Эффективность вычислительных систем
Особенности обеспечения надежности ВС
Выше мы предположили, что для ЭВМ все сказанное бесспорно и во многом очевидно. Переход к многопроцессорным ВС требует дополнительных разъяснений.
Построение многопроцессорных ВС (в России — семейства МВК "Эльбрус") привело к пересмотру всех традиционных представлений о надежности.
С одной стороны, большой объем оборудования при недостатках элементной базы приводит к резкому возрастанию сбоев и отказов в устройствах и модулях, с другой стороны — структурная и функциональная избыточность, виртуализация ресурсов, управление распределением работ, аппаратный контроль предназначены для выполнения устойчивого вычислительного процесса.
В этих условиях подвергаются сомнению сами определения сбоя и отказа. Эти определения принимаются по согласованию между разработчиком ВС и системщиком, т.е. с учетом требований тех задач, которые должна решать ВС в составе, например, системы управления.
Вышел из строя один из 10 процессоров ВС, — отказ ли это ВС? Ответ зависит от конкретной системы, решаемых задач, временного режима их решения, от требований к производительности, принимаемых мер по обеспечению устойчивого вычислительного процесса и т.д. Произошел сбой процессора, при котором сработал малый рестарт, перезапустивший весь процесс или процесс с контрольной точки. Потери времени на этот рестарт не приведут к необратимому нарушению работы всей системы? Т.е. это — действительно сбой или отказ? Тем более сбои в работе ОС или та категория сбоев, которая приводит к перезапуску ВС — к большому рестарту: загрузке ОС и работе с начала. В "Эльбрусе-2" большой рестарт выполняется более чем за 3 секунды. К чему это отнести — к сбою или отказу? Это зависит от системы, в которой используется ВС.
Таким образом, в проблемно-ориентированных ВС проблема сбоев и отказов решается комплексно в соответствии с применением ВС.
Использование в ВС большого числа однотипных устройств с учетом идеи виртуальных ресурсов вносит особенности и в понятие резервирования. Реализуется структурное резервирование (развивает идеи скользящего резервирования), на основе которого при отказах производится реконфигурация системы: продолжение ее функционирования при изменившемся количестве устройств одной специализации. В этом смысле говорят о "живучести" системы.
В связи с изложенным, в МВК "Эльбрус-2" одним из механизмов, обеспечивающих "живучесть" комплекса, является система автоматической реконфигурации и перезапуска при сбоях и отказах (САР). Она включает в себя специальную аппаратуру, распределенную по модулям МВК, системные шины, программные средства ОС.
Аппаратно выполняются следующие действия:
- Обнаружение аварии в модуле, определение ее типа, сохранение диагностической информации и приостановка работы аварийного модуля.
- Передача информации об аварии по специальным шинам (а мы думали, что связь между модулями ВС — только через коммутатор!) в другие модули.
- Обработка сигналов аварии, приходящих от других модулей и исключение аварийного модуля из конфигурации.
- Системная реакция на аварию: либо запуск специальных процедур ОС (малый рестарт), либо перезапуск комплекса (большой рестарт).
Программно выполняются следующие действия:
- Сбор и обработка диагностической информации аварийного модуля.
- Попытка вернуть его в рабочую конфигурацию в предположении, что авария — в результате сбоя.
- Сохранение в системном журнале информации об аварии.
Таким образом, в САР предусмотрены различные реакции на разные типы аварий.
Возникновение асинхронной аварии на процессе пользователя ведет к автоматическому исключению неисправного модуля из конфигурации и к запуску процедуры ОС, обрабатывающей аварийную ситуацию и определяющей дальнейшее течение аварийного процесса — аварийное завершение или перезапуск (малый рестарт). Остальные процессы "не чувствуют" аварийной работы. Исключение составляет случай, когда в конфигурации представлен лишь один модуль некоторого типа. Возникновение в нем аварии приводит к перезапуску всего комплекса (к большому рестарту).
Возникновение асинхронной аварии на процессе ОС всегда завершается большим рестартом.
Оценка надежностных характеристик ВС при испытаниях
- Согласуют контрольную задачу (КЗ) или комплекс КЗ, с помощью которых будут производить испытание ВС. В основу КЗ берут те алгоритмы или их аналоги, которые как можно ближе соответствуют назначению ВС в составе системы управления. Хороших показателей испытаний добиваются тогда, когда в состав КЗ включают модели управляемых объектов и таким образом строят замкнутый контур управления объектом. Модели объектов могут учитывать случайные возмущения, и, следовательно, управление становится реальным. Такие КЗ наглядны, результативны, бесспорны, поскольку опираются на принцип "удача — неудача".
-
Согласуют определение основных событий и состояний. Например,
- малый рестарт считать обнаруженным сбоем с восстановлением;
- "неудачный" цикл управления считать сбоем без восстановления;
- большой рестарт считать отказом, где его время — время восстановления;
- выход из конфигурации числа процессоров, снижающих более чем на 20% производительность ВС (2 процессора из 10 в МВК "Эльбрус-2"), считать отказом;
- реконфигурацию, не снижающую более чем на 20% производительность, считать отказом с переходом на резерв;
Аналогичные соглашения принимаются и насчет памяти, внешней памяти, ПВВ и ППД, обеспечивающих выполнение КЗ.
- Объявляют прогон — циклическое непрерывное решение КЗ (комплекса КЗ) в течение значительного времени (например, 5 суток), достаточного для набора статистики.
-
Набирают статистику по ВС в целом и по группам устройств. Обычно разграничивают центральную часть и периферию. Непосредственно снимают те показатели, о которых говорилось выше:
- среднее время T0 безотказной работы;
- среднее время Tвосст восстановления;
- частоту
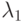 сбоев; из них — число
"восстановленных" для определения Pвосст ;
сбоев; из них — число
"восстановленных" для определения Pвосст ; - частоту
 отказов, из них — число приведших к
успешной реконфигурации для нахождения Pрез.
отказов, из них — число приведших к
успешной реконфигурации для нахождения Pрез.
По приведенным выше формулам мы можем получить необходимые показатели надежности.