|
не хватает одного параметра: static void Main(string[] args) |
Опубликован: 23.04.2013 | Доступ: свободный | Студентов: 860 / 186 | Длительность: 12:54:00
Лекция 4:
Параллельные алгоритмы
Суммирование
Начнем с простейшей задачи - вычисление суммы элементов массива:
 |
( 3.1) |
Классический алгоритм выглядит так:
S = 0; for(int i = 0; i < n; i++) S = S + x[i];Листинг 3.1. Последовательный алгоритм вычисления суммы элементов массива
Алгоритм последовательный и не допускает распараллеливания, поскольку на каждом шаге цикла используется значение S, вычисленное на предыдущем шаге. Заметьте, цикл не допускает распараллеливания, если в теле цикла есть оператор присваивания, у которого одна и та же скалярная переменная встречается как в левой, так и в правой части оператора (S в нашем примере).
Поскольку в алгоритме используется только один цикл типа for с шагом, равным единица, то алгоритм имеет линейную временную сложность:
 |
( 3.2) |
Когда суммирование должен выполнять только один процессор, то это оптимальный по времени алгоритм. Но суммирование можно вести самыми разными способами, если к вычислению суммы привлечь несколько процессоров. В "Параллельные вычисления" мы уже анализировали "пирамидальный" алгоритм суммирования, допускающий распараллеливание. Вот возможная запись такого алгоритма на С#:
int[] y = new int[n];
Array.Copy(x, y, n);
int m = n;
while (m != 1)
{
for (int i = 0, j = m - 1; i < j; i++, j--)
y[i] = y[i] + y[j];
m = (m + 1) / 2;
}
S = y[0];
Листинг
3.2.
Пирамидальный алгоритм вычисления суммы элементов массива
В этом более сложном варианте алгоритма появились два цикла. Внутренний цикл for может быть распараллелен. Нетрудно видеть, что множества переменных, используемых на каждой итерации этого цикла, взаимно не пересекаются. Выполнение этого условия достаточно для распараллеливания. Внешний цикл while распараллелить нельзя, поскольку итерации "склеиваются" общей переменной m.
Для компьютера с одним процессором этот алгоритм будет хуже классического алгоритма по ряду причин:
- Ему нужна дополнительная память, поскольку промежуточные результаты необходимо запоминать. Для этого введен массив y той же размерности, что и исходный массив x.
- Алгоритм усложнен, - вместо одного цикла классического алгоритма, вводятся два цикла. Алгоритм менее понятен и отладка его может вызывать затруднение. Несомненно, что программисту потребуется больше времени на разработку и отладку такого алгоритма.
- Алгоритм при последовательном выполнении хотя и имеет ту же временную сложность - O(n), но константа у него больше, чем у классического алгоритма, поскольку во внутреннем цикле используются три переменные с индексами, вместо одной, как в классическом алгоритме.
В чем же достоинство этого алгоритма? Одно несомненное достоинство у него есть - он допускает распараллеливание. Если запускать его на идеальном метакомпьютере с неограниченным числом процессоров, то тогда, используя n/2 процессоров, все вычисления внутреннего цикла можно выполнять параллельно.
Сложность внутреннего цикла при распараллеливании будет равна O(1), а общая сложность определяется внешним циклом и равна O(log n). В "Параллельные вычисления" , где этот алгоритм уже анализировался, помимо ускорения в рассмотрение вводилась и такая характеристика алгоритма как эффективность. У пирамидального алгоритма эффективность низкая, поскольку для достижения максимального ускорения требуется n/2 процессоров - число, пропорциональное размерности массива. Метакомпьютеры и даже суперкомпьютеры с большим числом процессоров не всегда под рукой, но и при их наличии приходится заботиться об эффективности.
Давайте рассмотрим алгоритмы суммирования, ориентированные на конечное число процессоров - на многоядерные компьютеры. Пусть в нашем распоряжении есть компьютер с фиксированным числом процессоров - р. Как выполнить суммирование, используя все возможности такого компьютера? Естественный алгоритм, допускающий распараллеливание, понятен, - нужно провести распараллеливание по данным, разбив исходный массив на р групп, примерно равной размерности. Тогда можно параллельно выполнить суммирование для каждой группы, после чего просуммировать полученные результаты. И в этом случае понадобится дополнительная память - массив размерности р, хранящий результаты промежуточных сумм.
Разбиение массива на группы можно выполнить разными способами. Разумными представляются две стратегии. Первая состоит в том, чтобы исходный массив нарезать на р отрезков и поручить каждому процессору суммирование элементов соответствующего отрезка. Вторая стратегия основана на том, чтобы каждый процессор суммировал элементы, отстоящие на расстоянии р. Если соответствующим образом выбрать начальный элемент для каждого процессора, то это позволит вести параллельное суммирование.
Вот вариант записи сегментного алгоритма, соответствующего первой стратегии:
int count_p = Environment.ProcessorCount;
int[] y = new int[count_p];
int m = n / count_p + 1;
int start = 0, finish = 0;
for(int k =0; k < count_p; k++)
{
start = k * m;
finish = (k+1)*m < n ? (k+1)*m : n;
for (int i = start; i < finish; i++)
y[k] += x[i];
}
S = y[0];
for (int i = 1; i < count_p; i++)
S += y[i];
Листинг
3.3.
Сегментный алгоритм вычисления суммы p процессорами
Чуть проще шаговый алгоритм, соответствующий второй стратегии:
int[] y = new int[count_p];
for (int k = 0; k < count_p; k++)
{
for (int i = k; i < n; i += count_p)
y[k] += x[i];
}
S = y[0];
for (int i = 1; i < count_p; i++)
S += y[i];
Листинг
3.4.
Шаговый алгоритм вычисления суммы p процессорами
Оба эти варианта допускают параллельное выполнение тела внешнего цикла. В этом случае сложность алгоритма определяется сложностью операторов, составляющих тело этого цикла, фактически, сложностью внутреннего цикла - O(n/count_p). Ускорение для обоих вариантов равно count_p - числу процессоров, а эффективность равна единице. Таковы теоретические оценки. В последующих главах посмотрим, что можно получить на практике.
Задача суммирования крайне важна, поскольку встречается в самых разных приложениях. Она легко обобщается на случай, когда суммируются не элементы массива, а функции, зависящие от параметра i:
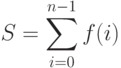 |
( 3.3) |
Все, что сказано о суммировании, касается и других подобных задач - нахождение произведения элементов массива, максимального или минимального элемента и других задач этого класса.
Суммирование рядов
Нахождение суммы конечного ряда принципиально не отличается от нахождения суммы элементов массива. Поговорим о том, как вычислять сумму бесконечного сходящегося ряда:
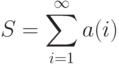 |
( 3.4) |
Необходимым условием сходимости ряда является стремление  к нулю, когда i стремится к бесконечности. В программировании это условие, в отличие от математики, является и достаточным условием сходимости. В математике это не так, - примером является расходящийся гармонический ряд с общим членом ряда 1/i. В мире компьютеров все дискретно, нет иррациональности, нет бесконечности, вычисления не всегда точны и могут иметь некоторую погрешность. При нахождении на компьютере суммы гармонического ряда, начиная с некоторого i*, значение общего члена станет равным нулю (так называемому машинному нулю) из-за ограниченности разрядной сетки, отводимой для хранения числа.
к нулю, когда i стремится к бесконечности. В программировании это условие, в отличие от математики, является и достаточным условием сходимости. В математике это не так, - примером является расходящийся гармонический ряд с общим членом ряда 1/i. В мире компьютеров все дискретно, нет иррациональности, нет бесконечности, вычисления не всегда точны и могут иметь некоторую погрешность. При нахождении на компьютере суммы гармонического ряда, начиная с некоторого i*, значение общего члена станет равным нулю (так называемому машинному нулю) из-за ограниченности разрядной сетки, отводимой для хранения числа.
В программировании не ставится задача вычисления точного значения S в формуле (3.4), - достаточно вычислить это значение с некоторой точностью. В сравнении с конечными суммами дополнительная сложность в построении алгоритма состоит в том, что заранее неизвестно, сколь много членов ряда необходимо вычислить, чтобы найти сумму ряда с нужной точностью. Классический алгоритм основан на том, что суммирование прекращается, как только очередной член суммы становится по модулю меньше заданной точности 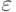 . При этом предполагается, что выполняется условие сходимости ряда, так что все не учитываемые члены ряда будут по модулю заведомо меньше .
. При этом предполагается, что выполняется условие сходимости ряда, так что все не учитываемые члены ряда будут по модулю заведомо меньше .
Вот пример записи такого алгоритма:
double eps = 1E-15;
double i = 1;
double a = 1;
double S = 0;
while (Math.Abs(a) > eps)
{
//Вычисление общего члена ряда
a = 1.0 / ((4 * i + 1) * (4 * i - 1)); // пример
S += a;
i++;
}
Листинг
3.5.
Классический алгоритм вычисления суммы сходящегося ряда
С программистской точки зрения алгоритмы 3.1 и 3.5 во многом схожи. Разница в том, что в первом случае используется цикл for, во-втором - цикл while. Из-за этого различия труднее оценить временную сложность алгоритма, поскольку нет такого естественного параметра как n в алгоритме 3.1. Число суммирований зависит как от формулы, задающей общий член ряда, так и от выбранной точности вычислений - .
Другой подход к вычислению суммы сходящегося ряда состоит в том, чтобы вместо точности задавать N - число суммируемых элементов, сводя исходную задачу к задаче вычисления суммы конечного ряда. Иногда алгоритм усложняют, вводя дополнительный цикл while, в котором на каждом шаге цикла N увеличивается, например, вдвое. Цикл заканчивается, когда два последующих вычисленных значений суммы отличаются на величину, меньшую заданной точности . Оценить временную сложность такого алгоритма затруднительно.
Вернемся к рассмотрению алгоритма 3.5. По уже указанным причинам он не допускает распараллеливания. Но, как и для вычисления конечных сумм, нетрудно построить допускающую распараллеливание версию, ориентированную на p процессоров. Для конечных сумм мы рассматривали два варианта - сегментный и шаговый алгоритм.
Сегментный алгоритм требует нарезки на сегменты примерно равной длины, для этого нужно знать N - число суммируемых элементов. Поэтому этот вариант алгоритма следует применять тогда, когда заранее выбирается N.
Модификацию шагового алгоритма, допускающего распараллеливание, выполнить несложно. Для каждого процессора нужно задать начальное значение, после чего процессор будет вести суммирование, пока общий член не станет меньше заданной точности .
double i = 1;
double a = 0;
double[] y = new double[count_p];
for (int k = 0; k < count_p; k++)
{
i = k+1;
a = 1.0 / ((4 * i + 1) * (4 * i - 1)); //начальное значение
while (Math.Abs(a) > eps)
{
y[k] += a;
i += count_p ;
a = 1.0 / ((4 * i + 1) * (4 * i - 1));
}
}
S = y[0];
for (int k = 1; k < count_p; k++)
S += y[k];
Листинг
3.6.
Шаговый алгоритм вычисления суммы сходящегося ряда p процессорами
Алексей Рыжков
Никита Белов
|
Выставил оценки курса и заданий, начал писать замечания. После нажатия кнопки "Enter" окно отзыва пропало, открыть его снова не могу. Кнопка "Удалить комментарий" в разделе "Мнения" не работает. Как мне отредактировать недописанный отзыв? |