


|
Прошел экстерном экзамен по курсу перепордготовки "Информационная безопасность". Хочу получить диплом, но не вижу где оплатить? Ну и соответственно , как с получением бумажного документа? |
Инспектор
Вы можете этот курс.
Опубликован: 07.08.2007 | Уровень: специалист | Доступ: платный | ВУЗ: Московский физико-технический институт
Лекция 6:
Стандарт mpeg-4, -7, -21
Детальное техническое описание визуальной секции MPEG-4
Визуальные объекты могут иметь искусственное или натуральное происхождение.
Приложения видео-стандарта MPEG-4
MPEG-4 видео предлагает технологию, которая перекрывает широкий диапазон существующих и будущих приложений. Низкие скорости передачи и кодирование, устойчивое к ошибкам, позволяет осуществлять надежную связь через радиоканалы с ограниченной полосой, что полезно, например, для мобильной видеотелефонии и космической связи. При высоких скоростях обмена имеются средства, позволяющие передачу и запоминание высококачественного видео на студийном уровне.
Главной областью приложений является интерактивное web-видео. Уже продемонстрированы программы, которые осуществляют "живое" видео MPEG-4. Средства двоичного кодирования и работы с видеообъектами с серой шкалой цветов должны быть интегрированы с текстом и графикой.
MPEG-4 видео уже было использовано для кодирования видеозаписи, выполняемой с ручной видеокамеры. Эта форма приложения становится все популярнее из-за простоты переноса на web-страницу и может также применяться и в случае работы со статичными изображениями и текстурами. Рынок игр является еще одной областью работы приложений MPEG-4 видео, статических текстур, интерактивности.
Натуральные текстуры, изображения и видео
Средства для естественного видео в визуальном стандарте MPEG-4 предоставляют стандартные технологии, позволяющие эффективно запоминать, передавать и манипулировать текстурами, изображениями и видеоданными для мультимедийной среды. Эти средства позволяют декодировать и представлять атомные блоки изображений и видео, называемые "видеообъектами" (VO). Примером VO может быть говорящий человек (без фона), который может быть также создан из других AVO (аудио-визуальный объект) в процессе формирования сцены. Обычные прямоугольные изображения образуют специальный случай таких объектов.
Для того чтобы достичь этой широкой цели, функции различных приложений объединяются. Следовательно, визуальная часть стандарта MPEG-4 предоставляет решения в форме средств и алгоритмов для:
- эффективного сжатия изображений и видео;
- эффективного сжатия текстур для их отображения на 2D и 3D-сетки;
- эффективного сжатия для 2D-сеток;
- эффективного сжатия потоков, характеризующих изменяющуюся со временем геометрию (анимация сеток);
- эффективного произвольного доступа ко всем типам визуальных объектов;
- расширенной манипуляции изображениями и видеопоследовательностями;
- кодирования, зависящего от содержимого изображений и видео;
- масштабируемости текстур, изображений и видео;
- пространственной, временной и качественной масштабируемости;
- обеспечения устойчивости к ошибкам в среде, предрасположенной к сбоям.
Синтетические объекты
Синтетические объекты образуют субнабор большого класса компьютерной графики. Для начала будут рассмотрены следующие синтетические визуальные объекты.
Параметрические описания
- Синтетического лица и тела (анимация тела в версии 2)
- Кодирование статических и динамических текстур
Кодирование текстуры для приложений, зависимых от вида
Масштабируемое кодирование видеообъектов
Существует несколько масштабируемых схем кодирования в визуальном MPEG-4: пространственная масштабируемость, временная масштабируемость и объектно-ориентированная пространственная масштабируемость. Пространственная масштабируемость поддерживает изменяющееся качество текстуры (SNR и пространственное разрешение). Объектно-ориентированная пространственная масштабируемость расширяет обычные типы масштабируемости в направлении объектов произвольной формы, так что ее можно использовать в сочетании с другими объектно-ориентированными возможностями. Таким образом, может быть достигнута очень гибкая масштабируемость. Это делает возможным при воспроизведении динамически улучшать SNR, пространственное разрешение, точность воспроизведения формы и т.д. только для объектов, представляющих интерес, или для определенной области.
Устойчивость в среде, предрасположенной к ошибкам
Разработанная в MPEG новая методика, названная NEWPRED (new prediction — новое предсказание), предоставляет быстрое восстановление после ошибок в приложениях реального времени. Она использует канал от декодера к кодировщику. Кодировщик переключает эталонные кадры, приспосабливаясь к условиям возникновения ошибок в сети. Методика NEWPRED обеспечивает высокую эффективность кодирования. Она была проверена в условиях высоких потоков ошибок:
- короткие всплески ошибок в беспроводных сетях (BER = 10-3, длительность всплеска — 1 мс);
- потери пакетов в Интернете (вероятность потери = 5%).
Улучшенная стабильность временного разрешения с низкой задержкой буферизации
Еще одной новой методикой является DRC (Dynamic Resolution Conversion), которая стабилизирует задержку буферизации при передаче путем минимизации разброса числа кодовых бит VOP на выходе. Предотвращается отбрасывание больших пакетов, а кодировщик может контролировать временное разрешение даже в высокоактивных сценах.
Кодирование текстур и статические изображения
Следующие три новых средства кодирования текстур и статических изображений предлагается в версии V.2.
- Wavelet tiling (деление на зоны) позволяет делить изображение на несколько составных частей, каждая из которых кодируется независимо. Это означает, что большие изображения могут кодироваться/декодироваться в условиях достаточно низких требований к памяти и что произвольный доступ к декодеру существенно улучшен.
- Масштабируемое кодирование формы позволяет кодировать текстуры произвольной формы и статические изображения с привлечением масштабируемости. Используя это средство, декодер может преобразовать изображение произвольной формы с любым желательным разрешением. Это средство позволяет приложению использовать объектно-ориентированную пространственную и качественную масштабируемость одновременно.
- Средство противодействия ошибкам добавляет новые возможности восстановления при ошибках. Используя пакетирование и технику сегментных маркеров, оно значительно улучшает устойчивость к ошибкам приложений, таких как передача изображения через мобильные каналы или Интернет.
Упомянутые выше средства используются в двух новых продвинутых масштабируемых текстурах и продвинутом центральном профайле (advanced core profile).
Кодирование нескольких видов и большого числа вспомогательных компонентов
MPEG-4 видео версии 1 поддерживает один альфа-канал на видеоканальный слой и определяет три типа формы. Все три типа формы, т.е. двоичная форма, постоянная форма и форма с серой шкалой, допускают прозрачность видеообъекта. При таком определении MPEG-4 не может эффективно поддерживать такие функциональности, как многовидовые видеообъекты ( Multiview Video Objects ). В версии 2 введено применение множественных альфа-каналов для передачи вспомогательных компонент.
Базовой идеей является то, что форма с серой шкалой не является единственной для описания прозрачности видеообъекта, но может быть определена в более общем виде. Форма с серой шкалой может, например, представлять:
- форму прозрачности;
- форму несоразмерности (Disparity shape) для многовидовых видеообъектов (горизонтальных и вертикальных);
- форму глубины (Depth shape) (получаемую посредством лазерного дальномера или при анализе различия);
- инфракрасные или другие вторичные текстуры.
Все альфа-каналы могут кодироваться с помощью средств кодирования формы, т.е. средств двоичного кодирования формы и средств кодирования формы с серой шкалой, которые используют DCT с компенсаций перемещения и обычно имеют ту же форму и разрешение, что и текстура видеообъекта.
Общим принципом является ограничение числа пикселей, которые следует кодировать при анализе соответствия между конкретными видами объекта, доступными на стороне кодировщика. Все области объекта, которые видны со стороны более чем одной камеры, кодируются только один раз с максимально возможным разрешением. Соотношения несоразмерности могут быть оценены из исходных видов, чтобы реконструировать все области, которые были исключены из кодирования путем использования проекции с компенсированной несоразмерностью. Один или два вспомогательных компонента могут быть выделены, чтобы кодировать карты несоразмерности, указывающие на соответствие между пикселями различных видов.
Мы назначаем области, которые используются для кодирования данных от каждой конкретной камеры, как области интереса (AOI). Эти AOI могут теперь быть просто определены как видеообъекты MPEG-4 и закодированы с их ассоциированными значениями несоразмерности. Из-за возможного отражения объектов в различных видах, а также из-за отклонений цветов или различия экспозиций для разных камер, границы между областями, которые нужно реконструировать на основе разных исходных видов, могут оказаться видимыми. Для решения этой проблемы необходимо предварительно обработать пиксели вблизи границ AOI так, чтобы осуществить плавный переход путем интерполяции пикселей из различных смежных видов в пределах переходной области.
Реконструкция различных точек зрения на основе компенсированной несоразмерности текстурной поверхности осуществляется на базе текстурных данных в пределах конкретных AOI, с привлечением карты несоразмерностей, которая была получена из вспомогательной компоненты, декодированной из видеопотока MPEG-4. Каждая AOI обрабатывается независимо, а затем проекции изображений от всех AOI собираются для получения окончательного вида видеообъекта с заданной точки зрения. Эта процедура может быть выполнена для системы с двумя камерами с параллельной установкой, но может быть распространена на случай системы с несколькими камерами со сходящимися оптическими осями.
Анимация лица
"Лицевой анимационный объект" может использоваться для представления анимированного лица. Форма, текстура и выражения лица управляются параметрами описания лица FDP (Facial Definition Parameters) и/или параметрами анимации лица FAP (Facial Animation Parameters). Объект лица содержит базовый вид лица с нейтральным выражением. Лицо может также получить немедленно анимационные параметры из потока данных, который осуществит анимацию лица: выражение, речь и т.д. Между тем могут быть посланы параметры описания, которые изменят облик лица от некоторого базового к заданному лицу со своей собственной формой и (опционно) текстурой. Если это желательно, через набор FDP можно загрузить полную модель лица.
Анимация лица в MPEG-4 версии 1 предназначена для высокоэффективного кодирования параметров анимации, которые могут управлять неограниченным числом моделей лица. Сами модели не являются нормативными, хотя существуют средства описания характеристик модели. Для точной артикуляции может использоваться кадровое и временное DCT-кодирование большой коллекции FAP.
Двоичный формат систем для сцены BIFS (Systems Binary Format for Scenes), предоставляет возможности поддержки анимации лица, когда нужны обычные модели и интерпретации FAP.
- Параметры определения лица FDP (Face Definition Parameters) в BIFS (модельные данные являются загружаемыми, чтобы конфигурировать базовую модель лица, запомненную в терминале до декодирования FAP, или инсталлировать специфическую модель лица в начале сессии вместе с информацией о том, как анимировать лицо).
- Таблица анимации лица FAT (Face Animation Table) в рамках FDP (загружаемые таблицы функционального соответствия между приходящими FAP и будущими контрольными точками сетки лица). Это дает кусочно-линейную карту входящих FAP для управления движениями лица. Например: FAP может приказать "open_jaw (500)" (открыть челюсти) и таблица определит, что это означает в терминах перемещения характерных точек.
- Интерполяционная методика для лица FIT (Face Interpolation Technique) в BIFS (загружаемое определение карты входящих FAP в общий набор FAP до их использования в характерных точках, которая вычисляется с использованием полиномиальных функций при получении интерполяционного графа лица). Это может использоваться для установления комплексных перекрестных связей FAP или интерполяции FAP, потерянных в потоке, с привлечением FAP, которые доступны для терминала.
Эти специфицированные типы узлов в BIFS эффективно предоставляют для моделей формирования лица встроенную калибровку модели, которая работает на терминале или загружаемой стандартной модели, включающей форму, текстуру и цвет.
Анимация тела
Body является объектом, который способен генерировать модели виртуального тела и анимации в форме наборов 3D многоугольных сеток, пригодных для отображения (rendering). Для тела определены два набора параметров: набор параметров описания тела BDP (Body Definition Parameter) и набор параметров анимации тела BAP (Body Animation Parameter). Набор BDP определяет параметры преобразования изображения тела по умолчанию в требующийся образ с нужной поверхностью, размерами, и (опционно) текстурой. Параметры анимации тела (BAP) при корректной интерпретации позволят получить разумный результат, выражаемый в терминах позы и анимации для самых разных моделей тела, без необходимости инициализировать или калибровать модель.
Конструкция объекта тело содержит обобщенное виртуальное человеческое тело в позе по умолчанию. Объект способен немедленно принимать BAP из потока данных, который осуществляет анимацию тела. Если получены BDP, они используются для преобразования обобщенного тела в конкретное, заданное значениями параметров. Любой компонент может быть равен нулю. Нулевой компонент при отображении тела заменяется соответствующим значением по умолчанию. Поза по умолчанию соответствует стоящей фигуре. Эта поза определена следующим образом: стопы ориентированы во фронтальном направлении, обе руки размещаются вдоль тела с ладонями, повернутыми внутрь. Эта поза предполагает также, что все BAP имеют значения по умолчанию.
Не делается никаких предположений и не вводится никаких ограничений на движения или сочленения. Другими словами, модель человеческого тела должна поддерживать различные приложения, от реалистических симуляций человеческих движений до сетевых игр, использующих простые человекоподобные модели.
Стандарт анимации тела был разработан MPEG в сотрудничестве с Рабочей группой анимации гуманоидов (Humanoid Animation Working Group) в рамках консорциума VRML.
Анимируемые 2D-сетки
Сетка 2D ( mesh ) является разложением плоской 2D-области на многоугольные кусочки. Вершины полигональных частей этой мозаики называются узловыми точками сетки. MPEG-4 рассматривает только треугольные сетки, где элементы мозаики имеют треугольную форму. Динамические 2D-сетки ссылаются на сетки 2D и информацию перемещения всех узловых точек сетки в пределах временного сегмента интереса. Треугольные сетки использовались в течение долгого времени для эффективного моделирования формы 3-D-объектов и воспроизведения в машинной графике. Моделирование 2D-сеток может рассматриваться как проекция треугольных 3D-сеток на плоскость изображения.
Узловые точки динамической сетки отслеживают особенности изображения во времени с помощью соответствующих векторов перемещения. Исходная сетка может быть регулярной или адаптироваться к характеру изображения и тогда называться сеткой, адаптируемой к изображению. Моделирование 2D-сетки, адаптируемой к изображению, соответствует неоднородному стробированию поля перемещения в некотором числе узловых точек вдоль контура и внутри видеообъекта. Методы выбора и отслеживания этих узловых точек не являются предметом стандартизации.
В 2D-сетке, базирующейся на текстуре, треугольные элементы в текущем кадре деформируются при перемещении узловых точек. Текстура в каждом мозаичном элементе эталонного кадра деформируется с помощью таблиц параметрического соответствия, определенных как функция векторов перемещения узловых точек. Для треугольных сетей обычно используется аффинное преобразование. Его линейная форма предполагает текстурный мэппинг с низкой вычислительной сложностью. Аффинный мэппинг может моделировать преобразование, вращение, изменение масштаба, отражение, вырезание и сохранение прямых линий. Степени свободы, предоставляемые тремя векторами перемещения вершин треугольника, соответствуют шести параметрам аффинного преобразования (affine mapping). Это предполагает, что исходное 2D-поле перемещения может быть компактно представлено движением узловых точек, из которого реконструируется аффинное поле перемещения. В то же время структура сетки ограничивает перемещения смежных, мозаичных элементов изображения. Следовательно, сетки хорошо годятся для представления умеренно деформируемых, но пространственно непрерывных полей перемещения.
Моделирование 2D-сетки привлекательно, так как 2D-сетки могут быть сформированы из одного вида объекта, сохраняя функциональность, обеспечиваемую моделированием с привлечением 3D-сеток. Подводя итог, можно сказать, что представления с объектно-ориентированными 2D-сетками могут моделировать форму (многогранная аппроксимация контура объекта) и перемещение VOP в неоднородной структуре, которая является расширяемой до моделирования 3D-объектов, когда имеются данные для конструирования таких моделей. В частности, представление видеообъектов с помощью 2D-сетки допускает следующие функции:
A. Манипуляция видеообъектами
- Улучшенная реальность. Объединение виртуальных (сгенерированных ЭВМ) изображений с реальными движущимися объектами (видео) для создания улучшенной видеоинформации. Изображения, созданные компьютером, должны оставаться в идеальном согласии с движущимися реальными изображениями (следовательно, необходимо отслеживание).
- Преображение/анимация синтетических объектов. Замещение естественных видеообъектов в видеоклипе другим видеообъектом. Замещающий видеообъект может быть извлечен из другого естественного видеоклипа или может быть получен из объекта статического изображения, используя информацию о перемещении объекта, который должен быть замещен.
- Пространственно-временная интерполяция. Моделирование движения сетки представляет более надежную временную интерполяцию с компенсацией перемещения.
B. Сжатие видеообъекта
- Моделирование 2D-сеток может использоваться для сжатия, если выбирается передача текстурных карт только определенных ключевых кадров, и анимации этих текстурных карт для промежуточных кадров. Это называется самопреображением выбранных ключевых кадров с использованием информации 2D-сеток.
C. Видеоиндексирование, базирующееся на содержимом
- Представление сетки делает возможным анимационные ключевые мгновенные фотографии для подвижного визуального обзора объектов.
- Представление сетки предоставляет точную информацию о траектории объекта, которая может использоваться для получения визуальных объектов со специфическим перемещением.
- Сетка дает представление формы объекта, базирующееся на вершинной схеме, которое более эффективно, чем представление через побитовую карту.
3D-сетки
Возможности кодирования 3D-сеток:
- Кодирование базовых 3D многоугольных сеток делает возможным эффективное кодирование 3D полигональных сеток. Кодовое представление является достаточно общим, чтобы поддерживать как много-, так и односеточный вариант.
- форму прозрачности;Инкрементное представление позволяет декодеру реконструировать несколько поверхностей в сетке, пропорционально числу бит в обрабатываемом потоке данных. Это, кроме того, делает возможным инкрементный рэндеринг.
- Быстрое восстановление при ошибках позволяет декодеру частично восстановить сетку, когда субнабор бит потока данных потерян и/или искажен.
- Масштабируемость LOD (Level Of Detail — уровень детализации) позволяет декодеру реконструировать упрощенную версию исходной сетки, содержащей уменьшенное число вершин из субнабора потока данных. Такие упрощенные презентации полезны, чтобы уменьшить время рэндеринга объектов, которые удалены от наблюдателя (управление LOD), но также делает возможным применение менее мощного средства для отображения объекта с ухудшенным качеством.
Масштабируемость, зависящая от изображения
Масштабируемость, зависящая от вида, делает возможными текстурные карты, которые используются в реалистичных виртуальных средах. Она заключается в учете точки наблюдения в виртуальном 3D-мире, для того чтобы передать только видимую информацию. Только часть информации затем пересылается, в зависимости от геометрии объекта и смещения точки зрения. Эта часть вычисляется как на стороне кодировщика, так и на стороне декодера. Такой подход позволяет значительно уменьшить количество передаваемой информации между удаленной базой данных и пользователем. Эта масштабируемость может работать с кодировщиками, базирующимися на DCT.
Структура средств для представления натурального видео
Алгоритмы кодирования изображения MPEG-4 и видео дают эффективное представление визуальных объектов произвольной формы, а также поддержку функций, базирующихся на содержимом. Они поддерживают большинство функций, уже предлагаемых в MPEG-1 и MPEG-2, включая эффективное сжатие стандартных последовательностей прямоугольных изображений при варьируемых уровнях входных форматов, частотах кадров, глубине пикселей, скоростях передачи и разных уровнях пространственной, временной и качественной масштабируемости.
Базовая качественная классификация по скоростям передачи и функциональности визуального стандарта MPEG-4 для естественных изображений и видео представлена на рис. 6.11.
Ядро VLBV (Very Low Bit-rate Video) предлагает алгоритмы и средства для приложений, работающих при скоростях передачи между 5 и 64 Кбит/с, поддерживающие последовательности изображений с низким пространственным разрешением (обычно ниже разрешения CIF) и с низкими частотами кадров (обычно ниже 15 Гц). К приложениям, поддерживающим функциональность ядра VLBV, относятся:
- кодирование обычных последовательностей прямоугольных изображений с высокой эффективностью кодирования и высокой устойчивостью к ошибкам, малыми задержками и низкой сложностью для мультимедийных приложений реального времени, и
- операции "произвольный доступ", ""быстрая перемотка вперед" и "быстрая перемотка назад" для запоминания VLB мультимедиа ДБ и приложений доступа.
Та же самая функциональность поддерживается при высоких скоростях обмена с высокими параметрами по временному и пространственному разрешению вплоть до ITU-R Rec. 601 и больше — используя идентичные или подобные алгоритмы и средства как в ядре VLBV. Предполагается, что скорости передачи лежат в диапазоне от 64 Кбит/с до 10 Мбит/с, а приложения включают широковещательное мультимедиа или интерактивное получение сигналов с качеством, сравнимым с цифровым телевидением.
Функциональности, базирующиеся на содержимом, поддерживают отдельное кодирование и декодирование содержимого (т.е. физических объектов на сцене, VO). Эта особенность MPEG-4 предоставляет наиболее элементарный механизм интерактивности.
Для гибридного кодирования естественных и искусственных визуальных данных (например, для виртуального присутствия или виртуального окружения) функциональность кодирования, зависящая от содержимого, допускает смешение нескольких VO от различных источников с синтетическими объектами, такими как виртуальный фон.
Расширенные алгоритмы и средства MPEG-4 для функциональности, зависящей от содержимого, могут рассматриваться как супернабор ядра VLBV и средств для работы при высоких потоках данных.
Поддержка обычной функциональности и зависящей от содержимого
MPEG-4 видео поддерживает обычные прямоугольные изображения и видео, а также изображения и видео произвольной формы.
Кодирование обычных изображений и видео сходно с обычным кодированием в MPEG-1/2. Оно включает в себя предсказание/компенсацию перемещений, за которым следует кодирование текстуры. Для функциональности, зависящей от содержимого, где входная последовательность изображений может иметь произвольную форму и положение, данный подход расширен с помощью кодирования формы и прозрачности. Форма может быть представлена двоичной маской или 8-битовой компонентой, которая позволяет описать прозрачность, если один VO объединен с другими объектами.
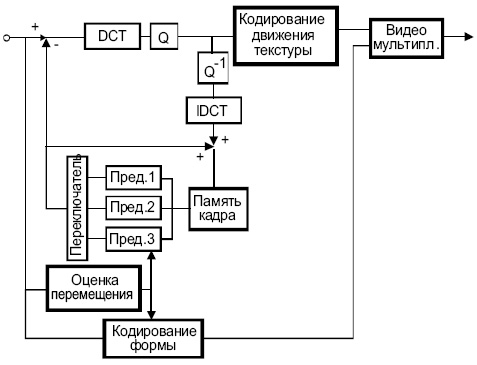
Видеоизображение MPEG-4 и схема кодирования
Рис. 6.12 описывает базовый подход алгоритмов MPEG-4 видео к кодированию входной последовательности изображений прямоугольной и произвольной формы.
Базовая структура кодирования включает в себя кодирование формы (для VO произвольной формы), компенсацию перемещения и кодирование текстуры с привлечением DCT (используя стандарт 8x8 DCT или DCT, адаптирующийся к форме).
Важным преимуществом кодирования, базирующегося на содержимом, является то, что эффективность сжатия может для некоторых видеопоследовательностей быть существенно улучшена путем применения объектно-ориентированных средств предсказания перемещения для каждого из объектов на сцене. Для улучшения эффективности кодирования и гибкости презентации объектов может использоваться несколько методик предсказания перемещения.
- Стандартная оценка и компенсация перемещения, базирующаяся на блоках 8x8 или 16x16 пикселей.
- Глобальная компенсация перемещения, базирующаяся на передаче статического "образа". Статическим образом может быть большое статическое изображение, описывающее панораму фона. Для каждого изображения в последовательности кодируются для реконструкции объекта только 8 глобальных параметров перемещения, описывающих движение камеры. Эти параметры представляют соответствующее аффинное преобразование образа, переданного в первом кадре.
Стандарт MPEG-4 версии 2 улучшает оценку перемещения и компенсации для объектов и текстур прямоугольной и произвольной формы. Введены две методики для оценки и компенсации перемещения.
- Глобальная компенсация перемещения GMC (Global Motion Compensation). Кодирование глобального перемещения для объекта, использующего малое число параметров. GMC основано на глобальной оценке перемещения, деформации изображения, кодировании траектории перемещения и кодировании текстуры для ошибок предсказания.
- Четверть-пиксельная компенсация перемещения улучшает точность схемы компенсации за счет лишь небольшой синтаксической и вычислительной избыточности. Точное описание перемещения приводит к малым ошибкам предсказания и, следовательно, лучшему визуальному качеству.
В области текстурного кодирования DCT (SA-DCT — адаптивный к форме) улучшает эффективность кодирования объектов произвольной формы. Алгоритм SA-DCT основан на предварительно определенных ортонормальных наборах одномерных базисных функций DCT.
Субъективные оценочные тесты показывают, что комбинация этих методик может дать экономию в необходимой полосе канала до 50% по сравнению с версией 1, в зависимости от типа содержимого и потока данных.
Кодирование текстур в статических изображениях
Эффективное кодирование визуальных текстур и статических изображений (подлежащих, например, выкладке на анимационные сетки) поддерживается режимом визуальных текстур MPEG-4. Этот режим основан на алгоритме вейвлетов с нулевым деревом, который предоставляет очень высокую эффективность кодирования в широком диапазоне скоростей передачи. Вместе с высокой эффективностью сжатия он также предлагает пространственную и качественную масштабируемость (вплоть до 11 уровней пространственной масштабируемости и непрерывной масштабируемости качества), а также кодирование объектов произвольной формы. Кодированный поток данных предназначен также для загрузки в терминал иерархии разрешения изображения. Эта технология обеспечивает масштабируемость разрешения в широком диапазоне условий наблюдения, более типичном для интерактивных приложений при отображении 2D- и 3D-виртуальных миров.
Масштабируемое кодирование видеообъектов
MPEG-4 поддерживает кодирование изображений и видеообъектов с пространственной и временной масштабируемостью, для обычных прямоугольных и произвольных форм. Под масштабируемостью подразумевается возможность декодирования лишь части потока данных и реконструировать изображение или их последовательность с:
- уменьшенной сложностью декодера и, следовательно, ухудшенным качеством;
- уменьшенным пространственным разрешением;
- уменьшенным временным разрешением;
- равным временным и пространственным разрешением, но с ухудшенным качеством.
Эта функциональность желательна для прогрессивного кодирования изображений и видео, передаваемых через неоднородные сети, а также для приложений, где получатель неспособен обеспечить полное разрешение или полное качество изображения или видео. Это может, например, случиться, когда мощность обработки или разрешение отображения ограничены.
Для декодирования статических изображений стандарт MPEG-4 предоставит 11 уровней гранулярности, а также масштабируемость качества до уровня одного бита. Для видеопоследовательностей вначале будет поддерживаться 3 уровня гранулярности, но ведутся работы для достижения 9 уровней.
Устойчивость в среде, предрасположенной к ошибкам
MPEG-4 обеспечивает устойчивость к ошибкам, чтобы позволить доступ к изображениям и видеоданным через широкий круг устройств памяти и передающих сред. В частности, на фоне быстрого роста мобильных телекоммуникаций, необычайно важно получить доступ к аудио- и видеоинформации через радиосети. Это подразумевает необходимость успешной работы алгоритмов сжатия аудио- и видеоданных в среде предрасположенной к ошибкам при низких скоростях передачи (т.е. ниже 64 Кбит/с).
Средства противостояния ошибкам, разработанные для MPEG-4, могут быть разделены на три основные группы: ресинхронизация, восстановление данных и подавление влияния ошибок. Следует заметить, что эти категории не являются уникальными для MPEG-4, они широко используются разработчиками средств противодействия ошибкам для видео.
Средства ресинхронизации пытаются восстановить синхронизацию между декодером и потоком данных, нарушенную в результате ошибки. Данные между точкой потери синхронизации и моментом ее восстановления выбрасываются.
Метод ресинхронизации, принятый MPEG-4, подобен используемому в структурах групп блоков GOB (Group of Blocks) стандартов ITU-T H.261 и H.263. В этих стандартах GOB определена как группа из одного или более рядов макроблоков (MB). В начале нового GOB-потока помещается информация, называемая заголовком GOB. Этот информационный заголовок содержит стартовый код GOB, который отличается от начального кода кадра и позволяет декодеру локализовать данный GOB. Далее заголовок GOB содержит информацию, которая позволяет рестартовать процесс декодирования (т.е. ресинхронизовать декодер и поток данных, а также сбросить всю информацию предсказаний).
Подход GOB базируется на пространственной ресинхронизации. То есть, раз в процессе кодирования достигнута позиция конкретного макроблока, в поток добавляется маркер ресинхронизации. Потенциальная проблема с этим подходом заключается в том, что из-за вариации скорости процесса кодирования положение этих маркеров в потоке четко не определено. Следовательно, определенные части сцены, такие как быстро движущиеся области, будут более уязвимы для ошибок, которые достаточно трудно исключить.
Подход видеопакетов, принятый MPEG-4, базируется на периодически посылаемых в потоке данных маркерах ресинхронизации. Другими словами, длина видеопакетов не связана с числом макроблоков, а определяется числом бит, содержащихся в пакете. Если число бит в текущем видеопакете превышает заданный порог, тогда в начале следующего макроблока формируется новый видеопакет.
Маркер ресинхронизации используется, чтобы выделить новый видеопакет. Этот маркер отличим от всех возможных VLC-кодовых слов, а также от стартового кода VOP. Информация заголовка размещается в начале видеопакета. Информация заголовка необходима для повторного запуска процесса декодирования и включает в себя: номер первого макроблока, содержащегося в этом пакете, и параметр квантования, необходимый для декодирования данного макроблока. Номер макроблока осуществляет необходимую пространственную ресинхронизацию, в то время как параметр квантования позволяет заново синхронизовать процесс дифференциального декодирования.
В заголовке видеопакета содержится также код расширения заголовка (HEC). HEC представляет собой один бит, который, если равен 1, указывает на наличие дополнительной информации ресинхронизации. Сюда входит модульная временная шкала, временное приращение VOP, тип предсказания VOP и F-код. Эта дополнительная информация предоставляется в случае, если заголовок VOP поврежден.
Следует заметить, что, когда в рамках MPEG-4 используется средство восстановления при ошибках, некоторые средства эффективного сжатия модифицируются. Например, вся кодированная информация предсказаний заключается в одном видеопакете так, чтобы предотвратить перенос ошибок.
В связи с концепцией ресинхронизации видеопакетов, в MPEG-4 добавлен еще один метод, называемый синхронизацией с фиксированным интервалом. Этот метод требует, чтобы стартовые коды VOP и маркеры ресинхронизации (т.е. начало видеопакета) появлялись только в фиксированных позициях потока данных. Это помогает избежать проблем, связанных эмуляциями стартовых кодов. То есть, когда в потоке данных встречаются ошибки, имеется возможность того, что они эмулируют стартовый код VOP. В этом случае при использовании декодера с синхронизацией с фиксированным интервалом стартовый код VOP отыскивается только в начале каждого фиксированного интервала.
После того как синхронизация восстановлена, средства восстановления пытаются спасти данные, которые в общем случае могут быть потеряны. Эти средства являются не просто программами коррекции ошибок, а техникой кодирования данных, которая устойчива к ошибкам. Например, одно конкретное средство, которое было одобрено видеогруппой (Video Group), является обратимыми кодами переменной длины RVLC (Reversible Variable Length Codes). В этом подходе кодовые слова переменной длины сконструированы симметрично, так что они могут читаться и в прямом, и в обратном направлении.
Пример, иллюстрирующий использование RVLC, представлен на рис. 6.13. Вообще, в ситуации, когда блок ошибок повредил часть данных, все данные между двумя точками синхронизации теряются. Однако, как показано на рис. 6.13, RVLC позволяет восстановить часть этих данных. Следует заметить, что параметры QP и HEC, показанные на рисунке, представляют собой поля, зарезервированные в заголовке видеопакета для параметра квантования и кода расширения заголовка соответственно.
Сокрытие ошибок (имеется в виду процедура, когда последствия ошибок не видны) является исключительно важным компонентом любого устойчивого к ошибкам видеокодека. Эффективность стратегии сокрытия ошибок в высшей степени зависит от работы схемы ресинхронизации. По существу, если метод ресинхронизации может эффективно локализовать ошибку, то проблема сокрытия ошибок становится легко решаемой. Для приложений с низкой скоростью передачи и малой задержкой текущая схема ресинхронизации позволяет получить достаточно приемлемые результаты при простой стратегии сокрытия, такой как копирование блоков из предыдущего кадра.
Для дальнейшего улучшения техники сокрытия ошибок Видеогруппа разработала дополнительный режим противодействия ошибкам, который дополнительно улучшает возможности декодера по локализации ошибок.
Этот подход использует разделение данных, сопряженных с движением и текстурой. Такая техника требует, чтобы был введен второй маркер ресинхронизации между данными движения и текстуры. Если информация текстуры потеряна, тогда для минимизации влияния ошибок используется информация перемещения. То есть из-за ошибок текстурные данные отбрасываются, в то время как данные о движении служат для компенсации перемещения ранее декодированной VOP.
Евгений Виноградов
Илья Сидоркин
|
Добрый день! Подскажите пожалуйста как и когда получить диплом, после сдичи и оплаты????? |