Средства разработки и прикладное программное обеспечение
Набор компиляторов GNU ( gcc/g77 ) доступен бесплатно для всех основных аппаратных платформ, на которых строятся кластеры. Однако по производительности эти компиляторы нередко отстают от коммерческих вариантов - Intel C/Fortran Compiler, PGI Compiler, PathScale EcoPath, Absoft и других. Все эти продукты можно запросить у производителей и протестировать бесплатно на своей конкретной задаче и платформе, а после чего уже решать, стоит ли покупать и переходить на один из них. Если кластер строится на основе многоядерных процессоров, то обратите внимание, поддерживается ли многоядерность в выбранном компиляторе, в частности, есть ли поддержка технологии OpenMP.
Если принято решение установить коммерческий компилятор, то перед заказом внимательно изучите условия лицензирования. Одни лицензии позволяют запустить не более, чем оговоренное в лицензии число процессов компиляции одновременно, другие варианты ограничивают круг пользователей, которым разрешена компиляция.
Компилятор достаточно установить только на головном узле и покупать лицензии на все узлы не нужно. Если компилятор использует свои динамические библиотеки (так это делает, например, компилятор компании Intel), то их надо скопировать на вычислительные узлы и прописать к ним пути в файле /etc/ld.so.conf, после чего запустить на узлах команду ldconfig. Заметим, что это надо сделать обязательно, так как при запуске параллельных программ на узлах не отрабатывают скрипты типа /etc/profile или ~/.bash_profile, а значит и не будут прописаны пути к библиотекам через переменную LD_LIBRARY_PATH, как это делается в штатных скриптах, поставляемых с большинством компиляторов.
Вопрос с лицензиями на программное обеспечение нужно изучить очень аккуратно, поскольку он тесно связан с планированием бюджета всего проекта. Существует несколько видов лицензий для программ и программных пакетов для кластеров, причем нередко один и тот же пакет может поставляться с различными вариантами лицензий, учитывающих:
- число процессоров или узлов,
- фиксированный круг пользователей и рабочих мест,
- число одновременно запущенных копий программного продукта.
Как мы уже обсуждали, для компилятора не нужно покупать лицензии на все узлы кластера. Если людей, занимающихся разработкой программ, немного и их круг не будет меняться ближайший год-два, то можно купить лицензию с фиксированным числом пользователей. Если такой уверенности нет, то подумайте о варианте лицензии на одновременную компиляцию одним-двумя пользователями. Такой вариант на практике используется достаточно часто.
Для специализированных параллельных вычислительных пакетов или библиотек может потребоваться лицензия, в которой нужно будет явно указать максимальное число процессоров, доступных для работы пакета. Стоимость лицензии для больших конфигураций может оказаться внушительной: десятки и сотни тысяч долларов, поэтому еще раз советуем внимательно изучить условия лицензирования всех коммерческих пакетов, планируемых к использованию. Нужно найти оптимальный компромисс между удобством работы пользователей, эффективностью решения задач кластерного проекта и стоимостью устанавливаемого ПО.
Если говорить о средах параллельного программирования, то на практике это, как правило, различные варианты MPI. Не рекомендуем устанавливать параллельную среду из пакетов, поставляемых вместе с дистрибутивом Linux. Как правило, эти варианты плохо оптимизированы, и настроить их на эффективную работу с кластером очень непросто. Детали и особенности установки наиболее популярных реализаций MPI приведены в "Приложении 2" .
Проведя установку параллельной среды, убедитесь в том, что она
работоспособна. Для этого воспользуйтесь стандартными тестами,
поставляемыми практически со всеми дистрибутивами MPI. Скомпилируйте
командой make простейшую программу, которой обычно является программа cpi.с параллельного вычисления числа 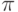 . Затем скопируйте ее в каталог
на сетевом диске и перейдите в него. Теперь можно выполнить команду mpirun -np N ./cpi, где N - это число процессоров, на которых будет
запускаться задача.
. Затем скопируйте ее в каталог
на сетевом диске и перейдите в него. Теперь можно выполнить команду mpirun -np N ./cpi, где N - это число процессоров, на которых будет
запускаться задача.
Если все прошло успешно, нужно провести более серьезную проверку - тестирование производительности. Сюда входит тестирование скорости передачи данных и величины латентности коммуникационной сети, а также определение производительности всего кластера на тестах типа Unpack или НРСС.
Скорость передачи данных и латентность можно измерить пакетом mpi-benchsuite, доступным по адресу: http://parallel.ru/ftp/tests/mpi-bench-suite.zip
Распакуйте архив, исправьте файл конфигурации config/make.def, если это нужно, и соберите исполняемые файлы командой make. В каталоге bin появятся файлы отдельных тестов transf1, ..., transf5, mpitest, nfstest и nettest. Сейчас для нас наиболее интересны transfl (блокирующая передача данных) и mpitest (тестирование основных операций MPI).
Для тестирования скорости передачи воспользуйтесь transfl на двух узлах. Используйте параметры запуска "ml M1024000 T5". Параметр ml предписывает начать замеры с сообщения длиной в 1 байт, M1024000 - остановиться на длине сообщений в 1024000 байт, T5 - повторить каждую передачу 5 раз (для набора статистики и повышения точности измерения). Более подробно все параметры описаны в документации к данному пакету.
Результаты будут выданы на экран, где будет показана скорость передачи данных по коммуникационной сети (в Мбайт/с). Можно посмотреть динамику изменения скорости в зависимости от длины сообщения, что будет полезно в дальнейшем при проектировании новых или адаптации существующих параллельных приложений на данном кластере.
Латентность, возникающая при передаче сообщений, измеряется этим же тестом transfl с параметрами "m0 M0 T10".
Хорошим вариантом тестирования производительности системы является использование пакета Intel MPI Benchmarks, ранее известного под названием Pallas MPI Benchmarks. Пакет измеряет базовые характеристики кластерной системы, а также показывает эффективность основных функций MPI, предназначенных для реализации коллективных операций и передачи сообщений между двумя процессами, односторонних операций, функций для выполнения операций ввода/вывода и ряда других.
Некоторое представление о работе кластера в целом даст измерение производительности его работы на тесте Linpack. В принципе, это отдельная большая тема, обсуждать которую можно очень долго. Сам тест является программой решения системы линейных уравнений, поэтому если что-то подобное является вычислительным ядром большинства будущих приложений, то некоторую оценку эффективности их работы на кластере получить можно. Чаще всего данный тест используют для того, чтобы убедиться в отсутствии явных проблем в работе аппаратуры и настройках программного обеспечения кластера. Для сборки теста под конкретную платформу потребуется хорошо оптимизированная библиотека BLAS и собственно исходные тексты теста High Performance Linpack (http://www.netlib.org/benchmark/hpl/). Все эти компоненты необходимо скомпилировать, используя установленную библиотеку MPI, и провести серию запусков с различными входными параметрами, которые и покажут максимально достигаемую на данном тесте производительность.
Более подробное описание процесса сборки и запуска теста Linpack представлено в "Приложении 3" . Если хочется быстро получить представление о работе кластерной системы, то можно воспользоваться пакетом HPL, уже собранным с библиотекой MKL: http://www3.intel.com/cd/software/products/asmo-na/eng/perflib/mkl/266857.htm. Заметим, что работать он будет только на процессорах Intel. В этом же пакете есть программа nodeperf, которую желательно запустить перед самим тестом для предварительной оценки производительности узлов на операции типа DGEMM.
Неплохим показателем работы кластера на множестве разных приложений могут служить данные, полученные на тестах пакета НРС Challenge Benchmark, (HPCC, http://icl.cs.utk.edu/hpcc/). Пакет объединяет несколько приложений с разными свойствами, что позволяет выполнить более детальный анализ эффективности работы кластера. В частности, в состав пакета входит тест Linpack и несколько программ для определения базовых характеристик коммуникационной среды. Тест DGEMM (умножение матриц) показывает скорость выполнения операций с плавающей запятой над данными с двойной точностью. Тест STREAM измеряет соответствие между скоростью работы процессора и скоростью извлечения данных из памяти. Всего в состав HPCC в настоящее время включено семь различных наборов тестов.
Если планируется использовать специализированные прикладные пакеты и программы, то имеет смысл провести серию дополнительных тестовых испытаний. Практически каждый пакет содержит в своем дистрибутиве набор тестовых задач, проверяющих и правильность его установки, и эффективность его работы в конкретной программно-аппаратной среде. Запустите тесты и сравните с эталонными результатами. Если обнаружилось неожиданное расхождение, то необходимо провести дополнительное исследование и выяснить причину, прежде чем отдавать инструментарий в эксплуатацию в штатном режиме.
Кстати, отметим интересный и немаловажный факт: всю работу по тестированию кластерной системы, начиная от базового уровня до проверки эффективности работы сложных прикладных пакетов, может (а иногда и должен) выполнить поставщик оборудования. Просто заложите требование предоставления документального подтверждения достигнутых показателей эффективности работы необходимого программного обеспечения в условия тендера или контракта на поставку, и часть забот по оптимизации настроек кластерной системы перейдет на поставщика. Шаг достаточно очевидный, но редко используемый на практике.
Если кластерная система будет интенсивно использоваться для создания нового программного обеспечения, то очень важно предоставить набор эффективных инструментальных средств разработки. Компиляторы, отладчики, профилировщики, трассировщики, анализаторы и системы исследования специальных свойств программ - все это в какой-то момент потребуется и будет с благодарностью воспринято пользователями. Разработка параллельного программного обеспечения является делом непростым и требует целого множества вспомогательных инструментов.