| Россия |
Инспектор
Вы можете этот курс.
Опубликован: 19.09.2008 | Уровень: специалист | Доступ: платный
Лекция 3:
Лексическая структура Haskell 98
Аннотация: В этой лекции мы опишем лексическую структуру нижнего уровня языка Haskell. Большинство деталей может быть пропущено при первом прочтении этого описания
Ключевые слова: PAT, синтаксис, BNF, нетерминал, кодировка символов, lexeme, whitespace, literal, newline, linefeed, 'dashed, лексема, лексический анализ, CASE, символ новой строки, infix, идентификатор, вывод, операторы, инфиксный, конструктор типа, определение, octal, hexadecimal, exponent, литерал, типизация, gap, SOH, STX, ETX, EOT, ACK, BEL, NAK, SYN, ETB, забой, возврат каретки, ASCII, пустой символ, фигурные скобки, правило размещения, отступ, список, модуль, WHERE
2.1. Соглашения об обозначениях
Эти соглашения об обозначениях используются для представления синтаксиса:
Поскольку синтаксис в этом разделе описывает лексический синтаксис, все пробельные символы выражены явно; нет никаких неявных пробелов между смежными символами. Повсюду используется BNF-подобный синтаксис, чьи правила вывода имеют вид:
| nonterm | 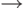 |
alt1 | alt2 | ... | altn |
| Перевод: нетерминал | |
альтернатива1 | альтернатива2 | ... | альтернативаn |
Необходимо внимательно отнестись к отличию синтаксиса металогических символов, например, | и [...], от конкретного синтаксиса терминалов (данных в машинописном шрифте),например, | и [...], хотя обычно это ясно из контекста.
Haskell использует кодировку символов Unicode [11].
Тем не менее, исходные программы в настоящее время написаны в основном в кодировке символов ASCII, используемой в более ранних версиях Haskell.
Этот синтаксис зависит от свойств символов Unicode, определяемых консорциумом Unicode. Ожидается, что компиляторы Haskell будут использовать новые версии Unicode, когда они станут доступными.
2.2 Лексическая структура программы
Перевод:
Лексический анализ должен использовать правило "максимального потребления": в каждой точке считывается наиболее длинная из возможных лексем, которая удовлетворяет правилу вывода lexeme (лексемы).
Таким образом, несмотря на то, что case является зарезервированным словом, cases таковым не является. Аналогично, несмотря на то, что = зарезервировано, == и 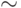 =- нет.
=- нет.
Любой вид whitespace (пробельной-строки) также является правильным разделителем для лексем.
Символы, которые не входят в категорию ANY (ЛЮБОЙ-символ), недопустимы в программах на Haskell и должны приводить к лексической ошибке.