| Россия, г. Смоленск ул. Николаева д. 19а кв. 56 |
Инспектор
Вы можете этот курс.
Опубликован: 10.10.2007 | Уровень: профессионал | Доступ: платный | ВУЗ: Московский государственный университет имени М.В.Ломоносова
Лекция 2:
Словарные методы сжатия данных
Пример
Попробуем сжать строку "кот_ломом_колол_слона" длиной 21 символ. Пусть длина буфера равна 7 символам, а размер словаря больше длины сжимаемой строки. Условимся также, что:
- нулевое смещение зарезервировали для обозначения конца кодирования;
- символ
 соответствует единичному смещению относительно символа
соответствует единичному смещению относительно символа 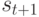 , с которого начинается буфер;
, с которого начинается буфер; - если имеется несколько фраз с одинаковой длиной совпадения, то выбираем ближайшую к буферу;
- в неопределенных ситуациях - когда длина совпадения нулевая - смещению присваиваем единичное значение.
| Шаг | Скользящее окно | Совпадающая фраза | Закодированные данные | |||
|---|---|---|---|---|---|---|
| Словарь | Буфер | i | j | s | ||
| 1 | - | кот_лом | - | 1 | 0 | 'к' |
| 2 | к | от_ломо | - | 1 | 0 | 'о' |
| 3 | ко | т_ломом | - | 1 | 0 | 'т' |
| 4 | кот | _ломом_ | - | 1 | 0 | '_' |
| 5 | кот_ | ломом_к | - | 1 | 0 | 'л' |
| 6 | кот_л | омом_ко | о | 4 | 1 | 'м' |
| 7 | кот_лом | ом_коло | ом | 2 | 2 | '_' |
| 8 | кот_ломом_ | колол_с | ко | 10 | 2 | 'л' |
| 9 | кот_ломом_кол | ол_слон | ол | 2 | 2 | '_' |
| 10 | ..._ломом_колол_ | слона | - | 1 | 0 | 'с' |
| 11 | ...ломом_колол_с | лона | ло | 5 | 2 | 'н' |
| 12 | ...ом_колол_слон | а | - | 1 | 0 | 'а' |
Для кодирования i нам достаточно 5 битов, для j нужно 3 бита, и пусть символы требуют 1 байта для своего представления. Тогда всего мы потратим 12·(5+3+8) = 192 бита. Исходно строка занимала 21·8 = 168 битов, т.е. LZ77 кодирует нашу строку еще более расточительным образом. Не следует также забывать, что мы опустили шаг кодирования конца последовательности, который потребовал бы еще как минимум 5 битов (размер поля i = 5 битам).
Процесс кодирования можно описать следующим образом.
while ( ! DataFile.EOF() ){
/*найдем максимальное совпадение, в match_pos получим
смещение i, в match_len - длину j, в unmatched_sym
- первый несовпавший символ st+1+j; считаем также, что в
функции find_match учитывается ограничение на длину
совпадения
*/
find_match (&match_pos, &match_len, &unmatched_sym);
/*запишем в файл сжатых данных описание найденной
фразы, при этом длина битового представления i
задается константой OFFS_LN, длина представления
j - константой LEN_LN, размер символа s принимаем
равным 8 битам
*/
CompressedFile.WriteBits (match_pos, OFFS_LN);
CompressedFile.WriteBits (match_len, LEN_LN);
CompressedFile.WriteBits (unmatched_sym, 8);
for (i = 0; i <= match_len; i++){
// прочтем очередной символ
c = DataFile.ReadSymbol();
//удалим из словаря одну самую старую фразу
DeletePhrase ();
/*добавим в словарь одну фразу, начинающуюся с
первого символа буфера
*/
AddPhrase ();
/*сдвинем окно на 1 позицию, добавим в конец буфера
символ с
*/
MoveWindow(c);
}
}
CompressedFile.WriteBits (0, OFFS_LN);
Пример
2.1.
Пример подтвердил, что способ формирования кодов в LZ77 неэффективен и позволяет сжимать только сравнительно длинные последовательности. До некоторой степени сжатие небольших файлов можно улучшить, используя коды переменной длины для смещения i. Действительно, даже если мы используем словарь в 32 кбайт, но закодировали еще только 3 кбайт, то смещение реально требует не 15, а 12 битов. Кроме того, происходит существенный проигрыш из-за использования кодов одинаковой длины при указании длин совпадения j. Например, для уже упоминавшейся электронной версии романа "Бесы" были получены следующие частоты использования длин совпадения (см. табл. 2.4):
| j | Количество раз, когда максимальная длина совпадения была равна j |
|---|---|
| 0 | 136 |
| 1 | 1593 |
| 2 | 4675 |
| 3 | 11165 |
| 4 | 20047 |
| 5 | 26939 |
| 6 | 28653 |
| 7 | 24725 |
| 8 | 19702 |
| 9 | 14767 |
| 10 | 10820 |
 11 11 |
27903 |
Из таблицы следует, что в целях минимизации закодированного представления для j = 6 следует использовать код наименьшей длины, так как эта длина совпадения встречается чаще всего.
Хотя авторы алгоритма и доказали, что LZ77 может сжать данные не хуже, чем любой специально на них настроенный полуадаптивный словарный метод, из-за указанных недостатков это выполняется только для последовательностей достаточно большого размера.
Что касается декодирования сжатых данных, то оно осуществляется путем простой замены кода на блок символов, состоящий из фразы словаря и явно передаваемого символа. Естественно, декодер должен выполнять те же действия по изменению окна, что и кодер. Фраза словаря элементарно определяется по смещению и длине, поэтому важным свойством LZ77 и прочих алгоритмов со скользящим окном является очень быстрая работа декодера.
Алгоритм декодирования может иметь следующий вид.
for (;;) {
// читаем смещение
match_pos = CompressedFile.ReadBits (OFFS_LN);
if (!match_pos)
// обнаружен признак конца файла, выходим из цикла
break;
// читаем длину совпадения
match_len = CompressedFile.ReadBits (LEN_LN);
for (i = 0; i < match_len; i++) {
//находим в словаре очередной символ совпавшей фразы
c = Dict (match_pos + i);
/*сдвигаем словарь на 1 позицию, добавляем в его начало с */
MoveDict (c)
/*записываем очередной раскодированный символ в
выходной файл */
DataFile.WriteSymbol (c);
}
/*читаем несовпавший символ, добавляем его в словарь и
записываем в выходной файл
*/
c = CompressedFile.ReadBits (8);
MoveDict (c)
DataFile.WriteSymbol (c);
}Алгоритмы со скользящим окном характеризуются сильной несимметричностью по времени - кодирование значительно медленнее декодирования, поскольку при сжатии много времени тратится на поиск фраз.
Упражнение: Предложите несколько более эффективных способов кодирования результатов работы LZ77, чем использование простых кодов фиксированной длины.