Инспектор
Вы можете этот курс.
Опубликован: 12.07.2010 | Уровень: специалист | Доступ: платный | ВУЗ: Алтайский государственный университет
Лекция 4:
Многоядерные процессоры с низким энергопотреблением
Аннотация: Лекция посвящена двум интересным разработкам, нацеленным на минимизацию энергопотребления процессора при сохранении высокой производительности. Демонстрируются два различных подхода к управлению производительностью и энергопотреблением: с одной стороны — локальное управление тактовой частотой и напряжением питания ядра, с другой самосинхронная схемотехника с полным отключением ядер во время простоя
или ожидания данных.
Ключевые слова: процессор, ПО, структурная схема, ASAP, генератор, массив, затраты, самотестирование, энергия, производительность, распознавание, запись, арбитраж, архитектура, ядро, память, FIFO, RISC, сложение, вычитание, вычисление, ACSE, декодирование, SAD, выход, связь, тактовая частота, задержка передачи, шина, Дополнение, контроллер, энергопотребление, кодер, IEEE 802.11a, scalable, embedded, array, сенсорные системы, параллелизм, стековая архитектура, QPSK, параллельная обработка данных, программное обеспечение, анализ, PID, множества, параллельный порт, АЦП, ЦАП, сокращенный набор команд, постоянная память, парадигма, сеть, ПЗУ, RS-232, SPI, QAM, пассивный, синхронизация процессов, представление, исполнение, порт, активный, источник события, вывод, межпроцессорный, адрес, значение, блокировка, средство синхронизации, бит, операции, микропроцессор, ОЗУ, АЛУ, слово, регистр, serdes, MIPS, время выполнения, мощность, счетчик, слот, стек, комбинаторная логика, PC, время доступа, RAM, ROM, адресация, указатель, выборка, MLT-3, Rotation, polys, triangle, tapping, DAC, SL, функции ввода/вывода, serial, чтение данных, поддержка, загрузка, система команд, расширяемость, список, остаток, команда, аргумент, литерал, аналого-цифровые преобразователи, Data, процессорное ядро, jump, полнодуплексный режим, UART, интерфейс, входной, очередь, генератор функций, двунаправленные линии, arm, программная реализация, время реакции, умножение, деление, компилятор, симулятор, Windows, mac os, IDE, Директория, шаблон, файл, VFP, компиляция, программа, определение, путь, имя файла, объект, SIM, приложение, драйвер, загрузчик, мультикомпьютер, распределенная память, диаграмма последовательности, сдвиговый регистр, вершина стека, LSB, множитель, размерность, алгоритм, исключение, макроопределения, макрос, код компилятора, скорость передачи, цикла, обработка сигналов, функция, потеря точности, запаздывания, коэффициенты Фурье, CAS, обратное преобразование, разбиение, Произведение, диаграмма потока данных, коэффициенты, основная программа, дамп, группа, интерполяция, генератор псевдослучайных чисел, спящий режим, ассемблер
167-ядерная вычислительная платформа — AsAP-II
167-ядерная вычислительная платформа [16,17] (далее — процессор), разработанная в Калифорнийском университете в Дэвисе, реализована в кремнии фирмой STMicroelectronics по 65-нм технологическому циклу. Данный процессор предназначен прежде всего для цифровой обработки сигналов, коммуникационных функций, мультимедийных приложений. Процессор содержит 164 программируемых ядра с динамическим управлением напряжением питания и тактовой частотой, три специализированных процессора, три буфера разделяемой памяти по 16 Кбайт. Все компоненты процессора тактируются собственными независимыми генераторами и соединены специальной внутрикристальной сетью. Структурная схема процессора [17] представлена на рис. 4.1. Аналогично процессору AsAP [16] каждое из ядер имеет 16-разрядные шины данных, 40-битный аккумулятор, независимый тактовый генератор с возможностью останова.
Гомогенный массив из 164 ядер уменьшает затраты на разработку приложений и позволяет приложениям работать по различным путям в целях повышения надежности работы и самотестирования и настройки.
Для повышения соотношения "энергия/производительность" выделены специализированные процессоры, адаптированные для задач цифровой обработки сигналов (быстрое преобразование Фурье), коммуникаций (Витерби-декодер), мультимедиа-приложений (распознавание движений). Три разделяемых буфера памяти по 16 Кб каждый обеспечивают скоростную запись данных и их хранение, поддерживают приоритеты портов, арбитраж обращений, множественные режимы адресации, включая программируемый генератор адреса. Специализированные процессоры и разделяемые блоки памяти также имеют независимые локальные тактовые генераторы. Данная архитектура построения получила название "глобально асинхронной локально синхронной" (GALS). Взаимодействие осуществляется при помощи буферов FIFO с двойным тактированием.
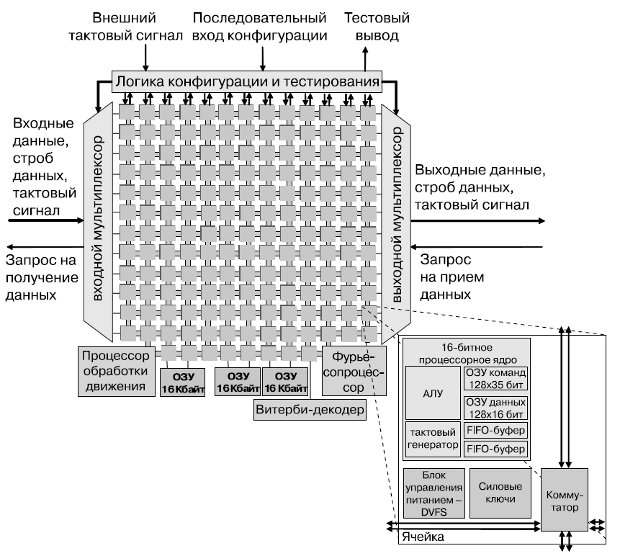
Каждое ядро имеет память команд в 128 35-битных слов, 128 слов 16-разрядной памяти данных, два 16-разрядных FIFO-буфера по 64 слова, одновыходной шестиуровневый конвейер RISC. RISC-ядра поддерживают более 60 базовых инструкций, включая байтовое сложение/вычитание, вычисление минимума/максимума и абсолютных значений, переходы, возвраты из подпрограмм, инструкции условного выполнения, циклы, блок с плавающей точкой ( рис. 4.2). Задача вычисления квадратного корня (CORDIC) выполняется за 216 циклов (в процессоре AsAP операция занимала 628 циклов).

Процессор БПФ может динамически переключаться между вычислением прямого и обратного преобразования Фурье с количеством отсчетов от 16 до 4096 путем вычисления комплексной 4- или 2-точечной "бабочки" за цикл.
Конфигурируемый Витерби-процессор содержит 8 ACS-модулей и может осуществлять декодирование кодов вплоть до длины 10.
Процессор детектора движения поддерживает несколько фиксированных и программируемых поисковых алгоритмов, отвечающих алгоритму H.264, выполняет более 14 миллиардов операций (SADs) в секунду на частоте 880 МГц.
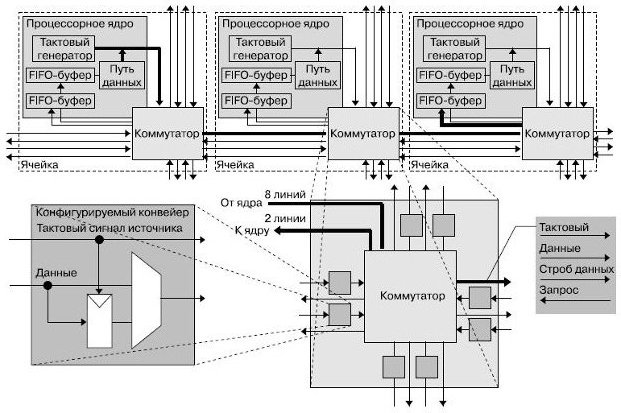
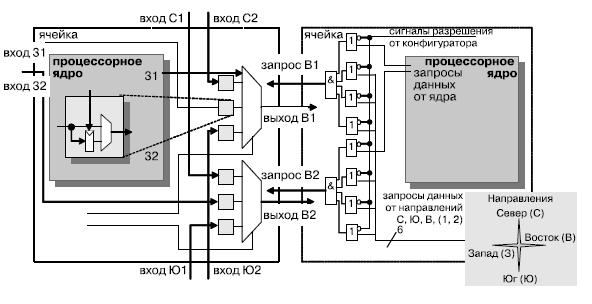
Ядра процессора обмениваются данными посредством конфигурируемых связей между соседними процессорами и длинных связей. Связи являются циклически переключаемыми и статически конфигурируемыми, что хорошо согласуется с технологией локальной синхронизации, используемой в процессоре. Структура связей включает два входа вычислительного ядра и одиночный выход, который динамически подключается к восьми выходам ячейки. Каждая связь содержит 16-разрядную шину данных, сигнал синхронизации источника, разрешающий сигнал (стробирующий) и сигнал запроса на смену направления, используемый для контроля потока. Ограниченные только искажениями тактового сигнала, связи могут быть сконфигурированы для передачи данных сквозь процессор в выбранном выделенном канале без привлечения промежуточных процессоров и безотносительно их текущих напряжений питания и тактовых частот ( рис. 4.3). Данные могут быть помещены в конвейер в каждой ячейке для достижения полной скорости при передачи на длинные расстояния или передаваться напрямую, если дистанция мала или тактовая частота источника данных мала ( рис. 4.4). Такие меры снижают общую задержку передачи данных.
Для уменьшения рассеяния энергии, когда ядра не полностью загружены, ядра могут менять собственное напряжение питания и тактовую частоту. Ядра меняют напряжение питания, подключая свои питающие выводы (VddCore) к одной из двух глобальных шин питания [16] ( рис. 4.5). Локальные генераторы подключены к шине VddOsc и позволяют сглаживать сбои генерации при переключении питающих напряжений. Шина VddAlwaysOn питает цепи устройств коммуникации и конфигурации, а также цепи динамического управления питанием и коммуникациями. Также возможно отключение линий VddCore неиспользуемых процессоров от питающих глобальных шин (уменьшая таким образом потребление ядра более чем в 100 раз).
Питающее напряжение и тактовая частота ядра могут быть установлены следующими путями: конфигурируемым аппаратным (HW) контролле ром; программой, выполняемой на ядре; статически заданной конфигурацией. Ключевой идеей является то, что состояние HW-контроллера зависит от наполнения FIFO-буфера(ов) и сигнала остановки/простоя процессора. Т. е. переполняемое FIFO или редкие остановы показывают, что ядро работает слишком медленно, а опустошение FIFO или частые остановы показывают, что оно работает быстрее, чем необходимо. Поскольку характеристики FIFO и остановов различны, для различных задач предусмотрен конфигурируемый КИХ/БИХ-фильтр нижних частот, сглаживающий разброс значений для дальнейшего использования. Пороги срабатываний датчика останова/простоя также конфигурируемы.
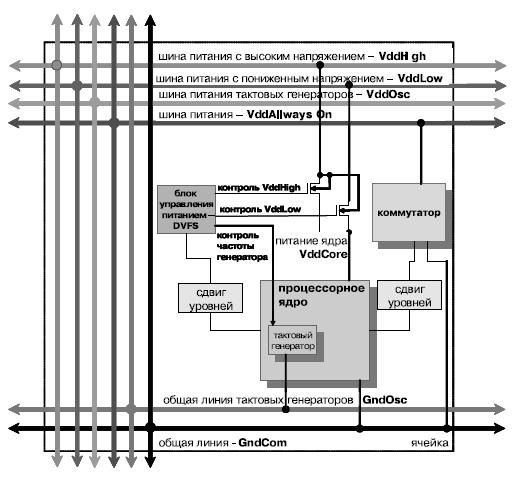
Риск динамического переключения питания ядер в многоядерной системе заключается в проседании локального напряжения на питании ядра и шум на глобальных шинах питания. Для снижения негативных эффектов контролер выключает генератор на время переключения питания. В дополнение к этому силовые p-МОП транзисторные ключи каждого переключателя организованы как 48 включенных параллельно ключей с индивидуальными сигнальными линиями и конфигурируемым временем срабатывания. Контроллер DVFS ( рис. 4.6), цепи межъядерных коммуникаций и р-МОП ключи находятся вокруг ядра и запитываются VddAlwaysOn-шиной, что делает возможным изменение уровня напряжения только между ядром и его окружением.

Энергопотребление отдельного ядра при полной загрузке на частоте 1,07 ГГц и питании 1,2 В составляет около 48,4 мВт. При напряжении питания 0.675В ядра работают на частоте 66 МГц и потребляют 0,61 мВт. Таким образом, в зависимости от режима энергопотребление процессора в целом составляет от 101 мВт до 7,93 Вт.
По результатам тестирования, 9-процессорный JPEG-кодер, работающий при напряжениях питания 1,3 В и 0,8 В, достигает примерно 8% экономии энергии по сравнению с тем же кодером, работающим исключительно при питании 1,3 В. Приемник, полностью совместимый со стандартом IEEE 802.11a/g, реализован с использованием 39 процессорных ядер (при этом задействованы только связи между соседними ячейками), плюс специализированные процессоры БПФ и Витерби. Применяя длинные связи, приемник можно реализовать на 27 ядрах — почти на треть меньше. При симуляции последняя версия приемника рассеивает примерно 75 мВт при работе на частоте 690 МГц и скорости данных 54 Мб/с в режиме реального времени (включая 2,7 мВт для БПФ-процессора и 5,5 мВт для Витерби). Данная реализация в 34 раза быстрее, чем реализация на процессоре TI C62x, а также в 19 раз быстрее и в 28 раз менее потребляет, чем реализация на LART [17].