабочего фильтра.
, и маршрутизатору придется хранить записи об элементах Q отдельно от рабочего фильтра.
Поэтому во включающем режиме состояние группы, с точки зрения маршрутизатора, можно задать всего одним списком источников, тогда как в исключающем режиме понадобятся целых два списка. Общепринятые обозначения этих состояний [§2.3 RFC 3810] приведены и прокомментированы в Табл. 8.3.
| Обозначение | Режим | Смысл параметров |
|---|---|---|
| INCLUDE() |
Включающий | — "список включений" (Include List). Это список источников, допущенных к
группе. Все прочие источники заблокированы. |
EXCLUDE( , , ) ) |
Исключающий | X — "список требований" (Requested List). Это список источников, которые все еще могут быть интересны некоторым слушателям.
Поэтому их нельзя немедленно блокировать, а необходимо проверить с помощью запроса MLD.
Ниже мы встретим еще одну роль списка требований.
Y — "список исключений" (Exclude List). Это список заблокированных источников. Все прочие источники, включая элементы X, допущены к группе.
|
В состоянии EXCLUDE(X,Y) пересечение множеств X и Y, очевидно, пусто: 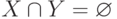 , — поскольку нельзя одновременно допускать и блокировать один и тот же источник. Следовательно, X вообще не влияет на работу фильтра в текущий момент. Но если на записи об элементе
, — поскольку нельзя одновременно допускать и блокировать один и тот же источник. Следовательно, X вообще не влияет на работу фильтра в текущий момент. Но если на записи об элементе 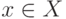 истечет тайм-аут, в модели MLD это будет означать, что данный источник x больше не интересен никому. Тогда маршрутизатор сможет перенести элемент x из списка X в список Y, тем самым заблокировав источник x и избавив канал от ненужного группового трафика. В этом и состоит роль списка X.
истечет тайм-аут, в модели MLD это будет означать, что данный источник x больше не интересен никому. Тогда маршрутизатор сможет перенести элемент x из списка X в список Y, тем самым заблокировав источник x и избавив канал от ненужного группового трафика. В этом и состоит роль списка X.
Правила поведения маршрутизатора в ответ на отчеты слушателей группы оказываются довольно сложными, потому что они должны учесть все наши предыдущие соображения. Волноваться из-за этого не стоит: мы разберем и прокомментируем свод этих правил. Однако прежде нам надо уточнить еще несколько деталей.
Как мы уже сказали, в MLDv2 элементарным объектом управления групповым трафиком служит источник группы. При этом групповой маршрутизатор занимается тем, что минимизирует избыточный трафик в канал, блокируя никому не интересные источники. Условно говоря, маршрутизатор стремится заблокировать весь трафик группы, но ему мешают отчеты слушателей, требующие допустить тот или иной источник.
Пока запись об источнике группы находится в списке включений или требований, она явно разрешает трафик от этого источника, и маршрутизатор заинтересован в том, чтобы заблокировать этот источник, как только его перестанут слушать. Для этого маршрутизатор запускает на записи об источнике таймер, который срабатывает, если о данном источнике группы давно не было отчетов. Дальнейшая судьба записи зависит от режима фильтра, но в любом случае она приводит к блокировке источника. Так, во включающем режиме запись удаляется из списка включений, а в исключающем режиме она перемещается в список исключений.
Конечно же, мы помним, что запись об источнике привязана к определенной группе. Например, один и тот же источник И может быть допущен маршрутизатором к группе Г1, но заблокирован для группы Г2. В терминах заголовка IPv6 это означает, что пакеты от И к Г1 будут продвигаться в данный канал, а пакеты от И к Г2 — нет. Это находит прямое отражение в иерархии структур, которые маршрутизатор хранит в своей памяти.
Сергей Субботин
 "
"
Павел Афиногенов
|
Курс IPv6, в тексте имеются ссылки на параграфы. Разбиения курса на параграфы нет. |