
|
Здравствуйие! Я хочу пройти курс Введение в принципы функционирования и применения современных мультиядерных архитектур (на примере Intel Xeon Phi), в презентации самостоятельной работы №1 указаны логин и пароль для доступ на кластер и выполнения самостоятельных работ, но войти по такой паре логин-пароль не получается. Как предполагается выполнение самосоятельных работ в этом курсе? |
Инспектор
Вы можете этот курс.
Опубликован: 30.05.2014 | Уровень: для всех | Доступ: платный | ВУЗ: Нижегородский государственный университет им. Н.И.Лобачевского
Лекция 1:
Обзор архитектуры современных многоядерных процессоров
Параллелизм как основа высокопроизводительных вычислений
Без каких-либо особых преувеличений можно заявить, что все развитие компьютерных систем происходило и происходит под девизом "Скорость и быстрота вычислений". Если быстродействие первой вычислительной машины ENIAC составляло всего несколько тысяч операций в секунду, то самый быстрый на ноябрь 2012 г. суперкомпьютер Titan может выполнять уже несколько квадриллионов (1015) команд. Темп развития вычислительной техники просто впечатляет – увеличение скорости вычислений в триллионы (1012) раз немногим более чем за 60 лет! Для лучшего понимания необычности столь стремительного развития средств вычислительной техники часто приводят яркие аналогии, например: если бы автомобильная промышленность развивалась с такой же динамикой, то сейчас автомобили весили бы порядка 200 граммов и тратили бы несколько литров бензина на миллионы километров!
История развития вычислительной техники представляет увлекательное описание замечательных научно-технических решений, радости побед и горечи поражений. Проблема создания высокопроизводительных вычислительных систем относится к числу наиболее сложных научно-технических задач современности, и ее разрешение возможно только при всемерной концентрации усилий многих талантливых ученых и конструкторов, предполагает использование всех последних достижений науки и техники и требует значительных финансовых инвестиций. Здесь важно отметить, что при общем росте скорости вычислений в 1012 раз быстродействие самих технических средств вычислений увеличилось всего в несколько миллионов раз. И дополнительный эффект достигнут за счет введения параллелизма буквально на всех стадиях и этапах вычислений.
Не ставя целью в рамках данного курса подробное рассмотрение истории развития компьютерного параллелизма, отметим, например, организацию независимости работы разных устройств ЭВМ (процессора и устройств ввода-вывода), появление многоуровневой памяти, совершенствование архитектуры процессоров (суперскалярность, конвейерность, динамическое планирование). Дополнительная информация по истории параллелизма может быть получена, например, в [67]; здесь же выделим как принципиально важный итог – многие возможные пути совершенствования процессоров практически исчерпаны (так, возможность дальнейшего повышения тактовой частоты процессоров ограничивается рядом сложных технических проблем) и наиболее перспективное направление на данный момент времени состоит в явной организации многопроцессорности вы-числительных устройств.
Ниже будут более подробно рассмотрены основные способы организации многопроцессорности – симметричной мультипроцессорности (Symmetric Multiprocessor, SMP), одновременной многопотоковости (Simultaneous Multithreading, SMT) и многоядерности (multicore).
Симметричная мультипроцессорность
Организация симметричной мультипроцессорности (Symmetric Multiprocessor, SMP), когда в рамках одного вычислительного устройства имеется несколько полностью равноправных процессоров, является практически первым использованным подходом для обеспечения многопроцессорности – первые вычислительные системы такого типа стали появляться в середине 50-х – начале 60-х годов, однако массовое применение SMP систем началось только в середине 90-х годов.
Следует отметить, что SMP системы входят в группу MIMD (multi instruction multi data) вычислительных систем в соответствии с классификацией Флинна. Поскольку эта классификация приводит к тому, что практически все виды параллельных систем (несмотря на их существенную разнородность) относятся к одной группе MIMD, для дальнейшей детализации класса MIMD предложена практически общепризнанная структурная схема [47, 99] – см. рис. 1.1. В рамках данной схемы дальнейшее разделение типов многопроцессорных систем основывается на используемых способах организации оперативной памяти в этих системах. Данный поход позволяет различать два важных типа многопроцессорных систем – multiprocessors (мультипроцессоры, или системы с общей разделяемой памятью) и multicomputers (мультикомпьютеры, или системы с распределенной памятью).
Для дальнейшей систематики мультипроцессоров учитывается способ построения общей памяти. Возможный подход – использование единой (централизованной) общей памяти (shared memory) – см. рис. 1.2. Такой подход обеспечивает однородный доступ к памяти (uniform memory access, UMA) и служит основой для построения векторных параллельных процессоров (parallel vector processor, PVP) и симметричных мультипроцессоров (symmetric multiprocessor, SMP). Среди примеров первой группы – суперкомпьютер Cray T90, ко второй группе относятся IBM Server, Sun StarFire, HP Superdome, SGI Origin и др.
Одной из основных проблем, которые возникают при организации параллельных вычислений на такого типа системах, является обеспечение информационной целостности (когерентности) кэшей (cache coherence problem).
Дело в том, что при наличии общих данных, копии значений одних и тех же переменных могут оказаться в кэшах разных процессоров. Если в такой ситуации (при наличии копий общих данных) один из процессоров выполнит изменение значения разделяемой переменной, то значения копий в кэшах других процессорах окажутся несоответствующими действительности и их использование приведет к некорректности вычислений.
Существует две методики дублирования данных их кэша в оперативную память: обратная запись (write back) и сквозная запись (write through). При использовании сквозной записи в кэш все записываемые данные сразу дублируются в оперативной памяти. При использовании обратной записи данные помещаются только в кэш и переписываются в оперативную память только тогда, когда необходимо освободить строку кэша. При использовании этих методик может нарушиться информационная целостность данных. Так, при использовании обратной записи модификация строки кэша никак не отразится на состоянии копий этой строки в других кэшах и оперативной памяти. Остальные процессоры не будут "знать", что в их кэшах находиться устаревшие данные. Для обеспечения информационной целостности данных при использовании сквозной записи необходимо дублировать записываемые данные не только в оперативную память, но и во все кэши, которые содержат эти данные, что негативно сказывается на эффективности системы.
Обеспечение однозначности кэшей может быть достигнуто на программном или аппаратном уровнях. Вся тяжесть обеспечения информационной целостности кэшей при использовании программных методов ложится на операционную систему и компилятор. При сборке программы компилятор должен определить те переменные и элементы данных, которые могут потенциально нарушить целостность данных и запретить их кэширование. Реализовать подобную стратегию эффективно очень тяжело, т.к. запрещать кэширование участков памяти необходимо только в тех случаях, когда это требуется для обеспечения однозначности. Блокирование кэширования во всех остальных случаях (когда информационной целостности данных ничто не угрожает) приведёт к необоснованному снижению быстродействия программы.
Обеспечение однозначности кэшей обычно реализуется на аппаратном уровне. Аппаратные методы позволяют выполнять действия, необходимые для обеспечения когерентности данных, только в тех случаях, когда это требуется при выполнении программы, что приводит к более эффективному использованию кэшей. Существует множество аппаратных методов обеспечения информационной целостности данных. Более подробно об этом можно прочитать в [1]. Мы рассмотрим метод с использованием про-токола MESI.
Протокол MESI основан на введении четырёх состояний для каждой строки кэша:
modified (строка была изменена и изменения не отражены в оперативной памяти),
exclusive (данные в строке кэша и оперативной памяти одинаковы, в остальных кэшах этих данных нет),
shared (данные в строке кэша и оперативной памяти одинаковы, в каких-то других кэшах этих данные тоже присутствуют),
invalid (строка содержит недостоверные данные).
При выполнении операций чтения и записи может возникнуть одна из двух ситуаций: промах (данных нет в кэше, либо данные недостоверны) или попадание (данные присутствуют в кэше). Операция чтения при попадании в кэш никак не изменяет состояния строки. Операция записи при попадании выполняется по-разному, в зависимости от состояния строки. Если строка имела состояние exclusive или modified, то текущий процессор имеет исключительное право владения этой строкой и изменяет состояние строки на modified. Если строка имела состояние shared, то состояние копи строки в других кэшах меняется на invalid, а текущий процессор обновляет данных в кэше и изменяет состояние строки на modified. Операции чтения при промахе может выполняться по-разному в зависимости от состояния других кэшей. Если в каком-либо кэше содержится копия строки в состоянии exclusive или shared, то данные загружаются в кэш из оперативной памяти, а строка помечается как shared в этих кэшах. Если в каком-либо кэше содержится копия строки в состоянии modified, то этот кэш заблокирует чтение из памяти и инициирует запись строки в оперативную память, после чего изменит состояние строки на shared. Если ни в одном из кэшей нет копии строки, то блок данных загружается из оперативной памяти, а строка помечается как exclusive. Операция записи при промахе инициирует чтение блока данных из оперативной памяти и устанавливает состояние строки в значение modified. При этом, если в каком-либо кэше находилась копия данных в состоянии modified, то сначала данные из этого кэша записываются в оперативную память, а строка помечается как invalid. Все кэши, которые содержали копию данных в состоянии shared или exclusive переходят в состояние invalid.
Рассмотренный выше механизм будет работать только для кэшей, которые имеют выход на общую магистраль данных. По магистрали данных циркулируют потоки информации между отдельными процессорами и оперативной памятью и сигналы, необходимые для обеспечения когерентности данных к кэшах. При увеличении количества процессоров, поток данных по магистрали тоже увеличивается. Это приводит к снижению скорости вычислений и затрудняет создание систем с достаточно большим количеством процессоров. Как правило, на общую магистраль имеют выходы кэши L2. Для обеспечения когерентности кэшей L1 используются более сложные алгоритмы (особенно при использовании обратной записи).
На данный момент широко используется модифицированный протокол MESI в котором добавлено дополнительное состояние, позволяющее эффективнее решать проблему когерентности данных за счёт загрузки требуемых данных из соседнего кэша, а не из оперативной памяти. Intel использует протокол MESIF, AMD – MOESI.
Наличие общих данных при выполнении параллельных вычислений приводит к необходимости синхронизации взаимодействия одновременно выполняемых потоков команд. Так, если изменение общих данных требует для своего выполнения некоторой последовательности действий, то необходимо обеспечить взаимоисключение (mutual exclusion), с тем чтобы эти изменения в любой момент времени мог выполнять только один командный поток. Задачи взаимоисключения и синхронизации относятся к числу классических проблем, и их рассмотрение при разработке параллельных программ является одним из основных вопросов параллельного программирования.
Общий доступ к данным может быть обеспечен и при физически распределенной памяти (при этом, естественно, длительность доступа уже не будет одинаковой для всех элементов памяти) – см. рис. 1.2. Такой подход именуется как неоднородный доступ к памяти (non-uniform memory access, или NUMA). Среди систем с таким типом памяти выделяют:
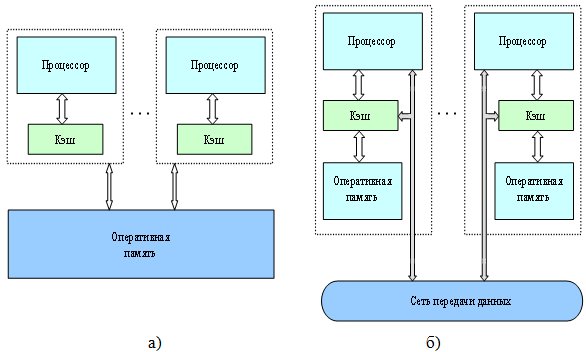
Рис. 1.2. Архитектура многопроцессорных систем с общей (разделяемой) памятью: системы с (а) однородным и (б) неоднородным доступом к памяти
- Системы, в которых для представления данных используется только локальная кэш-память имеющихся процессоров (cache-only memory architecture, или COMA); примерами таких систем являются KSR-1 и DDM.
- Системы, в которых обеспечивается когерентность локальных кэшей разных процессоров (cache-coherent NUMA, или CC-NUMA); среди систем данного типа – SGI Origin 2000, Sun HPC 10000, IBM/Sequent NUMA-Q 2000.
- Системы, в которых обеспечивается общий доступ к локальной памяти разных процессоров без поддержки на аппаратном уровне когерентности кэша (non-cache coherent NUMA, или NCC-NUMA); к данному типу относится, например, система Cray T3E.
Использование распределенной общей памяти (distributed shared memory, DSM) упрощает проблемы создания мультипроцессоров (известны примеры систем с несколькими тысячами процессоров), однако возникающие при этом проблемы эффективного использования распределенной памяти (время доступа к локальной и удаленной памяти может различаться на несколько порядков) приводят к существенному повышению сложности параллельного программирования.
Svetlana Svetlana