| Россия |
Инспектор
Вы можете этот курс.
Опубликован: 23.07.2006 | Уровень: специалист | Доступ: платный
Лекция 6:
Синтаксические анализаторы. Нисходящие анализаторы
Леворекурсивные грамматики
LL(k)-свойство накладывает сильные ограничения на грамматику. Иногда имеется возможность преобразовать грамматику так, чтобы получившаяся грамматика обладала свойством LL(1). Такое преобразование далеко не всегда удается, но если нам удалось получить LL(1)-грамматику, то для построения анализатора можно использовать метод рекурсивного спуска без возвратов.
Предположим, что мы хотим построить анализатор языка, порождаемого следующей грамматикой (мы уже приводили неформальное рассмотрение этого примера в "лекции 4" ):
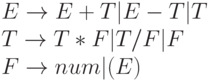
Заметим, что терминалы множества FIRST(T) принадлежат также множеству FIRST(E+T) . В силу этого мы не сможем однозначно определить последовательность вызовов процедур, которую мы должны выполнить при анализе входной цепочки. Проблема заключается в том, что нетерминал E встречается на первой позиции правой части правила, левая часть которого также E. В такой ситуации нетерминал E называется непосредственно леворекурсивным.
Определение.Нетерминал A КС-грамматики G называется леворекурсивным, если в грамматике существует вывод A =>* Aw.
Грамматика, имеющая хотя бы одно леворекурсивное правило, не может быть LL(1)-грамматикой. С другой стороны, известно, что каждый КС-язык определяется хотя бы одной нелеворекурсивной грамматикой.
Алгоритм устранения леворекурсивности
Опишем алгоритм устранения непосредственной леворекурсивности. Пусть G = (N, T, P, S) - КС-грамматика и правило  представляет собой все правила из P, содержащие A в левой части, причем ни одна из цепочек vi не начинается с нетерминала A . Добавим к множеству N еще один нетерминал A' и заменим правила, содержащие A в левой части, на следующие:
представляет собой все правила из P, содержащие A в левой части, причем ни одна из цепочек vi не начинается с нетерминала A . Добавим к множеству N еще один нетерминал A' и заменим правила, содержащие A в левой части, на следующие:
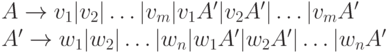
Можно доказать, что полученная грамматика эквивалентна исходной.
В результате применения этого преобразования к приведенной выше грамматике, описывающей арифметические выражения, мы получим следующую грамматику:
E -> T | TE' E' -> +T | +TE' T -> F | FT' T'-> *F | *FT' F -> (E) | num
Нетрудно показать, что получившаяся грамматика обладает свойством LL(1).
Еще одна подобная проблема связана с тем, что два правила для одного и того же нетерминала начинаются одними и теми же символами. Например,
S -> if E then S else S S -> if E then S
В этом случае мы добавим еще один нетерминал, который будет соответствовать различным окончаниям этих правил. Мы получим следующие правила:
S -> if E then S S' S' -> S'-> else S
Для полученной грамматики может быть реализован метод рекурсивного спуска.
Рекурсивный спуск с возвратами
Итак, для того, чтобы иметь возможность применить метод рекурсивного спуска, мы должны преобразовать грамматику к виду, в котором множества FIRST не пересекаются. Это сложный и неприятный процесс. Поэтому на практике зачастую используется следующий прием, называемый рекурсивным спуском с возвратами.
Для этого лексический анализатор представляется в виде объекта, у которого помимо традиционных методов scan, next и т.п., есть также копирующий конструктор. Затем во всех ситуациях, где может возникнуть неоднозначность, мы перед началом разбора запоминаем текущее состояние лексического анализатора (т.е. заводим копию лексического анализатора) и пытаемся продолжить разбор текста, считая, что мы имеем дело с первой из возможных в данной ситуации конструкций. Если этот вариант разбора заканчивается неудачей, то мы восстанавливаем состояние лексического анализатора и пытаемся заново разобрать тот же самый фрагмент с помощью следующего варианта грамматики и т.д. Если все варианты разбора заканчиваются неудачно, то мы сообщаем об ошибке.
Понятно, что такой метод разбора потенциально медленнее, чем рекурсивный спуск без возвратов, но взамен нам удается сохранить грамматику в ее оригинальном виде и сэкономить усилия программиста.
Именно таким образом реализован синтаксический разбор в демонстрационном компиляторе С-бемолль. Например, в следующем фрагменте реализован метод, определяющий по ходу разбора, является ли данная конструкция оператором-выражением или описанием. И та, и другая конструкция могут начинаться с последовательности идентификаторов, разделенных точками, и, возможно, содержащими квадратные скобки (см. пример на следующей странице):
AST.Stmt stmt_or_decl ()
{
Lexer saved = new Lexer (lexer);
try {
AST.Type t = type_opt ();
if (lexer.Is (Token.Tag.Ident))
return decl_tail (saved.Curr.coor, t);
}
catch (ParseFailed) {
lexer = saved;
AST.Expr expr = this.expr ();
return new AST.Stmt.Expr (compiler,
saved.Curr.coor|lexer.req (Token.Tag.Semicolon).coor, expr);
}
}В блоке try мы пытаемся разобрать конструкцию, предполагая, что это описание. Если это нам не удалось, то анализатор создает исключение, которое затем отлавливается в блоке catch и приводит к повторному разбору той же конструкции как выражения.
Литература к лекции
- А. Ахо, Р. Сети, Дж. Ульман "Компиляторы: принципы, технологии и инструменты", М.: "Вильямс", 2001, 768 стр.
- D. Grune, C. H. J. Jacobs "Parsing Techniques - A Practical Guide", Ellis Horwood, 1990 (полный текст этой книги был доступен в Интернете на момент написания курса, см. http://www.cs.vu.nl/~dick/PTAPG.html)