





|
Добрый день!
Скажите, пожалуйста,планируется ли продолжение курсов по нанотехнологиям? Спасибо, Евгений
|
Инспектор
Вы можете этот курс.
Опубликован: 01.10.2013 | Уровень: для всех | Доступ: платный
Лекция 5:
МКМД-БИТ-потоковые субпроцессоры с (микро)программируемой архитектурой
4.4. Методы и средства компенсации системных временных издержек в МКМД-бит-потоковых субпроцессорных трактах
Неравенство (6.1) курса "Задачи и модели вычислительных наноструктур", задающее условия эффективного использования МКМД-бит-потоковых субпроцессоров  , обеспечиваются на этапе их синтеза (формирования потока (бит)инструкций) за счет высокой структурно-функциональной и (микро)программной гибкости и с учетом системотехнических возможностей используемой аппаратуры на этапах распределения (загрузки в бит-матрицу) и оперативного управления потоками инструкций в процессе вычислений.
, обеспечиваются на этапе их синтеза (формирования потока (бит)инструкций) за счет высокой структурно-функциональной и (микро)программной гибкости и с учетом системотехнических возможностей используемой аппаратуры на этапах распределения (загрузки в бит-матрицу) и оперативного управления потоками инструкций в процессе вычислений.
Это неравенство говорит о том, что главная цель проекта - это поддержание темпа реального времени (РВ) за счет пренебрежимо малых (по сравнению с временем 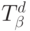 непрерывного (циклического) использования каждого
непрерывного (циклического) использования каждого 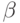 -поток-оператора) системных временных издержек на одно-кратное программирование
-поток-оператора) системных временных издержек на одно-кратное программирование  и вхождение в конвейер
и вхождение в конвейер  алгоритмически ориентированного МКМД-бит-потокового субпроцессора, что справедливо и для нейрокомпьютеров.
алгоритмически ориентированного МКМД-бит-потокового субпроцессора, что справедливо и для нейрокомпьютеров.
Чтобы удовлетворить (6.1) курса "Задачи и модели вычислительных наноструктур" в широком классе задач цифровой обработки сигналов и изображений в качестве основополагающего для МКМД-бит-потоковой организации вычислений принят базовый нейроподобный принцип: "одна (бит)инструкция - один (бит)процессор", который обеспечивается на всех уровнях управления, доступных разработчику или пользователю субпроцессора, и ряд соподчиненных методов (см. раздел 6.5 курса "Задачи и модели вычислительных наноструктур").
Реализация этих принципов и методов:
- Сводит схемо- и системотехническое проектирование проблемно-и алгоритмически ориентированных МКМД-бит-потоковых субпроцессоров к их программному конструированию, которое сходно с кремниевой компиляцией заказных СБИС или УБИС. Главное отличие этих технологий состоит в оперативности исполнения проекта, так как готовая топологическая схема компоновки слов- и поток-инструкций загружается в МКМД-бит-матрицу через каналы ввода-вывода (микро)программ [138-141] и поэтому время такой структурно-функциональной адаптации субпроцессора несопоставимо с циклом производства заказных СБИС.
- Приводит к прямой аппаратурной эмуляции на МКМД-бит-процессорной матрице поток-операторов пользователя, используемых им в качестве макрорасширений языка любого уровня иерархии. При этом настройка МКМД-бит-процессорной матрицы на активный поток-оператор осуществляется методом интерпретации, а не трансляции отвечающей ему слов-программы, представленной в микропрограммном виде, что является необходимым условием высокодинамичного парирования карт частичных и/или полных отказов бит-процессоров за счет толерантного (пере)размещения рабочего тела микропрограммы.
- Делает практически независимыми факторы, ограничивающие темп РВ по потокам данных, и "сложность" решаемой задачи, так как в этом случае теорема Котельникова регламентирует только темп
 поступления (восприятия) данных и (согласно второму принципу) равный ему темп исполнения слов-инструкций. В то же время критический путь
поступления (восприятия) данных и (согласно второму принципу) равный ему темп исполнения слов-инструкций. В то же время критический путь 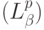 программы, реализующей поток-оператор пользователя, регламентируется допустимым временем задержки в субпроцессоре
программы, реализующей поток-оператор пользователя, регламентируется допустимым временем задержки в субпроцессоре
где
 - разрядность последовательной (конвейерной) арифметики,
- разрядность последовательной (конвейерной) арифметики, 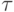 - цикл синхронной работы бит-матрицы, а
- цикл синхронной работы бит-матрицы, а 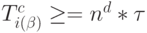 - варьируемое по
- варьируемое по  время задержки в одной слов-инструкции.
время задержки в одной слов-инструкции.
Вытекающие отсюда системотехнические особенности проектирования и работы МКМД-бит-потоковых субпроцессоров сводятся к следующему:
- Достаточно инерционное (микро)программирование используется относительно редко и только для значимых структурно-функциональных и топологических изменений, вызванных либо переходом к другому активному поток-оператору, либо парированием действующей карты отказов.
- Реконфигурация графа связности слов-инструкций и изменение их параметров (разрядность и количество слов в циклически обрабатываемом потоке, база и шаг смещения адреса в ОЗУ, инкрементный или декрементный законы адресации и т. п.) используются для оперативной адаптации ранее активизированного поток-оператора к одной из возможных и вложенных в него вычислительных схем.
- Ассоциативное взаимодействие пространственно фиксированного потока бит- и слов-инструкций с потоками данных поддерживает сверхоперативную адаптацию вычислительной схемы субпроцессора, что свойственно обработке в ассоциативной памяти инструкций, а не данных.
- Синтез топологической схемы каждого поток-оператора проводится априори, не в темпе реального времени и включает нисходящую декомпозицию до слов-инструкций и восходящее программное конструирование слов- и поток-инструкций в фиксированном базисе бит-инструкций и с учетом "ортогональных" ограничений на их пространственно-временное информационное взаимодействие (см. далее рис. 5.1).
- (Микро)программные средства обнаружения отказов (см. далее рис. 6.2) являются проблемно- и алгоритмически ориентированными, реализуются за счет аппаратурного ресурса той же бит-матрицы, активизируются вместе с поток-оператором, входя в его состав как неотъемлемый атрибут, и реагируют на функциональный, а не аппаратный отказ, что увеличивает латентный период его обнаружения, но снижают вероятность ложной тревоги, если отказ произошел в аппаратуре, неиспользуемой активным поток-оператором.
- (Микро)программные средства локализации отказов (см. далее
рис. 6.2) являются системными, инициализируются в режиме разделения времени с поток-операторами пользователя и используют тестируемую бит-матрицу в ОКМД-режиме, что снижает гиперкомбинаторную размерность пространства диагностики
 до количества состояний регистра бит-инструкций одного бит-процессора
до количества состояний регистра бит-инструкций одного бит-процессора  вместо
вместо  , где
, где  - разрядность регистра бит-инструкции, а
- разрядность регистра бит-инструкции, а  - размеры бит-матрицы, причем
- размеры бит-матрицы, причем 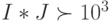 .
. - (Микро)программные средства парирования карт отказов (см. далее рис. 6.2) не требуют кратного резервирования, толерантно деформируют заранее заданную топологическую схему поток-оператора (срезы, кручения, растяжения и т. п. локальные и глобальные аффинные преобразования рабочего тела микропрограмм [22]) и могут быть выполнены по схеме взаимного ремонта, в которой одна бит-матрица используется для толерантных деформаций микропрограммы другой бит-матрицы.
Из приведенных данных видно, что МКМД-бит-процессорная технология не нарушает базовых принципов и методов фон-неймановской организации вычислений с той разницей, что на разных стадиях проектирования и работы неделимой единицей проекта в ней считаются аппарат-но реализованные:
- поток-инструкции - при проектировании и работе в нормальном режиме,
- слов-инструкции - при программном конструировании и парировании отказов,
- бит-инструкции - при локализации отказов.
Поэтому такая технология практически не ограничивает традиционные алгоритмические, системотехнические и конструктивно-технологические методы и средства минимизации системных временных издержек в (6.1) курса "Задачи и модели вычислительных наноструктур".
Алгоритмические методы минимизации системных временных издержек используются на этапе выбора и декомпозиции алгоритмов для всего класса решаемых МКМД-бит-потоковым субпроцессором задач. Они сводятся к максимальному повышению структурно-функциональной одно-
родности поток-операторов пользователя, что позволяет по минимуму использовать перепрограммирование бит-матриц при переходе от одного поток-оператора к другому и по максимуму использовать реконфигурацию связей и ассоциативное взаимодействие потоков (возможно, и специально формируемых) данных с пространственно фиксированным потоком бит- и слов-инструкций.
Системотехнические методы минимизации системных временных издержек используются на этапе синтеза МКМД-бит-потоковых субпроцессоров и ориентированы на максимальное совмещение по времени вспомогательных и исполнительных фаз их работы.
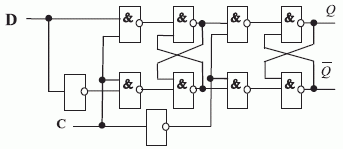
Так, при  МКМД-бит-потоковые субпроцессоры можно выполнить по парафазной схеме (рис. 4.9), в которой фазы загрузки (микро)программы (сигнал
МКМД-бит-потоковые субпроцессоры можно выполнить по парафазной схеме (рис. 4.9), в которой фазы загрузки (микро)программы (сигнал 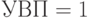 ) и вхождения в конвейер одной бит-матрицы совмещены по времени с фазой циклической обработки потоков данных в другой бит-матрице, то есть никогда не выполняется условие
) и вхождения в конвейер одной бит-матрицы совмещены по времени с фазой циклической обработки потоков данных в другой бит-матрице, то есть никогда не выполняется условие  . В результате абсолютные системные временные издержки всего вычислительного процесса определяются (в идеале) временем
. В результате абсолютные системные временные издержки всего вычислительного процесса определяются (в идеале) временем  программирования и вхождения в конвейер при выполнении субпроцессором первого поток-оператора, а относительные временные издержки стремятся к нулю с ростом числа активизированных поток-операторов.
программирования и вхождения в конвейер при выполнении субпроцессором первого поток-оператора, а относительные временные издержки стремятся к нулю с ростом числа активизированных поток-операторов.
При  МКМД-бит-потоковые субпроцессоры можно выполнить по волновой схеме (рис. 4.10), в которой фаза загрузки (микро) программы в последующую бит-матрицу совмещена по времени с фазой вхождения в конвейер другой бит-матрицы. В этой схеме абсолютные системные временные издержки всего вычислительного процесса (в идеале) равны времени загрузки в бит-матрицу микропрограммы первого поток-оператора пользователя.
МКМД-бит-потоковые субпроцессоры можно выполнить по волновой схеме (рис. 4.10), в которой фаза загрузки (микро) программы в последующую бит-матрицу совмещена по времени с фазой вхождения в конвейер другой бит-матрицы. В этой схеме абсолютные системные временные издержки всего вычислительного процесса (в идеале) равны времени загрузки в бит-матрицу микропрограммы первого поток-оператора пользователя.
Конструктивно-технологические методы минимизации системных временных издержек используют возможности:
- нетрадиционных (микро)программно-адаптируемых FIFO-регистровых локальных и глобальных шлейф-шин, которые обеспечивают реконфигурацию сетей коммутации согласно требованиям карт отказов и графов связности решаемых задач в МКМД-бит-потоковом субпроцессоре на каждом интервале времени;
- традиционных (сверх)параллельных шин инструкций и данных, которые минимизируют циклы обмена информацией МКМД-бит-процессорных матриц с ОЗУ и/или внешними источниками и приемниками.
FIFO -регистровые шлейф-шины реализуются за счет коммутационных возможностей торцевых бит-процессоров, принадлежащих конструктивно разделенным бит-матрицам (см. рис. 4.4), и позволяют создавать гиперцилиндрические, гиперкубические и т. п. вычислительные поверхности, обеспечивающие толерантное переразмещение активных поток-операторов субпроцессорного тракта тривиальными сдвигами рабочих микропрограмм по цилиндрическим поверхностям или узлам гиперкуба с полным сохранением локальной и/или глобальной топологии связей слов- и поток-инструкций во всем субпроцессорном тракте.
С помощью сверхпараллельных шин инструкций, обеспечивающих в пределе прямой параллельный доступ к регистрам инструкций каждого бит-процессора, время программирования в (6.1) курса "Задачи и модели вычислительных наноструктур" можно свести к одному такту работы бит-матрицы, что, как и в нейрокомпьютерах, требует нетрадиционной организации ОЗУ инструкций, при которой "ширина" выборки может достичь размеров  бит, а "глубина" адресации определяется количеством -поток-операторов, закрепленных за конструктивно независимой бит-матрицей.
бит, а "глубина" адресации определяется количеством -поток-операторов, закрепленных за конструктивно независимой бит-матрицей.
В современной вычислительной технике максимально параллельные шины инструкций и/или данных реализуются в оптоэлектронных ВС на основе произвольно коммутируемые оптоэлектронные вентильные матрицы (ПК ОЭВМ [228]), которые отличаются от МКМД-бит-процессорных матриц следующим: 1. Разработчику оптоэлектронного (суб)процессорного тракта доступен
наиболее низкий в схемотехнике вентильный уровень управления.
- Архитектура оптоэлектронных субпроцессоров (рис. 1.14 раздела 1.7 курса "Задачи и модели вычислительных наноструктур") базируется на прямом ассоциативном взаимодействии потоков инструкций и данных, циркулирующих между центральным процессором на ПК ОЭВМ и голографической памятью, выполненной по ПЗУ-технологии [228].
- Управление ходом вычислительного процесса по потоку инструкций является безрегистровым и осуществляется:
- во времени - с точностью до 1-го вентильного такта;
- в пространстве - высокодинамичной коммутацией выходов-входов вентилей на каждом такте, причем сами вентили внутри ОЭВМ не имеют информационных связей.
Согласно [214], оптимальная пространственно-временная система коммутации представляет собой иерархию подсистем:
- с пространственно инвариантными и, как правило, локально компактными связями;
- с пространственно переменными, которые допускают еще и глобальные неоднородные связи.
С учетом этих особенностей в ПК ОЭВМ:
- Из схемы бит-процессора можно исключить (см. рис. 3.1) регистр инструкции, входные и выходные коммутаторы операционного канала и каналов транзита, и тем самым сэкономить не менее 80 % вентилей, составляющих микроэлектронный бит-процессор.
- Глобальную схему управления (рис. 4.11) оптоэлектронным субпроцессором можно сделать адекватной схеме 3-уровневой декомпозиции, где:
- первая голограмма поддерживает поток-процессорный уровень управления, активизируемый при переходе от одного поток-оператора к другому;
- вторая голограмма поддерживает слов-процессорный уровень управления с неизменной топологией связей бит-процессоров, принадлежащих одной и той же слов-инструкции, и с переменной топологией связей между разными слов-инструкциями, модификация которых и обеспечивает переход от одной поток-инструкции к другой;
- третья голограмма поддерживает бит-процессорный уровень управления с неизменной топологией связей составляющих вентилей в соответствующем типе бит-процессоров.
Такая схема управления соответствует технологии структурной реконфигурации оптоэлектронного поток-процессора, которая эффективна в случае, если голографическая память выполнена по технологии ППЗУ. Благодаря 3-уровневой декомпозиции удается управлять ПК ОЭВМ из 107 вентилей, на которой можно разместить в произвольном порядке и в соответствии с задаваемой разработчиком гистограммой различные по функциям бит- и слов-инструкции. При этом каждый уровень управления способен поддерживать библиотеки из 50-100 типов бит-, слов- и поток-инструкций [214]. Это разнообразие проблемно-ориентированного языка программирования покрывают потребности программистов в широком классе задач цифровой обработки сигналов и изображений.
При такой оптоэлектронной реализации из структурно-функциональной схемы бит-процессора рис. 3.2 исключаются:
- регистр бит-инструкции и триггеры D1 и D5 в канале АЛУ, функции которых выполняют ячейки голографической памяти (см. рис. 1.14 курса "Задачи и модели вычислительных наноструктур");
- все входные и выходные коммутаторы, функции которых выполняет разветвленная проекционная система отображения выходов неском-мутированной оптоэлектронной вентильной матрицы на голографи-ческую память и аналогичная проекционная система, выполняющая обратное отображение.
В этом случае D -триггеры задержки нужны только в канале транзита и при необходимости реализации дополнительной задержки в канале АЛУ. В результате схема структурно адаптируемого через голографическую память оптоэлектронного бит-процессора принимает вид рис. 4.12, на которой все виртуальные блоки обозначены пунктирными линиями, так как их функции реализуются системными средствами оптической коммутации и голографической памятью.
Как видно из изложенного, управление оптоэлектронным бит-процессором осуществляется через голографическую память и методом сверхоперативной реконфигурации разветвленных оптических связей между вентилями, которая изменяется на каждом такте работы в соответствии с заданной бит-инструкцией. В частности, при выполнении бит-инструкции 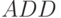 необходимо обеспечить взаимодействие вентилей по схеме
рис. 4.13, где инвертора входных переменных x1 и x2 являются виртуальными и их функции реализует соответствующая ячейка гологра-фической памяти, которая одновременно выдает и саму переменную, и ее инверсию.
необходимо обеспечить взаимодействие вентилей по схеме
рис. 4.13, где инвертора входных переменных x1 и x2 являются виртуальными и их функции реализует соответствующая ячейка гологра-фической памяти, которая одновременно выдает и саму переменную, и ее инверсию.
В оптоэлектронном исполнении (рис. 4.14) на реализацию такой схемы необходимо затратить всего 4 оптоэлектронных вентиля, оптические связи между которыми меняются на каждом такте работы или, что одно и то же, на каждом цикле обращения к голографической памяти (ср. с рис. 1.14 курса "Задачи и модели вычислительных наноструктур"). Структура связей между вентилями регламентируется индивидуальной для каждой бит-инструкции голограммой (см. рис. 4.11).

Рис. 4.14. Оптоэлектронное исполнение логического блока АЛУ бит-процессора при выполнении бит-инструкции ADD
Из схемы рис. 4.14 видно, что произвольно коммутируемая через голографическую память оптоэлектронная вентильная матрица на каждом такте работы используется неравномерно, а каждая бит-инструкция может быть выполнена за 4, возможно, и фемтосекундных тактов работы, то есть, проигрывая микроэлектронной бит-матрице по числу тактов, оптоэлек-тронная бит-матрица может несколько порядков выиграть во времени.
Триггер дополнительной задержки в канале АЛУ оптоэлектронного бит-процессора в основном играет системную функцию, делая стандартным 4-тактный цикл обращения к голографической памяти. Схема микроэлектронного двухполупериодного D -триггера рис. 4.15 в опто-электронном исполнении (рис. 4.16) требует всего двух вентилей, которые последовательно используются в течение четырех тактов работы, формируя соответствующее выходное состояние Q. При этом следует учесть, что в цепях прямой и обратной связи стоят ячейки голографической памяти, обеспечивающие задержку на 1 такт.
Оценку структурно-функциональных возможностей оптоэлектрон-ных бит-процессорных матриц и схем их управления через голографическую память можно получить, взяв за основу операцию конвейерного умножения рис. 4.7 32-битных операндов с 64-битным результатом,
которые представлены в формате фиксированной запятой. В этом случае за счет структурных методов и средств управления на каждый бит-процессор:
- первой строки, где задействованы только каналы транзита, необходимо израсходовать по 2 оптоэлектронных вентиля на каждый D-триггер с четырьмя тактами задержки в каждом;
- второй строки, где используется канал АЛУ с функцией ST1 и канал транзита с задержкой на 1 такт, необходимо израсходовать 8 оптоэ-лектронных вентилей, из которых 4 - на само АЛУ, 2 - на триггер задержки в канале АЛУ для выполнения операции ST1 и 2 - на триггер канала транзита;
- третьей строки, где используется канал АЛУ с функцией AND и канал транзита с задержкой на 2 такт, необходимо израсходовать 6 оптоэлектронных вентилей, из которых 4 - на само АЛУ и 2 - на два триггера канала транзита;
- четвертой строки, где задействованы только каналы АЛУ с функцией ADD, необходимо израсходовать 4 оптоэлектронных вентиля. Таким образом, на 1 терм конвейерного умножителя (1 столбец рис. 4.7) необходимо затратить 20, а на весь 32-битный умножитель - 640 оптоэлектронных вентилей, что сравнимо с затратами на 2 микроэлектронных бит-процессора
Отсюда следует, что оптоэлектронные методы и средства структурной адаптации бит-процессоров позволяют в каждом бит-процессоре микропрограммы использовать те и только те структурно-функциональные возможности бит-процессоров, которые требуются в данной точке бит-матрицы. Это практически полностью исключает свойственную микроэлектронным бит-процессорам структурно-функциональную, а значит, и аппаратную избыточность, что позволяет снизить аппаратные затраты на оптоэлектронные субпроцессоры в десятки и сотни раз.
С позиций реального времени в оптоэлектронном конвейерном умножителе в 4 раза больше расходуется тактов по сравнению с микроэ-
лектронным умножителем:  ,
, 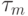 - такт работы оптоэлектронной бит-матрицы, который может быть на несколько порядков меньше, чем у микроэлектронной бит-матрицы.
- такт работы оптоэлектронной бит-матрицы, который может быть на несколько порядков меньше, чем у микроэлектронной бит-матрицы.
Несмотря на все перечисленные преимущества, оптоэлектронные вычислительные технологии не получили пока широкого распространения, так как они в десятки и сотни раз проигрывают пока по потребляемой мощности, что приводит к разогреву оптических сред и к потере требуемых от них физико-технических свойств.
Из приведенных данных можно заключить:
- Голографическая память ПК ОЭВМ:
- изготавливается по технологии ППЗУ, а используется по смешанной технологии:
- адресной - при расщеплении по уровням управления и составляющим операционным модулям,
- ассоциативной - при обработке потоков данных, часть из которых используется для модификации кодов операций однобитных АЛУ на каждом цикле реализации бит-инструкции;
- обеспечивает "безрегистровое" управление по потокам инструкций, что характерно для нейрокомпьютерных технологий, где потоки инструкций и данных неразличимы и, вообще говоря, перемешаны друг с другом в пространстве, а закон перемешивания изменяем во времени, в данном случае - на каждом такте работы вентильной матрицы.
- изготавливается по технологии ППЗУ, а используется по смешанной технологии:
- Оптоэлектронные компиляторы требуют формализованной постановки задачи и поэтапного спуска до вентильного представления. Они фактически поддерживают технологию полузаказных СБИС или УБИС с той разницей, что на голограмму пользовательских слов-инструкций, а значит, и на пропускную способность (сверх) параллельных оптоэлектронных ВС на всем комплексе задач пользователя более сильное влияние оказывают ограничения по количеству вентилей, а не по количеству и структуре связей. Поэтому центральная проблема оптоэлектронной компиляции (деструкции) - это выбор голограммы слов-инструкций, оптимально покрывающей все множество задач пользователя по критерию "аппаратура - время".
- Принципиальное схемо- и системотехническое отличие ВС на ПК ОЭВМ состоит в том, что в них обеспечен предельный в пространстве и во времени уровень декомпозиции решаемой задачи, так как здесь пользователю любого уровня иерархии обеспечен самый низкий, логический уровень доступа, а ячейки памяти синхронизируют работу всей системы с точностью до времени задержки в одном вентиле. Для сравнения, в микроэлектронных бит-матрицах в один такт укладываются переходные процессы всех логических вентилей от выхода D -триггера предыдущего бит-процессора и до входа D -триггера последующего бит-процессора, а переходные процессы в каждом вентиле учитываются только на этапе схемотехнического моделирования СБИС.
Евгений Акимов