Инспектор

Вы можете этот курс.
Лекция 6: Оптимальное потактовое расписание выполнения работ в многофункциональном арифметическо-логическом устройстве
"Быстрая" компоновка "длинных" командных слов
Рассмотрим пример счета значений выражений операторов присваивания, составляющих линейный участок программы.
Пусть линейный участок программы соответствует счету следующих выражений:
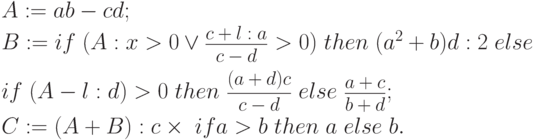 |
( 6.1) |
Составим план загрузки ИУ, не вдаваясь в частные особенности системы команд. Т.е. мы сначала произведем компоновку "длинных" командных слов на основе совместно выполняемых операций, но не команд. Особенности системы команд могут потребовать "размножения" некоторых полученных командных слов с учетом необходимости подготовительных операций засылки в регистры, передачи данных между ИУ и др. Но это уже не повлияет на результат произведенного распараллеливания выполнения операций, а будет служить только его обслуживанию.
Запишем программу выполнения линейного участка (6.1) в ПОЛИЗ:
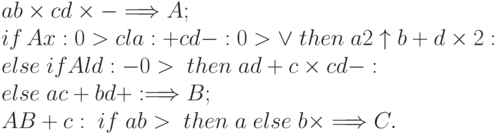 |
( 6.2) |
Предположим, что все данные, необходимые для выполнения линейного участка, первоначально находятся в ОП. Тогда очевидно, что для минимизации потерь времени на считывание неоднократно используемых данных из ОП в СОЗУ и для того, чтобы ускорить использование данных в производимых над ними операциях, с учетом низкой скорости работы ОП по сравнению со скоростью работы операционных устройств, необходимо считывание из ОП, обусловленное цепочками имен, производить в следующем порядке.
Цепочки имен надо просматривать слева направо (рассматривая запись (6.2) как линейную). Внутри же каждой цепочки считывание по именам (по адресам данных, возможно, найденным на основе переменных с индексами) надо производить справа налево, — для скорейшего начала выполнения цепочек операций, следующих за цепочками имен.
С учетом этого замечания, составим информационный граф G счета данного линейного участка. При этом количество тактов выполнения каждой операции (кроме считывания, где время — случайная величина, принадлежащая известному диапазону) считаем заданным. Веса — выбранное для примера время выполнения операций — сопровождают вершины в графе.
Ярусно-параллельная форма информационного графа наглядно показывает возможность поярусного распределения информационно независимых работ между ИУ для их одновременного выполнения. Однако такое выполнение в общем случае сдерживается реальной картиной динамической загрузки ИУ, которая обусловлена разным временем выполнения операций, объемом работ, предшествующих выполнению каждой конкретной операции. Поэтому распределение заданий и формирование на его основе командных слов должно быть не поярусным, а определяться в динамике имитации работы ИУ.
Можно имитировать выполнение линейного участка на стеке, как это приводилось в лекции 4. Однако там это рассматривалось в рамках одного оператора присваивания и в динамике действительного выполнения. Линейный участок при статическом анализе, как в примере, может содержать несколько таких операторов. В таком случае вводится дополнительный существенный элемент частичной упорядоченности работ, который необходимо использовать при программировании совместного выполнения операторов присваивания.
В нашем примере значение А — результат выполнения первого оператора присваивания используется при счете второго и третьего операторов присваивания. То же касается значения В. Это налагает ограничения на порядок выполнения операторов присваивания, требует синхронизации их параллельного выполнения. Ведь при составлении информационного графа, определяя последовательность операций считывания, мы пропустили считывание А и В, т.к. ясно видим, пока не формально, что эти величины не считываются, а рассчитываются. Информацию об этом надо как-то "сообщить" компоновщику командных слов. То есть мы пока не выделили в формальном виде всей информации о частичной упорядоченности работ, содержащихся в линейном участке программы.
Целесообразно применить уже проверенный (реализованный в "Эльбрус-2") способ трансляции программы линейного участка, записанного в ПОЛИЗ, — в программу в трехадресных командах. Такие команды соответствуют законченным операторам выполнения одно- и двуместных операций и содержат лаконичную, но полную информацию о порядке использования и преобразования данных, в том числе — общих.
Воспользуемся изложенным в лекции 4 алгоритмом перевода программы из ПОЛИЗ в трехадресные команды, следуя приведенным выше рекомендациям относительно считывания. Однако с учетом многоразового использования некоторых величин придется расширить и возможности использования списка свободных регистров, изменить алгоритм назначения отмеченных в нем регистров. Снабдим этот список таблицей соответствия — указанием, какой регистр какой величине соответствует. Эту таблицу будем составлять при формировании команд начального считывания из ОП.
Для исключения повторного считывания при анализе других линейных участков, может быть организована преемственность указанных таблиц соответствия. То есть в общем случае можно считать, что такая таблица уже существует и ее необходимо только уточнить.