| Рабочим названием платформы .NET было |
Инспектор
Вы можете этот курс.
Опубликован: 28.06.2006 | Уровень: специалист | Доступ: платный | ВУЗ: Московский государственный технический университет им. Н.Э. Баумана
Лекция 3:
Структура программных компонентов
Обзор структуры PE-файла
Исполняемые файлы в формате PE, кроме всего прочего, обладают одной приятной особенностью - PE-файл, загруженный в оперативную память для исполнения, почти ничем не отличается от своего представления на диске. PE-файл сравнивается со сборным домом: стоит привезти его на место, свинтить отдельные детали, подключить электричество и водопровод, и все - можно жить.
Благодаря этой особенности загрузчик операционной системы должен просто отобразить отдельные части PE-файла в адресное пространство процесса, подправить абсолютные адреса в исполняемом коде в соответствии с таблицей релокаций, создать таблицу адресов импорта и затем передать управление на точку входа (в случае exe-файла).
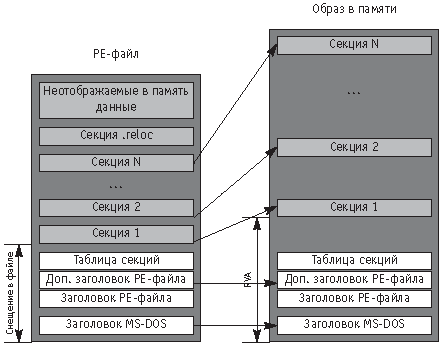
На рис. 2.3 изображена схема PE-файла. Слева показана структура файла на диске, а справа - его образ в памяти. Мы видим, что PE-файл начинается с заголовков, за которыми располагаются несколько секций.
В секциях размещаются код и данные исполняемого файла, а также служебная информация, необходимая загрузчику (например, секция ".reloc" на схеме содержит таблицу релокаций). Секции в оперативной памяти должны быть выровнены по границам страниц, поэтому загрузчик отображает каждую секцию, начиная с новой страницы адресного пространства процесса. Это приводит к тому, что в памяти секции, как правило, располагаются менее компактно, чем в файле (и это отражено на схеме).
Так как расположение элементов PE-файла в памяти и на диске отличаются, для их локализации приходится вводить два понятия: относительный виртуальный адрес элемента в памяти (Relative Virtual Address - RVA) и смещение элемента в файле (file offset).
RVA некоторого элемента PE-файла - это разность виртуального адреса данного элемента и базового адреса, по которому PE-файл загружен в память. Например, если файл загружен по адресу 0x400000, и некоторый элемент в нем располагается по адресу 0x402000, то RVA этого элемента равен (0x402000 - 0x400000) = 0x2000.
Смещение элемента в файле представляет собой количество байт, которое надо отсчитать от начала файла, чтобы попасть на начало элемента. Смещения используются гораздо реже, чем RVA, потому что основное их назначение состоит в обеспечении соответствия положения секций PE-файла в файле на диске и в памяти.
Загрузчик формирует образ PE-файла в памяти таким образом, что соблюдается следующее правило: пусть ox и oy - смещения каких-то элементов в файле, а rx и ry - RVA этих элементов, тогда если ox < oy, то rx < ry.
Секции
Секция в PE-файле представляет либо код, либо некоторые данные (глобальные переменные, таблицы импорта и экспорта, ресурсы, таблица релокаций). Каждая секция имеет набор атрибутов, задающий ее свойства. Атрибуты секции определяют, доступна ли секция для чтения и записи, содержит ли она исполняемый код, должна ли она оставаться в памяти после загрузки исполняемого файла, могут ли различные процессы использовать один экземпляр этой секции и т.д.
Исполняемый файл всегда содержит, по крайней мере, одну секцию, в которой помещен исполняемый код. Кроме этого, как правило, в исполняемом файле содержится секция с данными, а динамические библиотеки обязательно включают отдельную секцию с таблицей релокаций.
Каждая секция имеет имя. Оно не используется загрузчиком и предназначено главным образом для удобства человека. Разные компиляторы и компоновщики дают секциям различные имена. Например, компоновщик от Microsoft размещает код в секции ".text", константы - в секции ".rdata", таблицы импорта и экспорта - в секциях ".idata" и ".edata", таблицу релокаций - в секции ".reloc", ресурсы - в секции ".rsrc". В то же время компоновщик фирмы Borland использует имена "CODE" для секций, содержащих код, и "DATA" для секций с данными.
Выравнивание секций в исполняемом файле на диске и в образе файла в памяти чаще всего отличается. В памяти они, как правило, выровнены по границам страниц. В принципе, возможно сгенерировать PE-файл с одинаковым выравниванием секций как на диске, так и в памяти. Смещения элементов в таком файле будут совпадать с их RVA, что существенно упрощает создание генератора кода. Недостатком такого подхода является увеличение размеров PE-файлов.
Выбор базового адреса образа PE-файла в памяти
Давайте обсудим, каким образом загрузчик определяет базовый адрес, по которому нужно загрузить PE-файл. Для exe-файлов это тривиальная задача: в заголовках файла присутствует поле ImageBase, содержащее значение базового адреса. Так как для выполнения exe-файла создается отдельный процесс со своим виртуальным адресным пространством, то обычно не возникает никаких проблем с тем чтобы отобразить файл в это адресное пространство по заданному адресу. Как правило, все exe-файлы содержат в поле ImageBase значение 0x400000.
А вот выбор базового адреса для dll-файла куда сложнее. Дело в том, что динамическая библиотека, как правило, загружается в адресное пространство уже существующего процесса, и хотя dll-файл тоже содержит некоторое значение в поле ImageBase, очень часто может так получиться, что этот адрес уже занят чем-то другим (например, по нему уже загружена другая динамическая библиотека). Что же делать загрузчику, если он не может загрузить dll-файл по заданному адресу? Ему ничего не остается, как загрузить этот файл по какому-то другому адресу. Но тут возникает новая проблема - в файле могут содержаться инструкции с абсолютными адресами (это, в основном, инструкции абсолютных переходов, инструкции вызова подпрограмм, а также инструкции для работы с глобальными данными). При загрузке динамической библиотеки по другому адресу все адреса, содержащиеся в этих инструкциях, становятся неправильными, и загрузчик вынужден их поправить. Для того, чтобы загрузчик мог это сделать, в файле содержится таблица релокаций, в которой прописаны RVA всех абсолютных адресов.
Импорт функций
В PE-файле существует специальная секция ".idata", описывающая функции, который этот файл импортирует из динамических библиотек. Описание импортируемых функций в секции ".idata" приводит к тому, что библиотеки загружаются загрузчиком операционной системы еще до запуска программы. В принципе, необязательно описывать каждую импортируемую функцию в этой секции, так как динамические библиотеки можно загружать с помощью функции LoadLibrary из Win32 API прямо во время выполнения программы.
В процессе загрузки программы осуществляется связывание (binding) функций, импортируемых из динамических библиотек. Связывание подразумевает загрузку соответствующих динамических библиотек и составление таблицы адресов импорта (Import Address Table - IAT). Адрес каждой импортируемой функции заносится в эту таблицу и в дальнейшем используется для вызова данной функции.
Секция ".idata" в сборках .NET в некотором смысле носит вспомогательный характер, так как импортируемые сборкой динамические библиотеки описываются в метаданных. Задача этой секции - обеспечить запуск среды выполнения .NET, поэтому в ней описывается только одна импортируемая из mscoree.dll функция ( _CorExeMain для exe-файлов и _CorDllMain - для dll-файлов). При запуске сборки .NET управление сразу же передается этой функции, которая запускает Common Language Runtime, осуществляющий JIT-компиляцию программы и контролирующий в дальнейшем ее выполнение.
Экспорт функций
Экспорт функций из сборки .NET осуществляется достаточно редко. Дело в том, что наличие метаданных в сборках позволяет нам экспортировать любые элементы сборки, такие как классы, методы, поля, свойства и т.д. Таким образом, обычный механизм экспорта функций становится ненужным.
Необходимость в экспорте функций возникает только тогда, когда сборка .NET должна использоваться обычной программой Windows, код которой не управляется средой выполнения .NET.
Информация об экспортируемых функциях хранится внутри PE-файла в специальной секции ".edata". При этом каждой функции присваивается уникальный номер, и с этим номером связывается RVA тела функции, и, возможно, имя функции. Не всякая экспортируемая функция имеет имя, так как имена служат, главным образом, для удобства программистов.