
|
"Теоретически канал с адресацией EUI 64 может соединить порядка запись вида ее можно заменить например на записи вида 264 или 1,8 * 1019
|
Лекция 9:
Управление групповым трафиком
Перейдем к следующему усовершенствованию. В предварительной версии MLD мы отложили вопрос о том, как групповые маршрутизаторы канала выберут ровно одного из своего числа на роль генератора запросов ( querier). Вот простой и остроумный подход к этой, казалось бы, сложной задаче: пускай роль генератора играет маршрутизатор с наименьшим адресом IP.
Мы, конечно же, помним из §2.2, что адрес IP (v4 или v6) — это цепочка битов с определенным порядком старшинства, а значит, ее можно рассматривать как двоичную запись целого неотрицательного числа. Однозначность позиционной записи чисел гарантирует нам, что соответствие между побитовым представлением адреса и его численным значением взаимно однозначно, а значит, у разных адресов заведомо разное численное значение. Точнее говоря, позиционная запись однозначна с точностью до незначащих нулей, но адресов IP эта оговорка не касается ввиду их фиксированной разрядности. Если бы адреса IP были переменной длины, нам пришлось бы явным образом уточнить, имеют ли значение нули в старших разрядах адреса, например, являются ли 1 и 01 суть разными адресами или же эквивалентными представлениями одного и того же адреса. Разумеется, все эти соображения справедливы только в пределах определенной версии IP.
Чуть выше мы позаботились, чтобы маршрутизаторы получали запросы друг друга. Каждый из них шлет свои запросы с определенного внутриканального адреса, который, несомненно, уникален в пределах канала — об этом позаботился механизм DAD из §5.4.1. Теперь представим себе, что маршрутизатор получил запрос, адрес IP источника в котором численно меньше, чем его собственный. Это значит, что есть более вероятный претендент на роль генератора, и собственные запросы надо приостановить на какое-то время, большее, чем стандартный период повтора запросов. В результате самый подходящий кандидат станет непрерывно подавлять своими запросами другие маршрутизаторы, и те будут оставаться пассивными наблюдателями (non-querier). Математическая основа этого трюка — транзитивность отношений "больше" и "меньше" на множестве целых чисел: 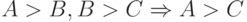 . Благодаря этому свойству процесс выборов гарантированно сойдется, как только все маршрутизаторы получат все неподавленные запросы своих соперников. Когда же текущий генератор выйдет из игры, сработают таймеры, процедура выборов повторится, и место генератора займет новый победитель. В результате мы получаем простой и устойчивый механизм.
. Благодаря этому свойству процесс выборов гарантированно сойдется, как только все маршрутизаторы получат все неподавленные запросы своих соперников. Когда же текущий генератор выйдет из игры, сработают таймеры, процедура выборов повторится, и место генератора займет новый победитель. В результате мы получаем простой и устойчивый механизм.
Очевидно, что в общем случае подобные выборы можно провести, используя любой уникальный идентификатор и любое транзитивное отношение над ним.
Так как у наблюдателя может быть несколько внутриканальных адресов на данном интерфейсе, для сравнения он выбирает и использует именно тот из них, с которого он слал бы — и шлет во время выборов — свои собственные запросы.
Еще один заслуживающий оптимизации аспект — это окончание приема группы. Информация о начале приема группы не задерживается, потому что новый слушатель первым делом высылает добровольный отчет об этой группе. Напротив, окончание приема проходит втихомолку. Маршрутизатор делает вывод о том, что все слушатели прекратили прием группы, когда об этой группе давно не было отчетов. Сколько времени ему на это понадобится? Запрос к слушателям — довольно дорогая операция, так как сначала пакет с запросом направляется всем узлам канала, а затем слушатели разных групп отвечают на него одним пакетом на каждую группу. Поэтому период повтора запросов должен быть достаточно большим, порядка минут. Следовательно, и уход всех слушателей будет обнаружен не раньше, чем через несколько минут.
Чтобы ускорить этот процесс, пусть слушатель явным образом извещает маршрутизаторы о прекращении приема данной группы Г. Для этого он высылает сообщение нового типа, итог (Done). Как и отчет, это сообщение содержит в себе адрес группы Г, о которой идет речь. По какому адресу лучше всего направить итог? Здесь у нас пока всего два варианта, "все маршрутизаторы канала", FF02::2, и адрес данной группы Г. Обычно маршрутизаторов на канале меньше, чем потенциальных слушателей группы, а сообщения типа "итог" будут относительно редки, так что мы остановим свой выбор на первом варианте, FF02::2.
Теперь представим себе, что групповые маршрутизаторы канала получили итоговое сообщение о группе Г от некоего слушателя. Поскольку маршрутизаторы не ведут поименный список слушателей и даже не считают их "по головам", то само по себе это сообщение еще не дает им всей необходимой информации — оно только извещает, что произошли изменения в числе слушателей группы Г. Естественной реакцией маршрутизаторов будет проверить, остались ли в группе Г еще слушатели. Для этого генератору запросов надо послать в канал несколько запросов с короткими паузами между ними.
Если это будут обычные запросы, они вызовут целый поток информации, не относящейся к делу. Поэтому нам следует ограничить эти запросы группой Г, о которой пришло итоговое сообщение. Во-первых, такие запросы надо направлять по адресу группы Г, а не "все узлы канала". Во-вторых, в самих запросах надо указать, что они касаются только группы Г. То есть тело запроса тоже должно включать в себя поле "адрес группы". В обычном, общем запросе (General Query) значение этого поля будет нулевым, тогда как в запросе, ограниченном группой (Multicast-Address-Specific Query), это поле содержит действительный адрес группы.
Мелкая, но важная деталь — это взаимодействие между процедурой быстрой проверки группы и выборами генератора запросов. Как быть текущему генератору, если он еще не послал положенное число запросов группе Г, а тем временем пришел чужой запрос с еще меньшим адресом источника? Пусть ради простоты и устойчивости протокола текущий генератор всегда доводит процедуру быстрой проверки до конца. Ведь выборы генератора — это лишь оптимизация, и не будет никакой беды в том, что на протяжении нескольких секунд запросы будут слать два маршрутизатора.
Последний штрих в нашей схеме быстрой проверки группы коснется координации генератора запросов с наблюдателями. Как последние узнают, что идет оперативная проверка группы и связанные с ней таймеры надо установить на более короткий интервал? По нашему плану, наблюдатели продолжают получать запросы, а ритм задает генератор запросов, так что пускай он заодно сообщает наблюдателям, какой тайм-аут надо связать с данным запросом. Для этого достаточно одного целочисленного поля в формате запроса. В свою очередь, слушателям оно пригодится, чтобы равномернее распределить отчеты в доступном времени, выбирая случайную задержку от нуля до значения этого поля. За эту роль данное поле известно как MRD (Maximum Response Delay, максимальная задержка отклика). Размерность значения MRD — миллисекунды.
Маршрутизаторы обращают внимание на поле MRD, только если принят запрос, ограниченный группой. Общие запросы на интервалы таймеров не влияют.
Строго говоря, слушателям следует вносить поправку на задержку передачи по каналу, выбирая задержку отчета на основании MRD. Ведь иначе отчет может запоздать.
Перейдем к формату сообщений. Формат запроса и ответа будет одним и тем же, чтобы упростить реализацию (см. рис. 8.3). Конечно, поле MRD в ответе или итоге не несет никакой смысловой нагрузки. Длина такого унифицированного сообщения фиксирована и составляет 24 байта. Как быть, если пакет содержит еще какие-то данные вслед за фиксированным сообщением? Эту возможность мы узаконим, но оставим для будущих расширений протокола. На входе дополнительные данные надо просто игнорировать, а на выходе пока что никаких дополнительных данных быть не должно.
"Сконструированные" нами механизмы составляют костяк первой версии протокола розыска слушателей IPv6, MLDv1 [RFC 2710].
Тем же самым образом работает IGMPv2 в IPv4 [RFC 2236].
Любопытно отметить, что у сообщений MLDv1 типы численно меньше, чем у сообщений ND. Это можно объяснить тем, что MLD логически предшествует ND. К примеру, группу искомого узла надо объявить по MLD до того, как ею можно пользоваться в целях ND.
Мы провели довольно много времени, пересматривая и оттачивая детали протокола MLDv1, так что давайте соберем самые главные его черты в одной таблице, Табл. 8.1, а заодно сравним его с нашей пробной "нулевой версией", аналогичной IGMPv1 в IPv4, чтобы лучше увидеть проделанный путь.
| "MLDv0" | MLDv1 | |
|---|---|---|
| Типы сообщений ICMPv6 | "запрос MLD" (130), "отчет MLD" (131) | "запрос MLD" (130), "отчет MLD" (131), "итог MLD" (132) |
| Виды запроса | Только общий | Общий и ограниченный группой |
| Форма отчета | Одна группа на сообщение | Одна группа на сообщение |
| Адрес назначения в отчете | Объявляемая группа | Объявляемая группа |
| Выборы генератора запросов | Механизм не определен | По адресу IPv6 |
| Подавление избыточных отчетов | Да | Да |
| Управление интервалом таймера | Нет | Да |
Способны ли мы еще улучшить наш результат во второй версии протокола, MLDv2 [RFC 3810]? Конечно! Мы даже готовы немедленно выступить с черновым списком усовершенствований:
- Центральным объектом MLDv1 выступает группа. В частности, сообщения MLDv1 относятся к одной группе (или ко всем группам сразу), а механизм подавления избыточных отчетов достигает того, что о каждой группе дается один отчет. Следовательно, накладные расходы на работу такого протокола растут пропорционально числу активных групп, а оно может быть велико, особенно если на канале в основном расположены маршрутизаторы, каждый из которых продвигает трафик многих разных групп. Напротив, число слушателей на канале вряд ли будет очень большим из чисто практических соображений. Поэтому имеет смысл перенести фокус протокола с группы на слушателя. Для начала надо переработать формат отчета так, чтобы он смог нести информацию о многих группах сразу.
- MLDv1 поддерживает только один режим группового вещания, а именно ASM. В новой версии MLD совершенно необходима поддержка SSM и SFM. О различиях между этими режимами см. §2.9.
- В MLDv1 механизм координации генератора запросов с наблюдателями находится в зачаточном состоянии. Его надо распространить на прочие важные параметры протокола: интервал между запросами, число повторов.
Аналогичные усовершенствования вошли в IGMPv3 для IPv4 [RFC 3376].
Сергей Субботин
 "
"
Павел Афиногенов
|
Курс IPv6, в тексте имеются ссылки на параграфы. Разбиения курса на параграфы нет. |