Коллективные взаимодействия процессов
В операциях коллективного взаимодействия процессов участвуют все процессы коммуникатора. Соответствующая процедура должна быть вызвана каждым процессом, быть может, со своим набором параметров. Возврат из процедуры коллективного взаимодействия может произойти в тот момент, когда участие процесса в данной операции уже закончено. Как и для блокирующих процедур, возврат означает то, что разрешен свободный доступ к буферу приема или посылки. Асинхронных коллективных операций в MPI нет.
В коллективных операциях можно использовать те же коммуникаторы, что и были использованы для операций типа точка-точка. MPI гарантирует, что сообщения, вызванные коллективными операциями, никак не повлияют на выполнение других операций и не пересекутся с сообщениями, появившимися в результате индивидуального взаимодействия процессов.
Вообще говоря, нельзя рассчитывать на синхронизацию процессов с помощью коллективных операций (кроме процедуры MPI_BARRIER ). ЕСЛИ какой-то процесс завершил свое участие в коллективной операции, то это не означает ни того, что данная операция завершена другими процессами коммуникатора, ни даже того, что она ими начата (если это возможно по смыслу операции).
В коллективных операциях не используются идентификаторы сообщений (теги). Таким образом, коллективные операции строго упорядочены согласно их появлению в тексте программы.
МРI_BARRIER(COMM, IERR) INTEGER COMM, IERR
Процедура используется для барьерной синхронизации процессов. Работа процессов блокируется до тех пор, пока все оставшиеся процессы коммуникатора сомм не выполнят эту процедуру. Только после того, как последний процесс коммуникатора выполнит данную процедуру, все процессы будут разблокированы и продолжат выполнение дальше. Данная процедура является коллективной. Все процессы должны вызвать MPI_BARRIER, хотя реально исполненные вызовы различными процессами коммуникатора могут быть расположены в разных местах программы.
В следующем примере функциональность процедуры MPI_BARRIER моделируется при помощи отложенных запросов на взаимодействие. Для усреднения результатов производится NTIMES операций обмена, в рамках каждой из них все процессы должны послать сообщение процессу с номером О, после чего получить от него ответный сигнал, означающий, что все процессы дошли до этой точки в программе. Использование отложенных запросов позволяет инициализировать посылку данных только один раз, а затем использовать на каждой итерации цикла. Далее время на моделирование сравнивается со временем на синхронизацию при помощи самой стандартной процедуры MPI_BARRIER.
program example13 include 'mpif.h'
integer ierr, rank, size, MAXPROC, NTIMES, i, it parameter (MAXPROC = 12 8,
NTIMES = 10000) integer ibuf(MAXPROC)
double precision time_start, time_finish
integer req(2*MAXPROC), statuses(MPI_STATUS_SIZE, MAXPROC) call MPI_INIT(ierr)
call MPI_COMM_SIZE(MPI_COMM_WORLD, size, ierr) call MPI_COMM_RANK
(MPI_COMM_WORLD, rank, ierr) if(rank .eq. 0) then do i = 1, size-1
call MPI_RECV_INIT(ibuf(i), 0, MPI_INTEGER, i, 5,
& MPI_COMM_WORLD, req(i), ierr)
call MPI_SEND_INIT(rank, 0, MPI_INTEGER, i, 6,
& MPI_COMM_WORLD, req(size+i),
& ierr)
end do
time_start = MPI_WTIME(ierr) do it = 1, NTIMES
call MPI_STARTALL(size-1, req, ierr)
call MPI_WAITALL(size-1, req, statuses, ierr)
call MPI_STARTALL(size-1, req(size+1), ierr)
call MPI_WAITALL(size-1, req(size+1), statuses,
& ierr)
end do else
call MPI_RECV_INIT(ibuf(1), 0, MPI_INTEGER, 0, 6,
& MPI_COMM_WORLD, req(1), ierr)
call MPI_SEND_INIT(rank, 0, MPI_INTEGER, 0, 5,
& MPI_COMM_WORLD, req(2), ierr)
time_start = MPI_WTIME(ierr) do it = 1, NTIMES
call MPI_START(req(2), ierr)
call MPI_WAIT(req(2), statuses, ierr)
call MPI_START(req(1), ierr)
call MPI_WAIT(req(1), statuses, ierr) end do end if
time_finish = MPI_WTIME(ierr)-time_start print *, 'rank = ', rank, ' all time = ', & (time_finish)/NTIMES
time_start = MPI_WTIME(ierr) do it = 1, NTIMES
call MPI_BARRIER(MPI_COMM_WORLD,ierr) enddo
time_finish = MPI_WTIME(ierr)-time_start print *, 'rank = ', rank, ' barrier time = ', &
(time_finish)/NTIMES call MPI_FINALIZE(ierr) end
MPI_BCAST(BUF, COUNT, DATATYPE, ROOT, COMM, IERR)
<type> BUF(*)
INTEGER COUNT, DATATYPE, ROOT, COMM, IERR
Листинг
4.1.
Рассылка COUNT элементов данных типа DATATYPE из массива BUF от процесса ROOT всем процессам данного коммуникатора сомм, включая сам рассылающий процесс. При возврате из процедуры содержимое буфера BUF процесса ROOT будет скопировано в локальный буфер каждого процесса коммуникатора сомм. Значения параметров COUNT, DATATYPE, ROOT и СОММ должны быть одинаковыми у всех процессов.
Следующая схема иллюстрирует действие процедуры MPI_BCAST. Здесь, также как и в дальнейших схемах по вертикали изображаются разные процессы, участвующие в коллективной операции, а по горизонтали - расположенные на них блоки данных.
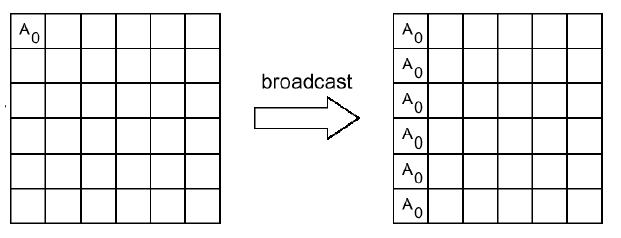
Например, для того чтобы переслать от процесса 2 всем остальным процессам приложения массив buf из 100 целочисленных элементов, нужно, чтобы во всех процессах встретился следующий вызов:
call MPI_BCAST(buf, 100, MPI_INTEGER, & 2, MPI_COMM_WORLD, ierr) MPI_GATHER(SBUF, SCOUNT, STYPE, RBUF, RCOUNT, RTYPE, ROOT, COMM, IERR) <type> SBUF(*), RBUF(*) INTEGER SCOUNT, STYPE, RCOUNT, RTYPE, ROOT, COMM, IERR
Сборка SCOUNT элементов данных типа STYPE ИЗ массивов SBUF со всех процессов коммуникатора сомм в буфере RBUF процесса ROOT. Каждый процесс, включая ROOT, посылает содержимое своего буфера SBUF процессу ROOT. Собирающий процесс сохраняет данные в буфере RBUF, располагая их в порядке возрастания номеров процессов.
На процессе ROOT существенными являются значения всех параметров, а на остальных процессах - только значения параметров SBUF, SCOUNT, STYPE, ROOT и сомм. Значения параметров ROOT и СОММ должны быть одинаковыми у всех процессов. Параметр RCOUNT у процесса ROOT обозначает число элементов типа RTYPE, принимаемых не от всех процессов в сумме, а от каждого процесса.
Следующая схема иллюстрирует действие процедуры MPI_GATHER.
