Методы контекстного моделирования
Оценка вероятности ухода
На долю символов ухода обычно приходится порядка 30% и более от всех оценок, вычисляемых моделировщиком PPM. Это определило пристальное внимание к проблеме оценки вероятности символов с нулевой частотой. Львиная доля публикаций, посвященных PPM, прямо касаются оценки вероятности ухода (ОВУ).
Можно выделить два подхода к решению проблемы ОВУ: априорные методы, основанные на предположениях о природе сжимаемых данных, и адаптивные методы, которые пытаются приспособить оценку к данным. Понятно, что первые призваны обеспечить хороший коэффициент сжатия при обработке типичных данных в сочетании с высокой скоростью вычислений, а вторые ориентированы на обеспечение максимально возможной степени сжатия.
Априорные методы
Введем обозначения:
C - общее число просмотров контекста, т.е. сколько раз он встретился в обработанном блоке данных;
S - количество разных символов в контексте;
 - количество таких разных символов, что они встречались в контексте ровно i раз;
- количество таких разных символов, что они встречались в контексте ровно i раз;
 - значение ОВУ по методу x.
- значение ОВУ по методу x.
Изобретатели алгоритма PPM предложили два метода ОВУ: так называемые метод A и метод B. Использующие их алгоритмы PPM были названы PPMA и PPMB соответственно.
В дальнейшем было описано еще 5 априорных подходов к ОВУ: методы C, D, P, X и XC [8, 10, 17]. По аналогии с PPMA и PPMB, алгоритмы PPM, применяющие методы C и D, получили названия PPMC и PPMD соответственно.
Идея методов и их сравнение представлены в табл. 3.4 и табл. 3.5.
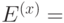
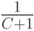


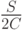
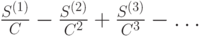
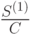
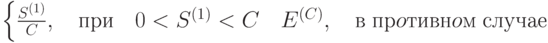 .
.Кстати, в примере 2 был использован метод A, а в компрессоре Dummy - метод С.
При реализации метода B воздерживаются от оценки символов до тех пор, пока они не появятся в текущем контексте более одного раза. Это достигается за счет вычитания единицы из счетчиков. Методы P, X, XC базируются на предположении о том, что вероятность появления в обрабатываемых данных символа 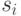 подчиняется закону Пуассона с параметром
подчиняется закону Пуассона с параметром 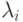 .
.
| Тип файлов | Точность предсказания | ||||||
|---|---|---|---|---|---|---|---|
| Лучше | хуже | ||||||
| Тексты | XC | D | P | X | C | B | A |
| Двоичные файлы | C | X | P | XC | D | B | A |
Места в табл. 3.5 очень условны. Так, например, при сжатии текстов методы XC, D, P, X показывают весьма близкие результаты, и многое зависит от порядка модели и используемых для сравнения файлов. В большинстве случаев существенным является только отставание точности ОВУ по способам A и B от других методов.
Адаптивные методы
Чтобы улучшить оценку вероятности ухода, необходимо иметь такую модель оценки, которая бы адаптировалась к обрабатываемым данным. Подобный адаптивный механизм получил название Secondary Escape Estimation (SEE), т.е. "дополнительной оценки ухода", или "вторичной оценки ухода". Метод заключается в тривиальном вычислении вероятности ухода из текущей КМ через частоту появления новых символов (или, что то же, символов ухода) в контекстных моделях со схожими характеристиками:
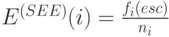
где  - число наблюдавшихся уходов из контекстных моделей типа i ;
- число наблюдавшихся уходов из контекстных моделей типа i ;
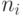 - число просмотров контекстных моделей типа i.
- число просмотров контекстных моделей типа i.
Вразумительные обоснования выбора этих характеристик и критериев "схожести" при отсутствии априорных знаний о характере сжимаемой последовательности дать сложно, поэтому известные алгоритмы адаптивной оценки базируются на эмпирическом анализе типовых данных.
Метод Z
Одна из самых ранних попыток реализации SEE известна как метод Z, а использующая его разновидность алгоритма PPM - PPMZ [3.3]. Для точности описания этой техники SEE объект "контекст" ниже будет также именоваться "PPM-контекстом".
Для нахождения ОВУ строятся так называемые контексты ухода (escape contexts) КУ, формируемые из четырех полей. В полях КУ содержится информация о значениях следующих величин: последние четыре символа PPM-контекста, порядок PPM-контекста, количество уходов и количество успешных оценок в соответствующей КМ. Нескольким КМ может соответствовать один КУ.
Информация о фактическом количестве уходов и успешных кодирований во всех контекстных моделях, имеющих общий КУ, запоминается в счетчиках контекстной модели уходов КМУ, построенной для данного КУ. Эта информация определяет ОВУ для текущей КМ. ОВУ находится путем взвешивания оценок, которые дают три КМУ (КМУ порядка 2, 1 и 0), отвечающие характеристикам текущей КМ.
КУ порядка 2 наиболее точно соответствует текущей КМ, контексты ухода порядком ниже формируются главным образом путем выбрасывания части информации из полей КУ порядка 2. Компоненты КУ порядка 2 определяются в соответствии с табл. 3.6 [3.3].
В состав КУ всех порядков входят поля 1, 2, 3. Для КУ порядка 1 поле 4 состоит из 8 битов и строится из шестых и пятых битов последних четырех обработанных символов. У КУ порядка 0 четвертое поле отсутствует. Очевидно, что алгоритм построения поля 4 для КУ порядков 1 и 2 призван улучшить предсказание ухода для текстов на английском языке в кодировке ASCII. Аналогичный прием, хотя и в не столь явном виде, используется в адаптивных методах ОВУ SEE-d1 и SEE-d2, рассмотренных ниже.
При взвешивании статистики КМУ(n) используются следующие веса 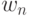
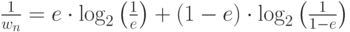 ,
,
где e - ОВУ, которую дает данная взвешиваемая КМУ(n) ; формируется из фактического количества уходов и успешных кодирований в контекстных моделях, соответствующих этой КМУ, или, иначе, определяется наблюдавшейся частотой ухода из таких КМ.
Окончательная оценка:
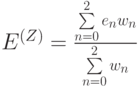 .
.
После ОВУ выполняется поиск текущего символа среди имеющихся в КМ. По результатам поиска (символ найден или нет) обновляются счетчики соответствующих трех КМУ порядка 0, 1 и 2.