|
При прохождении теста 1 в нем оказались вопросы, который во-первых в 1 лекции не рассматривались, во-вторых, оказалось, что вопрос был рассмаотрен в самостоятельно работе №2. Это значит, что их нужно выполнить перед прохождением теста? или это ошибка? |
Новосибирский Государственный Университет
Опубликован: 20.08.2013 | Доступ: свободный | Студентов: 873 / 40 | Длительность: 14:11:00
Темы: Программирование, Графика и дизайн
Специальности: Программист, Системный архитектор
Лекция 3:
Детекторы и дескрипторы ключевых точек. Алгоритмы классификации изображений. Задача детектирования объектов на изображениях и методы её решения
4. Задача детектирования объектов на изображениях и методы ее решения
4.1. Постановка задачи детектирования объектов
- Разнообразие форм и цветов представителей класса объектов. Например, в случае множества транспортных средств – это разнообразие моделей и цветов автомобилей.
- Перекрытие детектируемых объектов. Естественная ситуация, когда с точки зрения камеры объекты видны только частично, например, обозревается только крыша и ветровое стекло автомобиля.
- Разная степень освещенности объектов. В зависимости от времени суток одинаковые объекты могут выглядеть и восприниматься абсолютно по-разному.
Цель детектирования – определить наличие объекта на изображении и найти его положение в системе координат пикселей исходного изображения. Положение объекта в зависимости от выбора алгоритма детектирования может определяться координатами прямоугольника, окаймляющего объект, либо контуром этого объекта, либо координатами точек, наиболее характерных для объекта.
Решение задачи детектирования объектов позволяет анализировать качественный состав сцены, представленной на изображении, а также получить информацию о взаимном расположении объектов.
4.2. Методы решения задачи детектирования объектов
Множество всех методов решения задачи детектирования можно разделить на три основные группы:
- Методы, которые для описания объекта используют признаки, наиболее характерные для объектов. В качестве признаков могут быть выбраны точечные особенности объекта, либо признаки, построенные для изображения, содержащего только объект.
- Методы поиска объектов, соответствующих шаблону – некоторому описанию объектов.
- Методы детектирования движения объектов – выделение движущихся объектов на основании нескольких изображений или кадров видео одной и той же сцены.
4.2.1. Методы, основанные на извлечении признаков
Один из возможных подходов к решению задачи детектирования состоит в том, чтобы использовать алгоритмы машинного обучения для построения моделей классов объектов и алгоритмы вывода для поиска объектов на изображении.
Построение модели состоит из двух этапов (рис. 3.6):
- Извлечение признаков, характерных для объектов класса, – построение характеристических векторов-признаков для ключевых точек объекта (углов, ребер [ 5 ] или контуров объектов [ 100 ]) или для всего объекта.
- Тренировка модели на полученных признаках для последующего распознавания объектов.

Рис. 3.6. Схема построения модели класса с использованием методов, основанных на извлечении характерных признаков
Техники данной группы описывают объект с использованием векторов-признаков. Вектора строятся на основании цветовой информации (гистограмма ориентированных градиентов (Histogram of Oriented Gradients или HOG) – один из наиболее популярных способов). Также может быть использована контекстная информация (context based) [ 108 , 84 ], а в некоторых случаях – данные о геометрии и взаимном расположении частей объекта (part-based) [ 39 ]. Тем не менее, все эти методы строят некоторую математическую модель объекта на каждом изображении тренировочной выборки, содержащем объект. Формально признак 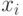 – это числовая характеристика. Для каждой ключевой точки алгоритмы данной группы строят вектор признаков
– это числовая характеристика. Для каждой ключевой точки алгоритмы данной группы строят вектор признаков  . Таким образом, объект описывается набором векторов признаков в характерных точках. В результате тренировки строится модель, содержащая "усредненные" вектора признаков.
. Таким образом, объект описывается набором векторов признаков в характерных точках. В результате тренировки строится модель, содержащая "усредненные" вектора признаков.
Алгоритм вывода (поиска) по существу включает два этапа:
- Извлечение признаков объекта из тестового изображения. При извлечении признаков возникает две основные проблемы:
- На изображении может быть много объектов одного класса, а необходимо найти всех представителей. Поэтому необходимо просматривать все части изображения, проходя "бегущим" окном (sliding window) от левого верхнего до правого нижнего угла. При этом размер окна определяется размером изображений тренировочной выборки.
- Объекты на изображении могут иметь разный масштаб. Самое распространенное решение – масштабирование изображения.
- Поиск объектов на изображении (рис. 3.7). Входными данными алгоритма поиска являются формальное описание объекта – набор признаков, которые выделены из тестового изображения, – и модель класса объектов. На основании этой информации классификатор принимает решение о принадлежности объекта классу. Некоторые методы поиска также оценивают степень достоверности того, что объект принадлежит рассматриваемому классу.

Рис. 3.7. Схема поиска объектов с использованием методов, основанных на извлечении характерных признаков
Качество рассматриваемых методов в основном зависит от того, насколько хорошо выбраны признаки, т.е. насколько хорошо эти признаки дифференцируют классы объектов. Существуют специализированные методы, основанные на извлечении признаков, для детектирования лиц [ 114 , 113 , 92 ], транспортных средств [ 4 ] и пешеходов [ 26 , 115 , 49 ].
4.2.2. Методы поиска по шаблону
Детектирование объектов на основании некоторого шаблона предполагает, что имеется изображение объекта с выделенными признаками – шаблон – и тестовое изображение, которое сопоставляется этому шаблону.

Рис. 3.8. РСхема решения задачи детектирования объектов с использованием методов поиска объектов по шаблону
Результатом такого сопоставления (matching) [ 105 ] является мера сходства (рис. 3.8). Считается, что если эта мера больше некоторого порога, то тестовое изображение – это изображение объекта.
В простейшем случае в качестве шаблона может выступать изображение объекта – матрица интенсивности цветов, наиболее характерных для объекта. Более сложные методы рассматриваемой группы в качестве шаблона используют наборы векторов признаков (дескрипторы), геометрическое представление объекта [ 56 ] или вероятностные модели объектов, которые содержат информацию о распределениях интенсивностей пикселей [ 5 ].
В процессе поиска осуществляется проход "бегущим окном", имеющим размеры шаблона, по изображению и сравнение описания части исходного изображения, покрываемого окном, и шаблона. Сопоставление с шаблоном подразумевает сравнение описание тестового и шаблонного изображений по некоторой выбранной метрике [ 147 ], как правило, выбирается Евклидово расстояние, норма 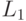 , взвешенная свертка квадратичных ошибок, либо корреляция [ 105 ].
, взвешенная свертка квадратичных ошибок, либо корреляция [ 105 ].
Допустим, что задано шаблонное описание объекта 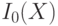 в дискретном пространстве пикселей
в дискретном пространстве пикселей  . Тогда задача поиска объекта сводится к задаче минимизации суммарной ошибки. Если в качестве меры сходства использовано Евклидово расстояние, то задача может быть записана следующим образом:
. Тогда задача поиска объекта сводится к задаче минимизации суммарной ошибки. Если в качестве меры сходства использовано Евклидово расстояние, то задача может быть записана следующим образом:
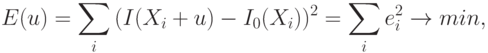
где  – смещение шаблонного описания в системе координат исходного изображения. В конечном итоге, независимо от выбранной метрики приходим к задаче оптимизации.
– смещение шаблонного описания в системе координат исходного изображения. В конечном итоге, независимо от выбранной метрики приходим к задаче оптимизации.
Для алгоритмов, которые используют сопоставление дескрипторов ключевых точек, одним из наиболее важных является вопрос выбора порога, используемого в качестве критерия соответствия (в простейшем случае, если расстояние между дескрипторами меньше данного порога, точки считаются соответствующими). Увеличение данного порога приводит, с одной стороны, к увеличению числа найденных совпадений (true positives), с другой стороны, к увеличению числа ложных срабатываний (false positives). Уменьшение же порога наряду с ростом числа правильно продетектированных несовпадений (true negatives) ведет к росту числа правильных соответствий, которые были отброшены (false negatives). Данная зависимость графически отображается с помощью ROC-кривой [ 105 ] – по величине площади под данной кривой (AUC – area under curve) можно судить о качестве выбранного алгоритма построения соответствий между ключевыми точками на разных изображениях.
Отметим, что методы детектирования по заданному шаблону эффективно работают при поиске одиночных объектов. При возникновении перекрытий в "бегущем окне" исчезают некоторые признаки в описании. Поэтому при сопоставлении окна шаблону вводится порог, по которому отсекаются неперспективные окна – окна, заведомо не содержащие объектов.
Александра Максимова
Алена Борисова
|
В лекции по обработке полутоновых изображений (http://www.intuit.ru/studies/courses/10621/1105/lecture/17979?page=2) увидела следующий фильтр:
В описании говорится, что он "делает изображение более чётким, потому что, как видно из конструкции фильтра, в однородных частях изображение не изменяется, а в местах изменения яркости это изменение усиливается". Что вижу я в конструкции фильтра (скорее всего ошибочно): F(x, y) = 2 * I(x, y) - 1/9 I(x, y) = 17/9 * I(x, y), где F(x, y) - яркость отфильтрованного пикселя, а I(x, y) - яркость исходного пикселя с координатами (x, y). Что означает обычное повышение яркости изображения, при этом без учета соседних пикселей (так как их множители равны 0). Объясните, пожалуйста, как данный фильтр может повышать четкость изображения? |
