|
Есть такие задания, и они никак не принимаются. Притом ошибки только по этим заданиям, в какой бы последовательности я их не заполнял. Как их заполнять??? Инструкций в заданиях нет. Там через запятые, подряд как число, через пробел, или надо текст весь писать через запятую или точку? Задание: Пронумеруйте шаги Создание имени путем выделения ячеек на листе: |
Инспектор
Вы можете этот курс.
Опубликован: 26.05.2021 | Уровень: для всех | Доступ: платный
Лекция 13:
Прогнозирование. Регрессионный анализ, его реализация и прогнозирование
< Лекция 12 || Лекция 13 || Лекция 14 >
Аннотация:
Цель работы: научиться выполнять прогнозирование экономических параметров с помощью одномерного и многомерного регрессионного анализа.
Содержание работы:
Линейный одномерный регрессионный анализ.
Экспоненциальный одномерный регрессионный анализ.
Линейный многомерный регрессионный анализ.
Порядок выполнения работы:
Изучить методические указания.
Выполнить задания.
Оформить отчет и ответить на контрольные вопросы.
МЕТОДИЧЕСКИЕ РЕКОМЕНДАЦИИ
Сущность метода регрессионного анализа
Одним из методов, используемых для прогнозирования, является регрессионный анализ.
Регрессия – это статистический метод, который позволяет найти уравнение, наилучшим образом описывающее совокупность данных, заданных таблицей.
На графике данные отображаются точками. Регрессия позволяет подобрать к этим точкам кривую у=f(x), которая вычисляется по методу наименьших квадратов и даёт максимальное приближение к табличным данным.
По полученному уравнению можно вычислить (сделать прогноз) значение функции у для любого значения х , как внутри интервала изменения х из таблицы(интерполяция), так и вне его (экстраполяция).
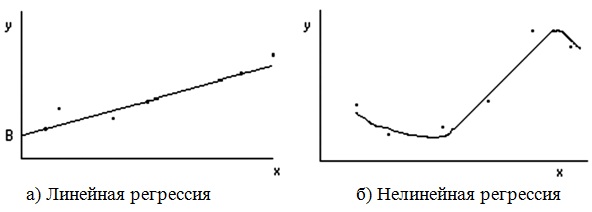
Линейная регрессия
Линейная регрессия дает возможность наилучшим образом провести прямую линию через точки одномерного массива данных (рис.13.1 а). Уравнение с одной независимой переменной, описывающее прямую линию, имеет вид:
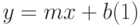
где:x – независимая переменная;
y – зависимая переменная;
m – характеристика наклона прямой;
b – точка пересечения прямой с осью у.
Например, имея данные о реализации товаров за год с помощью линейной регрессии можно получить коэффициенты прямой (1) и, предполагая дальнейший линейный рост, получить прогноз реализации на следующий год.
Нелинейная регрессия
Нелинейная регрессия позволяет подбирать к табличным данным нелинейное уравнение (рис. 13.1 рис. 13.1, б.) – параболу, гиперболу и др. Excel реализует нелинейность в виде экспоненты, т.е. подбирает кривую вида:
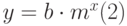 ,
,
которая позволяет наилучшим образом провести экспоненциальную кривую по точкам данных, которые изменяются нелинейно.
Так, например, данные о росте населения почти всегда лучше описываются не прямой линией, а экспоненциальной кривой. При этом нужно помнить, что достоверное прогнозирование возможно только на участках подъёма или спуска кривой (при отрицательных значениях х), т.к. сама кривая (2) изменяется монотонно, без точек перегиба. Например, делать экспоненциальный прогноз для функции, изменяющейся синусоидально, можно только на участках подъёма или спуска функции, для чего её разбивают на соответствующие интервалы.
Множественная регрессия
Множественная регрессия представляет собой анализ более одного набора данных аргумента х и даёт более реалистичные результаты.
Множественный регрессионный анализ также может быть как линейным, так и экспоненциальным. Уравнение регрессии (1) и (2) примут соответственно вид (3) и (4):
![\[m_{1}x_{1}+m_{2}x_{2}+...+m_{n}x_{n}+b\eqno(3)\]](/sites/default/files/tex_cache/e37e0a0172a435fc9a8c9d9609db4f3d.png) |
( 3) |
![\[y=b\cdot m_{1}^{x1}\cdot m_{2}^{x2}...\cdot m_{n}^{xn}\eqno(4)\]](/sites/default/files/tex_cache/a3d0dfde3241b043abefec27db783b84.png) |
( 4) |
где: х1,х2, …, хn – независимые переменные.
С помощью множественной регрессии, например, можно оценить стоимость дома в некотором районе, основываясь на данных его площади, размерах участка земли, этажности, вида из окон и т.д.
Использование функций регрессии
В Excel имеется 5 функций для линейной регрессии: ЛИНЕЙН(…)(LINEST), ТЕНДЕНЦИЯ(…), ПРЕДСКАЗ(…), НАКЛОН(…), СТОШУХ(…)) и 2 функции для экспоненциальной регрессии – ЛГРФПРИБЛ(…) и РОСТ(…).
Рассмотрим некоторые из них.
Функция ЛИНЕЙН((LINEST) вычисляет коэффициент m и постоянную b для уравнения прямой (1). Синтаксис функции:
=ЛИНЕЙН(изв._знач._у;изв._знач._х;конст;стат) (5)
Известные_значения_у и известные_значения_х – это множество значений у и необязательное множество значений х (их вводить необязательно), которые уже известны для соотношения (1).
Константа – это логическое значение, которое указывает, требуется ли, чтобы константа b была равна 0. Если константа имеет значение ИСТИНА или опущено, то b вычисляется обычным образом.
Статистика – это логическое значение, которое указывает требуется ли вывести дополнительную статистику по регрессии.
Если статистика имеет значение ЛОЖЬ (или 0), то функция ЛИНЕЙН возвращает только значения коэффициентов m и b, в противном случае выводится дополнительная регрессионная статистика в виде табл. 13.1 таблица 13.1:
| mn | mn-1 | … | m2 | m1 | b |
|---|---|---|---|---|---|
| sen | sen-1 | … | se2 | se1 | seb |
| r2 | sey | … | #Н/Д | #Н/Д | #Н/Д |
| F | df | … | #Н/Д | #Н/Д | #Н/Д |
| ssreg | ssresid | … | #Н/Д | #Н/Д | #Н/Д |
где: se1, se2,…,sen – стандартные значения ошибок для коэффициентов m1, m2,…, mn;
seb – стандартное значение ошибки для постоянной b (seb равно #Н/Д, т.е. "нет допустимого значения", если конст. имеет значение ЛОЖЬ);
r2 – коэффициент детерминированности. Сравниваются фактические значения у и значения, получаемые из уравнения прямой; по результатам сравнения вычисляется коэффициент детерминированности, нормированный от 0 до 1. Если он равен 1, то имеет место полная корреляция с моделью, т.е. нет различия между фактическим и оценочным значениями у. В противоположном случае, если коэффициент детерминированности равен 0, то уравнение регрессии неудачно для предсказания значений у;
sey – стандартная ошибка для оценки у (предельное отклонение для у);
F – F-cтатистика, или F-наблюдаемое значение. Она используется для определения того, является ли наблюдаемая взаимосвязь между зависимой и независимой переменными случайной или нет;
df – степени свободы. Степени свободы полезны для нахождения F-критических значений в статистической таблице. Для определения уровня надёжности модели нужно сравнить значения в таблице с F-статистикой, возвращаемой функцией ЛИНЕЙН;
ssreg – регрессионная сумма квадратов;
ssresid – остаточная сумма квадратов;
#Н/Д – ошибка, означающая "нет доступного значения".
Любую прямую можно задать её наклоном m и у-пересечением:
Наклон (m). Для того, чтобы определить наклон прямой, обычно обозначаемый через m, нужно взять 2 точки прямой (х1,у1) и (х2,у2); тогда наклон равен m=(y2-y1)/(x2-x1).
у-пересечение (b) прямой, обычно обозначаемое через b, является значение у для точки, в которой прямая пересекает ось у.
Уравнение прямой имеет вид: у=mx+b. Если известны значения m и b, то можно вычислить любую точку на прямой, подставляя значения у или х в уравнение. Можно также использовать функцию ТЕНДЕНЦИЯ (TREND) (см. ниже).
Если для функции у имеется только одна независимая переменная х, можно получить наклон и у-пересечение непосредственно, используя следующие формулы:
Наклон m:
ИНДЕКС(ЛИНЕЙН(изв_знач_у;изв_знач_х); 1);
у-пересечение b:
ИНДЕКС(ЛИНЕЙН(изв_знач_у;изв_знач_х); 2).
Точность аппроксимации с помощью прямой, вычисленной функцией ЛИНЕЙН, зависит от степени разброса данных. Чем ближе данные к прямой, тем более точными являются модель, используемая функцией ЛИНЕЙН, и значения, получаемые из уравнения прямой.
В случае экспоненциальной регрессии аналогом функции (5) является функция ЛГРФПРИБЛ(LOGEST):
=ЛГРФПРИБЛ(изв_знач_у;изв_знач_х;конст;стат), (6)
которая отличается лишь тем, что вычисляет коэффициенты m и b для экспоненциальной кривой (2).
Функция ТЕНДЕНЦИЯ(TREND) имеет вид:
=ТЕНДЕНЦИЯ(изв_знач_у;изв_знач_х;нов_знач_х;конст) (7)
возвращает числовые значения, лежащие на прямой линии, наилучшим образом аппроксимирующие известные табличные данные.
Новые_значения_х – это те, для которых необходимо вычислить соответствующие значения у.
Если параметр новые_значения_х пропущен, то считается, что он совпадает с известными х. Назначение остальных параметров функции ТЕНДЕНЦИЯ совпадает с описанными выше.
В случае экспоненциальной регрессии аналогом функции (7) является функция РОСТ(GROWTH):
=РОСТ(изв_знач_у;изв_знач_х;конст). (8)
Функция СТОШУХ
=СТОШУХ(изв_знач_у;изв_знач_х) (9)
возвращает стандартную погрешность регрессии – меру погрешности предсказываемого значения у для заданного значения х.
Правила ввода функций
Формулы(5)-(8) являются табличными, т.е. они заменяют собой несколько обычных формул и возвращают не один результат, а массив результатов. Поэтому необходимо соблюдать следующие правила:
- Перед вводом одной из формул (5)-(8) выведите блок ячеек, точно совпадающей по размеру с величиной возвращаемого формулой массива результатов. Например, при использовании функции ЛИНЕЙН с выводом статистики нужно выделить массив ячеек, равный табл. 13.1, если параметр статистики равен ЛОЖЬ, достаточно выделить одну строку табл. 13.1.
- Наберите функцию в строке формул. При этом слова на русском языке можно набирать строчными буквами, т.к. они являются ключевыми и при вводе Exсel автоматически переведет их в заглавные. Имена ячеек автоматически вводятся латинским шрифтом. Вместо слова ИСТИНА можно вводить числа от 1 до 9 (не 0), а вместо слова ЛОЖЬ – число 0. Если в результате, выполнения функции выводится одно число, можно вводить формулы не вручную, а использовать аппарат Мастера функций.
- Одновременно нажмите клавиши Shift+Ctrl+Enter. Результаты вычислений заполнят выделенные ячейки.
Линия тренда
Excel позволяет наглядно отображать тенденцию данных с помощью линии тренда, которая представляет собой интерполяционную кривую, описывающую отложенные на диаграмме данные.
Для того, чтобы дополнить диаграмму исходных данных линией тренда, необходимо выполнить следующие действия:
- выделить на диаграмме ряд данных, для которого требуется построить линию тренда;
- щелкнуть правой кнопкой мыши и выбрать команду Добавить линию тренда;
- в открывшемся окне задать метод интерполяции (линейный, полиномиальный, логарифмический и т. д.), а также через команду Параметры – другие параметры (например, вывод уравнения кривой тренда, коэффициента детерминированности r2, направление и количество периодов для экстраполяции (прогноза) и др.);
- нажать кнопку Закрыть.
Чтобы отобразить на графике (гистограмме и др.) новые, прогнозируемые в результате регрессионного анализа данные, нужно:
- определить их с помощью функции ТЕНДЕНЦИЯ, РОСТ или другим способом,
- выделить на диаграмме нужную кривую, щелкнув по ней правой кнопкой мыши,
- в появившемся окне выбрать команду Выбрать данные…, в появившемся окне выбрать диапазон ячеек с новыми данными вручную или протащив по ним курсор при нажатой левой клавише мыши, нажать ОК.
На диаграмме появится продолжение кривой, построенной по новым данным.
Простая линейная регрессия
Пример 1. Функция ТЕНДЕНЦИЯ(TREND)
а) Предположим, что фирма может приобрести земельный участок в июле. Фирма собирает информацию о ценах за последние 12 месяцев, начиная с марта, на типичный земельный участок. Название первого столбца "Месяц" с данными о номерах месяцев записано в ячейке А1, а второго столбца "Цена" – в ячейке В1. Номера месяцев с 1 по 12 (известные значения х) записаны в ячейки А2…А13. Известные значения у содержат множество известных значений (133 890 руб., 135 000 руб., 135 790 руб., 137 300 руб., 138 130 руб., 139 100 руб., 139 900 руб., 141 120 руб., 141 890 руб., 143 230 руб., 144 000 руб., 145 290 руб.), которые находятся в ячейках В2;В13 соответственно (данные условия). Новые значения х, т.е. числа 13, 14,15,16,17 введём в ячейки А14…А18. Для того чтобы определить ожидаемые значения цен на март, апрель, май, июнь, июль, выделим любой интервал ячеек, например, B14:B18 (по одной ячейке для каждого месяца) и в строке формул введем функцию:
=ТЕНДЕНЦИЯ(В2:В13;А2:А13;А14:А18;1). (10)
После нажатия клавиш Ctrl+ Shift+Enter данная функция будет выделена как формула вертикального массива, а в ячейках B14:B18 появится результат: {146172;174190;148208;149226;150244}.
Таким образом, в июле фирма может ожидать цену около 150 244 руб.
б) Тот же результат будет получен, если вводить в формулу не все массивы переменных х и у, а использовать часть массивов, которые предусматриваются автоматически по умолчанию. Тогда формула (10) примет вид:
=ТЕНДЕНЦИЯ(В2:В13;;{13:14:15:16:17}). (11)
В формуле (11) используется массив по умолчанию (1:2:3:4:5:6:7:8:9:10:11:12) для аргумента "известные_значения_х", соответствующий 12 месяцам, для которых имеются данные по продажам. Он должен был бы быть помещен в формуле (11) между двумя знаками ;;. Массив (13:14:15:16:17) соответствует следующим 5 месяцам, для которых и получен массив результатов (146172:147190:148208:149226:150244).
Элементы массивов разделяет знак ":", который указывает на то, что они расположены по столбцам.
в) Аргумент "новые значения х" можно задать другим массивом ячеек, например, В14:В18, в которые предварительно записаны те же номера месяцев 13,14,15,16,17. Тогда вводимая в строку формул функция примет вид =ТЕНДЕНЦИЯ(В2:В13;;В14:В18).
Пример 2. Функция ЛИНЕЙН
а) Дана таблица изменения температуры в течение шести часов, введённая в ячейки D2:E7 (табл. 13.2 таблица 13.2).
Требуется определить температуру во время восьмого часа.
| … | D | E | |
|---|---|---|---|
| 1 | х-№часа | у-tо, град. | |
| 2 | 1 | 2 | |
| 3 | 2 | 3 | |
| 4 | 3 | 4 | |
| 5 | 4 | 7 | |
| 6 | 5 | 12 | |
| 7 | 6 | 18 |
Выделим ячейки D8:E12 для вывода результата, введем в строку ввода формулу =ЛИНЕЙН(Е2:Е7;D2:D7;1;1), нажмем клавиши Сtrl+Shift+Enter, в выделенных ячейках появится результат:
Таким образом, коэффициент m=3,143 со стандартной ошибкой 0,541, а свободный член b=-3,333 со стандартной ошибкой 2,106, т.е. функция, описывающая данные табл. 13.2 таблица 13.2, имеет вид
у=3,143х-3,333. (12)
Стандартные ошибки показывают максимально возможное отклонение параметра от рассчитанной величины. Для у оно составляет 2,263, т.е. реальное значение у может лежать в пределах 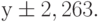 .
.
Точность приближения к табличным данным (коэффициент детерминированности r2) составляет 0,894 или 89,4%, что является высоким показателем. При х=8 получим: у=3,143*8-3,333=21,81 град.
б) Тот же результат можно получить, использовав функцию =ТЕНДЕНЦИЯ(Е2:Е7;;G2:G5) для, например, следующих четырёх часов, предварительно введя в ячейки G2:G5 числа с 7 до 10. Выделив ячейки Н2:Н5, введя в строку формул эту функцию и нажав Сtrl+Shift+Enter, получим в выделенных ячейках массив {18,667;21,80952;24,95238;28,09524}, т.е. для восьмого часа значение  град.
град.
в) Функция ПРЕДСКАЗ (FORECAST) – позволяет предсказать значение у для нового значения х по известным значениям х и у, используя линейное приближение зависимости у=f(x).
Синтаксис функции:
=ПРЕДСКАЗ(нов._знач._х;изв._знач._у;изв._знач._х).
Для данных примера 2 ввод формулы =ПРЕДСКАЗ(8;Е2:Е7;D2:D7) выводит в заранее выделенной ячейке результат 21,809. Новое значение х может быть задано не числом, а ячейкой, в которую записано это число.
Отличие функции ПРЕДСКАЗ от функции ТЕНДЕНЦИЯ заключается в том, что ПРЕДСКАЗ прогнозирует значения функции линейного приближения только для одного нового значения х.
Экспоненциальная регрессия
Пример 3
а) Функция ЛГРФПРИБЛ.
Рассмотрим условие примера 2.
Поскольку функция в табл. 13.2 таблица 13.2 носит явно нелинейный характер, целесообразно искать ее приближение в виде не прямой линии, как в примере 2, а в виде нелинейной кривой. Из всех видов нелинейности (гипербола, парабола, и др.) Excel реализует только экспоненциальное приближение вида у=b*mx c помощью функции ЛГРФПРИБЛ, которая рассчитывает для этого уравнения значения b и m.
Выделим для результата блок ячеек F8:G12, введём в строку формул Функцию =ЛГРФПРИБЛ(Е2:Е7;D2:D7;1;1), нажмем клавиши Сtrl+Shift+Enter, в выделенных ячейках появится результат:
Таким образом, коэффициент m=1,566, а b=1,197, т.е. уравнение приближающей кривой имеет вид:
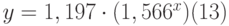
со стандартными ошибками для m, b, и у равными 0,02, 0,079 и 0,085 соответственно. Коэффициент детерминированности r2 =0,992, т.е. полученное уравнение даёт совпадение с табличными данными с вероятностью 99,2%.
Поскольку интерполяция табл. 13.2 таблица 13.2 экспоненциальной кривой даёт более точное приближение (99,2%) и с меньшими стандартными ошибками для m, b и у, в качестве приближающего уравнения принимаем уравнение (13).
При х=8 получим у=1,197*34,363=41,131 град.
б) Функция РОСТ вычисляет прогнозируемое по экспоненциальному приближению значение у для новых значений х, имеет формат:
=РОСТ(изв_значу;изв_знач_х;нов_знач_х;константа).
Выделим блок ячеек F14: F17, введём формулу =РОСТ(Е2:Е7;D2:D7;G2:G5;ИСТИНА), в выделенных ячейках появится массив чисел {27,6696434;43,3384133;67,8800967;106,319248}, т.е. при х=8 значение функции у=43,34 град. Это значение немного отличается от вычисленного в п. а), поскольку функция РОСТ использует для расчетов линию экспонециального тренда.
Примечание. При выборе экспоненциальной приближающей кривой следует учитывать, что интерполировать ею можно только участки, где функция монотонно возрастает или убывает (при отрицательном аргументе х), т.е. функцию, имеющую точки перегиба (например, параболу, синусоиду, кривую рис. 2 – т. А и др.) следует разбить на участки монотонного изменения от одной точки перегиба до другой и каждый участок интерполировать отдельно. Для рисунка 2 функцию нужно разбить на 2 участка – от начала до т. А и от т. А до конца кривой.
Множественная линейная регрессия
Пример 4
Предположим, что коммерческий агент рассматривает возможность закупки небольших зданий под офисы в традиционном деловом районе. Агент может использовать множественный регрессионный анализ для оценки цены здания под офис на основе следующих переменных:
у – оценочная цена здания под офис;
х1 – общая площадь в квадратных метрах;
х2 – количество офисов;
х3 – количество входов;
х4 – время эксплуатации здания в годах.
Агент наугад выбирает 11 зданий из имеющихся 1500 и получает следующие данные:
| А | В | С | D | Е | |
|---|---|---|---|---|---|
| 1 | х1- площадь, м2 | х2 – офисы | х3 – входы | х4 – срок, лет | у – цена, у.е. |
| 2 | 2310 | 2 | 2 | 20 | 42000 |
| 3 | 2333 | 2 | 2 | 12 | 144000 |
| 4 | 2356 | 3 | 1,5 | 33 | 151000 |
| 5 | 2379 | 3 | 2 | 43 | 151000 |
| 6 | 2402 | 2 | 3 | 53 | 139000 |
| 7 | 2425 | 4 | 3 | 23 | 169000 |
| 8 | 2448 | 2 | 1,5 | 99 | 126000 |
| 9 | 2471 | 2 | 2 | 34 | 142000 |
| 10 | 2494 | 3 | 3 | 23 | 163000 |
| 11 | 2517 | 4 | 4 | 55 | 169000 |
| 12 | 2540 | 2 | 3 | 22 | 149000 |
"Пол-входа" означает вход только для доставки корреспонденции.
В этом примере предполагается, что существует линейная зависимость между каждой независимой переменной (х1,х2,х3,х4) и зависимой переменной (у), т.е. ценой зданий под офис в данном районе.
- выделим блок ячеек А14:Е18 (в соответствии с табл. 13.1 таблица 13.1),
- введём формулу =ЛИНЕЙН(Е2:Е12;А2:D12;ИСТИНА;ИСТИНА), -
- нажмём клавиши Ctrl+Shift+Enter,
- в выделенных ячейках появится результат:
| А | В | С | D | E | |
|---|---|---|---|---|---|
| 14 | -234,237 | 2553,210 | 12529,7682 | 27,6413 | 52317,83 |
| 15 | 13,2680 | 530,6691 | 400,066838 | 5,42937 | 12237,36 |
| 16 | 0,99674 | 970,5784 | #Н/Д | #Н/Д | #Н/Д |
| 17 | 459,753 | 6 | #Н/Д | #Н/Д | #Н/Д |
| 18 | 1732393319 | 5652135 | #Н/Д | #Н/Д | #Н/Д |
Уравнение множественной регрессии  теперь может быть получено из строки 14:
теперь может быть получено из строки 14:
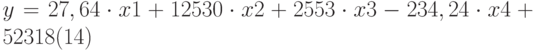
Теперь агент может определить оценочную стоимость здания под офис в том же районе, которое имеет площадь 2500 м2, три офиса, два входа, зданию 25 лет, используя следующее уравнение:
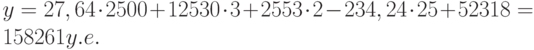
Это значение может быть вычислено с помощью функции ТЕНДЕНЦИЯ:
=ТЕНДЕНЦИЯ(Е2:Е7;A2:D12;{2500;3;2;25}).
При интерполяции с помощью функции
=ЛГРФПРИБЛ(Е2:Е7;A2:D12;ИСТИНА;ИСТИНА)
для получения уравнения множественной экспоненциальной регрессии выводится результат:
| 0,99835752 | 1,0173792 | 1,0830186 | 1,0001704 | 81510,335 |
| 0,00014837 | 0,0065041 | 0,0048724 | 6,033Е-05 | 0,1365601 |
| 0,99158875 | 0,0105158 | #Н/Д | #Н/Д | #Н/Д |
| 176,832548 | 6 | #Н/Д | #Н/Д | #Н/Д |
| 0,07821851 | 0,0006635 | #Н/Д | #Н/Д | #Н/Д |
| #Н/Д | #Н/Д | #Н/Д | #Н/Д | #Н/Д |
Коэффициент детерминированности здесь составляет 0,992 (99,2%), т.е. меньше, чем при линейной интерполяции, поэтому в качестве основного следует оставить уравнение множественной регрессии (14).
Таким образом, функции ЛИНЕЙН, ЛГРФПРИБЛ, НАКЛОН определяют коэффициенты, свободные члены и статистические параметры для уравнений одномерной и множественной регрессии, а функции ТЕНДЕНЦИЯ, ПРЕДСКАЗ, РОСТ позволяют получить прогноз новых значений без составления уравнения регрессии по значениям тренда.
ЗАДАНИЕ
Вариант задания к данной лабораторной работе включает две задачи. Для каждой из них необходимо составить и определить:
- Таблицу исходных данных, а также значений, полученных методами линейной и экспоненциальной регрессии.
- Коэффициенты в уравнениях прямой и экспоненциальной кривой (функции ЛИНЕЙН и ЛГРФПРИБЛ), напишите уравнения прямой и экспоненциальной кривой для простой и множественной регрессии.
- Погрешности (ошибки) прямой и экспоненциальной кривой, вычислений для коэффициентов и функций, коэффициенты детерминированности. Оценить, какой тип регрессии наилучшим образом подходит для вашего варианта задания.
- Прогноз изменения данных, выполненный с использованием линейной и экспоненциальной регрессии (функции ТЕНДЕНЦИЯ, ПРЕДСКАЗ, РОСТ).
- Построить гистограмму (или график) исходных данных для задачи 1 (одномерная регрессия), отобразить на ней линию тренда, а также соответствующее ей уравнение и коэффициент детерминированности.
Варианты заданий (номер варианта соответствует номеру компьютера).
Вариант 1.
- На рынке наблюдается стойкое снижение цен на компьютеры. Сделать прогноз, на сколько необходимо будет снизить цену на компьютеры в следующем месяце в вашей фирме, чтобы как минимум сравнять её с ценой на аналогичные компьютеры в конкурирующей фирме, если известна динамика изменения цен на них в конкурирующей фирме за последние 12 месяцев.
Для выполнения задания нужно ввести ряд из 12 ячеек с ценами конкурирующей фирмы, сделать прогноз цены на следующий месяц и др. (см. Задание).
- Известна структура расходов фирмы на рекламу в газетах, на радио, в журналах, на телевидении, на наружную рекламу (в процентах от общей суммы), а также оборот фирмы в каждом за последние 6 месяцев. Какой оборот можно ожидать в следующем месяце, если предполагается следующая структура расходов на рекламу: газеты-40%, журналы-40%, радио-5%, телевидение-14%, наружная реклама-1%.
Для выполнения задания нужно составить таблицу со столбцами вида:
| Месяц | х1-газеты,% | х2-журн.,% | х3-рад.,% | х4-телев.,% | х5-нар. рекл.,% | Оборот, $ |
|---|---|---|---|---|---|---|
| 1 | 37 | 34 | 12 | 10 | 5 | 410000 |
| 2 | 38 | 37 | 10 | 11 | 6 | 411500 |
| 3 | 39 | 38 | 9 | 13 | 7 | 413700 |
| 4 | 40 | 39 | 8 | 15 | 8 | 417050 |
| 5 | 41 | 40 | 7 | 16 | 9 | 420000 |
| 6 | 42 | 42 | 5 | 17 | 10 | 425000 |
и сделать множественный регрессионный прогноз (см. Задание).
Вариант 2.
- Имеются данные об объеме продаж в расчете на душу населения по хлебу и молоку и данные по годовым доходам на душу за 10 лет. По каждому товару построить модели регрессии для объемов продаж и функции размера доходов. Сделать прогноз о продажах и доходах на следующий год.
Для выполнения задания нужно составить таблицу вида:
| Годы | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| х1-хлеб, кг | 23,5 | 26,7 | 27,9 | 30,1 | 31,5 | 35,7 | 38,3 | 40,1 | 41,5 | 42,8 | |
| х2-молоко, л | 20,45 | 22 | 23,8 | 25,9 | 27,4 | 29 | 33,5 | 36,8 | 38,1 | 39,5 | |
| У-доход, р. | 6600 | 7200 | 8400 | 10500 | 12750 | 14730 | 16240 | 17000 | 18050 | 18250 |
и получить два уравнения – у=f(x1) и у=f(x2), сделать прогноз на следующий год для рядов х1, х2, у и др. (см. Задание).
- Руководство фирмы провело оценку качеств пяти рекламных агентов по следующим признакам: х1 – эрудиция, х2 – знание предметной области. Полученные средние оценки, нормированные от 0 до 1, были сопоставлены с оценками эффективности деятельности агентов (% успешных сделок от количества возможных). Определить эффективность для агента с усреднёнными качествами. Сравнить её со средней эффективностью упомянутых 5 агентов.
Исходные данные нужно ввести в таблицу вида:
| А | В | С | D | E | F | G | |
|---|---|---|---|---|---|---|---|
| 1 | х1-эрудиция | х2-энергичность | х3-люди | х4-внешность | х5-знания | Эффективность | |
| 2 | Агент 1 | 0,8 | 0,2 | 0,4 | 0,6 | 1,0 | 76% |
| 3 | Агент 2 | 0,74 | 0,3 | 0,39 | 0,58 | 0,95 | 78% |
| 4 | Агент 3 | 0,67 | 0,41 | 0,35 | 0,5 | 0,83 | 79% |
| 5 | Агент 6 | 0,59 | 0,59 | 0,33 | 0,47 | 0,8 | 80% |
| 6 | Агент 5 | 0,5 | 0,7 | 0,3 | 0,4 | 0,74 | 81% |
| 7 | Средняя эффективность пяти агентов | ||||||
| 8 | Средний агент | 0,5 | 0,5 | 0,5 | 0,5 | 0,5 | |
Массив ячеек В2-F6 заполняется произвольными числами от 0 до 1, столбец G2-G6 – процентами удачных сделок по принципу "Чем выше уровень качеств агента, тем выше эффективность его работы", в ячейке G7 должна быть формула для вычисления среднего значения ячеек G2:G6, в ячейке G8 нужно вычислить значение эффективности для среднего агента по формуле, полученной в результате множественного регрессионного анализа работы пяти агентов. Остальные пункты – см. Задание.
Вариант 3.
- Автосалон имеет данные о количестве проданных автомобилей "Мерседес" и "БМВ" за последние 4 квартала. Учитывая тенденцию изменения объёма продаж, определить, каких автомобилей нужно закупить больше ("Мерседес" или "БМВ") в следующем квартале?
Для выполнения задания нужно составить и заполнить таблицу вида:
сделать прогноз продаж на новый квартал и выполнить другие пункты задания.
- Известны следующие данные о 5 недавно проданных подержанных автомобилях: у – стоимость продажи, х1 – стоимость аналогичного нового автомобиля, х2 – год выпуска, х3 – пробег, х4 – количество капитальных ремонтов, х5 – экспертные заключения о состоянии кузова и техническом состоянии автомобилей (по 10-бальной шкале). Определить, сколько может стоить автомобиль с соответствующими характеристиками: 340 000, 1998г., 140000км., 1, 6 (см. пример 4).
Вариант 4.
- Определить минимально необходимый тираж журнала и возможный доход от размещения в нём рекламы в следующем месяце, если известны данные об объёмах продаж этого журнала и доходах от размещения рекламы за последние 12 месяцев (считать, что расценки на рекламу не менялись).
Для выполнения задания нужно составить таблицу вида:
| Месяц | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Тираж,тыс. | 100 | 120 | 121,7 | 124,2 | 128 | 130,1 | 133,45 | 136 | 141 | 142,1 | 143,8 | 145 |
| Доход,тыс. руб. | 128 | 135 | 138 | 142 | 147 | 154 | 159 | 161 | 163 | 168 | 170,5 | 172 |
и заполнить ячейки за 12 месяцев условными данными. По этим данным нужно сделать линейный и экспоненциальный прогноз и др. (см. Задание).
- В целях привлечения покупателей и увеличения оборота фирма проводит стратегию ежемесячного снижения цен на свой товар. На основании данных о динамике изменения цен, объемов продаж в данной фирме и ещё в 3 конкурирующих фирмах за последние 12 месяцев сделать прогноз о том, возрастает ли объём продаж у данной фирмы при очередном снижении цен в следующем месяце, если предположить, что цены и объёмы у конкурентов в следующем месяце будут средние за рассматриваемый период.
Для выполнения задания нужно составить таблицу вида:
| Мес. | Фирма | Конкурент 1 | Конкурент 2 | Конкурент 3 | ||||
|---|---|---|---|---|---|---|---|---|
| 1 | У-объём | х1-цена | х2-объём | х3-цена | х4-объём | х5-цена | х6-объём | х7-цена |
| 2 | 10000 | 1875 | 12000 | 1720 | 12500 | 1740 | 11970 | 1700 |
| 3 | 11000 | 1850 | 12340 | 1705 | 12620 | 1735 | 12100 | 1690 |
| 4 | 11570 | 1810 | 12750 | 1675 | 12740 | 1710 | 12350 | 1645 |
| 5 | 11850 | 1750 | 12910 | 1630 | 12960 | 1695 | 12500 | 1615 |
| 6 | 12100 | 1685 | 13100 | 1615 | 13000 | 1674 | 12630 | 1580 |
| 7 | 12340 | 1630 | 13570 | 1600 | 13210 | 1625 | 12920 | 1545 |
| 8 | 12750 | 1615 | 13820 | 1575 | 13320 | 1610 | 13150 | 1520 |
| 9 | 12910 | 1600 | 13980 | 1515 | 13460 | 1560 | 13300 | 1500 |
| 10 | 13100 | 1575 | 14000 | 1500 | 13600 | 1525 | 13610 | 1490 |
| 11 | 13230 | 1530 | 14070 | 1495 | 13780 | 1500 | 13850 | 1485 |
| 12 | 13470 | 1510 | 14120 | 1488 | 13900 | 1460 | 14000 | 1475 |
| 13 | ||||||||
Вариант 5.
- На основании данных о курсе американского доллара и немецкой марки в первом полугодии сделать прогноз о соотношении данных валют на второе полугодие. Во что будет выгоднее вкладывать деньги в конце года?
Для выполнения задания нужно составить таблицу вида:
| Месяц | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Доллар | 24,5 | 24,9 | 25,7 | 26,9 | 28,0 | 28,8 | 29,3 | 29,7 | 30,5 | 30,9 | 31,8 | |
| Марка | 72,1 | 76,3 | 79,6 | 85,3 | 89,7 | 90,9 | 93,2 | 96,4 | 100,2 | 101,6 | 104,9 |
и сделать линейный прогноз на следующие 6 месяцев и др. (см. Задание).
- Известны данные за последние 6 месяцев о том, сколько раз выходила реклама фирмы, занимающейся недвижимостью, на телевидении – х1, радио – х2, в газетах и журналах – х3, а также количество звонков –у1 и количество совершённых сделок – у2. Какое соотношение количества совершённых сделок к количеству звонков у (в %) можно ожидать в следующем месяце, если известно, сколько раз выйдет реклама в каждом из перечисленных средств массовой информации.
Для выполнения задания нужно составить и заполнить таблицу вида:
| A | B | C | D | E | |
|---|---|---|---|---|---|
| 1 | месяц | х1 | х2 | х3 | y=у2/у1*100% |
| 2 | 1 | 15 | 10 | 24 | 78% |
| 3 | 2 | 16 | 11 | 23 | 80% |
| 4 | 3 | 18 | 12 | 22 | 81% |
| 5 | 4 | 19 | 12 | 22 | 84% |
| 6 | 5 | 21 | 13 | 21 | 85% |
| 7 | 6 | 22 | 14 | 20 | 89% |
| 8 | 7 |
и выполнить применительно к таблице пункты Задания.
Вариант 6.
- Для некоторого региона известен среднегодовой доход населения, а также данные о структуре расходов (тыс. руб. в год) за последние 5 лет по следующим статьям: питание – х1, жильё – х2, одежда – х3, здоровье – х4, транспорт – х5, отдых – х6, образование – х7. На основании известных данных провести анализ потребительского кредита (или накопления) в следующем 6 году.
Для выполнения задания нужно составить и заполнить таблицу вида
| Годы | х1 | х2 | х3 | х4 | х5 | х6 | х7 | Расход 
|
Доход | Кредит(Y) |
|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 5 | 2 | 1,3 | 1 | 0,3 | 5 | 4 | 18,6 | 21,4 | 3,1 |
| 2 | 5,2 | 2,2 | 1,2 | 1,2 | 0,4 | 4,8 | 4,5 | 19,5 | 22 | 2,5 |
| 3 | 5,5 | 2,5 | 1,1 | 1,4 | 0,6 | 4,6 | 4,9 | 20,6 | 23,4 | 2,8 |
| 4 | 5,8 | 2,7 | 0,9 | 1,6 | 1 | 4,2 | 5,6 | 21,8 | 25,8 | 4 |
| 5 | 7 | 3 | 0,8 | 2 | 1,2 | 4 | 6,5 | 24,7 | 26,2 | 1,5 |
| 6 | 7,5 | 3,3 | 0,7 | 2,2 | 1,5 | 3,8 | 7 | 26,5 | 27,5 |
В ячейках столбца 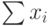 ) должны быть записаны формулы, вычисляющие суммы всех расходов х1+х2+…+х7 в каждом году, в ячейках столбца Доход – соответствующие среднегодовые доходы, в ячейках столбца Кредит – формулы разности содержимого ячеек с ежегодными доходами и затратами, т.е. Кредит = Доход- . Затем для столбца Кредит нужно выполнить регрессионный прогноз на следующий год и другие пункты Задания.
) должны быть записаны формулы, вычисляющие суммы всех расходов х1+х2+…+х7 в каждом году, в ячейках столбца Доход – соответствующие среднегодовые доходы, в ячейках столбца Кредит – формулы разности содержимого ячеек с ежегодными доходами и затратами, т.е. Кредит = Доход- . Затем для столбца Кредит нужно выполнить регрессионный прогноз на следующий год и другие пункты Задания.
- Для 10 однокомнатных квартир, расположенных в одном районе, известны следующие данные: общая площадь – х1, жилая площадь – х2, площадь кухни – х3, наличие балкона – х4, телефона – х5, этаж – х6, а также стоимость – y. Определить, сколько может стоить однокомнатная квартира в этом районе без балкона, без телефона, расположенная на 1-ом этаже, общей площадью 28 м2, жилой – 16 м2, с кухней 6 м2.
| Квартиры | X1 | X2 | X3 | X4 | X5 | Стоимость (y) |
|---|---|---|---|---|---|---|
| 1 | 41 | 33 | 7 | 1 | 2 | 42000 |
| 2 | 40 | 30 | 7,7 | 2 | 3 | 40000 |
| 3 | 45 | 37 | 8 | 0 | 5 | 47000 |
| 4 | 46,3 | 34 | 9 | 1 | 6 | 49500 |
| 5 | 50 | 36 | 9 | 1 | 4 | 51000 |
| 6 | 53 | 40 | 9,5 | 1 | 7 | 55000 |
| 7 | 56 | 41 | 10 | 0 | 9 | 62000 |
| 8 | 60 | 47 | 12 | 2 | 10 | 62300 |
| 9 | 65 | 49 | 14 | 2 | 12 | 69000 |
| 10 | 70 | 58 | 14,5 | 2 | 14 | 72000 |
| 11 | 28 | 16 | 6 | 0 | 1 |
Вариант 7.
- Определить возможный прирост населения (кол-во человек на 1000 населения) в 2011 году, если известны данные о кол-ве родившихся и умерших на 1000 населения в 1997-2006 годах.
| Годы | 1997 | 1998 | 1999 | 2000 | 2001 | 2002 | 2003 | 2004 | 2005 | 2006 | 2011 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Родились | 100 | 110 | 130 | 155 | 170 | 174 | 180 | 185 | 190 | 200 | |
| Умерли | 108 | 115 | 135 | 160 | 178 | 180 | 186 | 190 | 197 | 205 |
- После некоторого спада наметился рост объёмов продаж матричных принтеров. Используя данные об объёмах продаж, ценах на матричные, струйные и лазерные принтеры, а также на их расходные материалы за последние 6 месяцев, определить возможный спрос на матричные принтеры в следующем месяце.
Проанализируйте, связано ли увеличение спроса на матричные принтеры с уменьшением спроса на струйные и лазерные.
| Матричные принтеры | Струйные принтеры | Лазерные принтеры | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Спрос у1 | Цена х1 | Рас.мат. z1 | Спрос у2 | Цена х2 | Рас.мат. z/2 | Спрос у3 | Цена х3 | Рас.мат. z3 | |
| 1 | 56 | 4172 | 174 | 26 | 2384 | 558 | 13 | 12517 | 1558 |
| 2 | 58 | 4250 | 179 | 24 | 2398 | 570 | 11 | 12984 | 1612 |
| 3 | 60 | 4289 | 182 | 23 | 2401 | 598 | 9 | 13259 | 1789 |
| 4 | 65 | 4297 | 194 | 20 | 2456 | 649 | 8 | 13687 | 1865 |
| 5 | 69 | 4305 | 205 | 19 | 2512 | 722 | 7 | 14013 | 1998 |
| 6 | 75 | 4318 | 213 | 18 | 2543 | 768 | 6 | 14587 | 2200 |
| 7 | 4456 | 220 | 17 | 2601 | 779 | 5 | 14789 | 2245 | |
Необходимо сделать прогноз на седьмой месяц по уравнению у1=f(x1,z1), получить уравнение y=(у2,x2, z2, у3, x3, z2) и проанализировать его. Если слагаемые у2 и у3 входят в регрессионное уравнение со знаком "-", то уменьшение спросов у2 и у3 ведёт к увеличению спроса у1.
Вариант 8.
- Построить прогноз развития спроса населения на телевизоры, если известна динамика продаж телевизоров (тыс. шт.) и динамика численности населения (тыс. чел.) за 10 лет. По данным таблицы сделать прогноз по обоим рядам на следующий год. Выполнить другие пункты задания.
| Годы | 2001 | 2002 | 2003 | 2004 | 2005 | 2006 | 2007 | 2008 | 2009 | 2010 | 2011 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Динамика населения (тыс. чел) | 21,5 | 26,1 | 31,5 | 34,9 | 45,1 | 50,8 | 56 | 59,4 | 63,9 | 67,1 | |
| Динамика продаж (тыс. шт.) | 2,5 | 2,9 | 3,4 | 3,9 | 4,1 | 4,8 | 5 | 5,6 | 5,9 | 6,2 |
- Размещая рекламу в 4-х изданиях, фирма собрала сведения о поступивших на нее откликов – у и сопоставила их с данными об изданиях: х1 – стоимость издания, х2 – стоимость одного блока рекламы, х3 – тираж, х4 – объём аудитории, х5 – периодичность, х6 – наличие телепрограммы. Какое количество откликов можно ожидать на рекламу в издании со следующими характеристиками: 15000 руб., 10$, 1000 экз., 25000 чел., 4 раза в месяц, без телепрограммы.
Пользуясь данными таблицы
| Издания | х1 | х2 | х3 | х4 | х5 | х6 | Отклики, у |
|---|---|---|---|---|---|---|---|
| 1 | 10000 | 13 | 700 | 15000 | 4 | 1 | 108 |
| 2 | 12500 | 12 | 850 | 22000 | 8 | 1 | 115 |
| 3 | 15890 | 11,8 | 960 | 28000 | 10 | 0 | 120 |
| 4 | 17850 | 11 | 1200 | 32000 | 26 | 1 | 128 |
| 5 | 15000 | 10 | 1000 | 25000 | 4 | 0 |
необходимо сделать прогноз при заданных характеристиках.
Вариант 9.
- Размещая свою рекламу в 2-х печатных изданиях одновременно, фирма собрала сведения о количестве поступивших звонков и количестве заключенных сделок по объявлениям в каждом из указанных изданий за последние 12 месяцев. Определить, в каком из изданий и насколько эффективность размещения рекламы в следующем месяце будет больше?
| Месяцы | Издание 1 | Издание 2 | ||
|---|---|---|---|---|
| Звонки | Сделки | Звонки | Сделки | |
| 1 | 98 | 66 | 112 | 79 |
| 2 | 105 | 72 | 143 | 85 |
| 3 | 105 | 75 | 150 | 90 |
| 4 | 110 | 80 | 130 | 100 |
| 5 | 125 | 90 | 120 | 75 |
| 6 | 140 | 100 | 115 | 80 |
| 7 | 136 | 95 | 128 | 82 |
| 8 | 137 | 87 | 132 | 78 |
| 9 | 145 | 102 | 138 | 88 |
| 10 | 123 | 75 | 143 | 92 |
| 11 | 130 | 79 | 150 | 97 |
| 12 | 139 | 88 | 155 | 97 |
| 13 | ||||
Эффективность определяется как сделки/звонки. Сделать линейный и экспоненциальный прогнозы по обоим изданиям.
- Пусть комплект мягкой мебели (диван + 2 кресла) характеризуется стоимостью комплектующих: х1- деревянные подлокотники, х2 – велюровое покрытие, х3 – кресло-кровать, х4 – угловой диван, х5 – раскладывающийся диван, х6 – место для хранения белья. По данным о стоимости 5 комплектов сделать вывод о возможной стоимости комплекта с обычным раскладывающимся диваном, с местом для белья, без деревянных подлокотников и велюрового покрытия, с креслом кроватью.
Пользуясь данными таблицы
| Признаки | х1 | х2 | х3 | х4 | х5 | х6 | У -стоимость |
|---|---|---|---|---|---|---|---|
| Комплект 1 | 250 | 540 | 2500 | 4300 | 6400 | 800 | 13850 руб. |
| Комплект 2 | 320 | 650 | 3000 | 4800 | 7000 | 980 | 15770 руб. |
| Комплект 3 | 400 | 730 | 3900 | 6000 | 8500 | 1100 | 16730 руб. |
| Комплект 4 | 452 | 1300 | 4300 | 7500 | 9200 | 2050 | 24350 руб. |
| Комплект 5 | 550 | 1750 | 6400 | 12450 | 16700 | 4300 | 42150 руб. |
| Комплект 6 | 670 | 800 | 2750 | 6700 | 8800 | 1000 |
сделать прогноз и выполнить другие пункты задания.
Вариант 10.
- Для 2-х радиостанций известны данные об изменении объёма аудитории и динамике роста цен за 1 минуту эфирного времени за последние 12 месяцев. Определить, для какой радиостанции стоимость одного контакта со слушателем будет меньше?
| Месяц | Радиостанция 1 | Радиостанция 2 | ||
|---|---|---|---|---|
| Аудитория | Цена 1 мин. | Аудитория | Цена 1 мин. | |
| 1 | 250000 | 8000 | 300000 | 7560 |
| 2 | 540000 | 6500 | 450000 | 6340 |
| 3 | 580000 | 6460 | 490000 | 6250 |
| 4 | 650000 | 6300 | 550000 | 6000 |
| 5 | 730000 | 6060 | 610000 | 5730 |
| 6 | 750000 | 6000 | 690000 | 5300 |
| 7 | 800000 | 5400 | 750000 | 5100 |
| 8 | 840000 | 5320 | 780000 | 5000 |
| 9 | 890000 | 5130 | 870000 | 4700 |
| 10 | 950000 | 5000 | 900000 | 4650 |
| 11 | 1000000 | 4800 | 940000 | 4600 |
| 12 | 1108000 | 4700 | 1025000 | 4540 |
| 13 | ||||
| Контакт | ||||
В строке "Контакт" в ячейках С8 и D8 должны быть записаны формулы = С7/В7 и =Е7/D7 соответственно, вычисляющие стоимость 1 мин. Эфира для одного слушателя в прогнозируемом месяце. Прогноз нужно выполнить для линейного и экспоненциального приближений и выбрать более достоверный, а также сделать другие пункты Задания.
- На основании данных ежемесячных исследований известна динамика рейтинга банка (в условных единицах) за последние 6 месяцев в следующих сферах:
- менеджмент и технология – х1;
- менеджеры и персонал – х2;
- культура банковского обслуживания – х3;
- имидж банка на рынке финансовых услуг – х4;
- реклама банка – х5.
Определить возможное изменение количества вкладчиков данного банка в следующем месяце, если известны значения сфер рейтинга и количество вкладчиков в каждом из рассматриваемых 6 месяцев.
| Месяц | х1 | х2 | х3 | х4 | х5 | Количество вкладчиков (у) |
|---|---|---|---|---|---|---|
| 1 | 2 | 5 | 5 | 5 | 4 | 110000 |
| 2 | 4 | 6 | 6,5 | 5,5 | 4,5 | 119000 |
| 3 | 5 | 7 | 7 | 6 | 5,5 | 125000 |
| 4 | 6 | 8 | 8 | 7,5 | 6 | 129000 |
| 5 | 7 | 9 | 8,5 | 8 | 7 | 140000 |
| 6 | 8 | 10 | 9 | 8,5 | 7,5 | 148000 |
| 7 | 9 | 11 | 10 | 9 | 8 |
Выполнить другие пункты Задания.
КОНТРОЛЬНЫЕ ВОПРОСЫ
- Сущность регрессионного анализа, его использование для прогнозирования функций.
- Как получить уравнения одномерной линейной регрессии, каков синтаксис функции линейного приближения?
- Как получить уравнение многомерной линейной регрессии, каков синтаксис функции?
- Как получить уравнение одномерной экспоненциальной регрессии, каков синтаксис функции экспоненциального приближения?
- Как получить уравнение многомерной экспоненциальной регрессии, каков синтаксис функции экспоненциального приближения?
- Каковы правила ввода и использования табличных формул?
- Как на гистограмме исходных данных добавить линию тренда?
- Как с помощью линии тренда отобразить прогнозируемые величины?
< Лекция 12 || Лекция 13 || Лекция 14 >
Арсен Никифоров