| тест |
Преподаватель
Вы можете этот курс.
Опубликован: 09.11.2006 | Уровень: для всех | Доступ: свободно
Лекция 8:
Данные, их типы, структуры и обработка
Аннотация: Рассматриваются основные понятия о данных к алгоритмам, их базовые типы и структуры, вопросы их использования в алгоритмизации задач.
Ключевые слова: данные, слово, математика, информатика, пробел, значение, метод решения, система линейных алгебраических уравнений, метод Гаусса, область определения, простые типы данных, структурированные типы данных, константы, подразделения, Паскаль, операции, равенство, деление, выражение, char, string, алгоритм, структура данных, массив, вектор, ряд, таблица, служебное слово, размерность, матрица, Произведение, программа, точность, разность
Любая актуализация информации опирается на какие-то данные, любые данные могут быть каким-то образом актуализированы.
Данные – это некоторые сообщения, слова в некотором заданном алфавите.
Пример. Число 123 – данное, представляющее собой слово в алфавите из десяти натуральных цифр; число 12,34 – данное, представляющее собой слово в алфавите из десяти натуральных цифр и десятичной запятой; текст "математика и информатика – нужные дисциплины", – данное в алфавите из символов русского языка и знаков препинания, включая пробел.
Текущее (то есть рассматриваемое в данный момент времени) состояние данных называют текущим значением данных или просто значением.
До разработки алгоритма (программы) необходимо выбрать оптимальную для реализации задачи структуру данных. Неудачный выбор данных и их описания может не только усложнить решаемую задачу и сделать ее плохо понимаемой, но и привести к неверным результатам. На структуру данных влияет и выбранный метод решения.
Пример. При решении системы линейных алгебраических уравнений можно воспользоваться методом Крамера (с помощью определителей) или методом Гаусса (с помощью последовательных исключений неизвестных). Метод Крамера потребует при реализации примерно в 3 раза больше операций, чем метод Гаусса, и поэтому им никогда не пользуются при расчетах на ЭВМ.
Тип данных характеризует область определения значений данных.
Задаются типы данных простым перечислением значений типа, например как в простых типах данных, либо объединением (структурированием) ранее определенных каких-то типов – структурированные типы данных.
Пример. Зададим простые типы данных "специальность", "студент", "вуз" следующим перечислением:
специальность = (филолог, историк, математик, медик);
студент = (Петров, Николаев, Семенов, Иванова, Петрова);
вуз = (МГУ, РГУ, КБГУ).
Значением типа "студент" может быть Петров.
Пример. Опишем структурированный тип данных "специальность_студента":
специальность_студента=(специальность, студент).
Значением типа "специальность_студента" может быть пара ( историк, Семенов ).
Для обозначения текущих значений данных используются константы – числовые, текстовые, логические.
Часто (в зависимости от задачи) рассматривают данные, которые имеют не только "линейную" (как приведенные выше), но и иерархическую структуру.
Пример. Структуру "вуз" можно задать иерархической структурой, состоящей, например, из следующих уровней: "Ректорат", "Деканаты и подразделения", "Кафедры", "Отделы", "Преподаватели и сотрудники".
В алгоритмических языках есть стандартные типы, например, целые, вещественные, символьные, текстовые и логические типы. Они в этих языках не уточняются (не определяются, описываются явно) и имеют соответствующие описания с помощью служебных слов.
Пример. В школьном алгоритмическом языке (ШАЯ), например, целые, вещественные, символьные, текстовые (литерные, стринговые) и логические типы данных описываются ключевыми словами цел, вещ, сим, лит, лог. В языке Паскаль – аналогичными ключевыми словами integer, real, char, string, boolean.
Каждый тип данных допускает использование определенных операций со значениями типа ("с типом").
Пример. Для целого типа данных назовем операции ":=", "+", "–", "*", "=" (сравнение на равенство), " 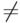 ", "<", ">", "
", "<", ">", " 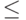 ", "
", "  ".. Для вещественного типа данных еще и операция "/" (деление). Для символьного типа данных – только ":=", "=", " ", "<", ">", " ", " ". Например, сравнение "а"<"b" означает, что символ "а" предшествует символу "b" то есть код буквы "a" меньше кода буквы "b" (коды символов приводятся, например, в таблице ASCII – Аmerican Standard Code for Information Interchange, американский стандарт кодирования для обмена данными ). Для текстового (литерного) типа данных можно использовать еще и операцию конкатенации (присоединения справа) текстов "+". Например, "аб"+"ба" даст новый текст "абба". Для данных логического типа определены логические операции и отношения сравнения. Например, на Паскале для логических переменных a, b, c можно записать корректное выражение: a and b or (c not a).
".. Для вещественного типа данных еще и операция "/" (деление). Для символьного типа данных – только ":=", "=", " ", "<", ">", " ", " ". Например, сравнение "а"<"b" означает, что символ "а" предшествует символу "b" то есть код буквы "a" меньше кода буквы "b" (коды символов приводятся, например, в таблице ASCII – Аmerican Standard Code for Information Interchange, американский стандарт кодирования для обмена данными ). Для текстового (литерного) типа данных можно использовать еще и операцию конкатенации (присоединения справа) текстов "+". Например, "аб"+"ба" даст новый текст "абба". Для данных логического типа определены логические операции и отношения сравнения. Например, на Паскале для логических переменных a, b, c можно записать корректное выражение: a and b or (c not a).
Для описания переменных, значениями которых могут быть лишь символы, тексты, используются соответствующие ключевые слова: на ШАЯ – сим, лит, на Паскале – char, string.
Текстовые (символьные) константы обычно заключают в апострофы.
Пример. Составим алгоритм подсчета числа несовпадающих символов (на одинаковых позициях текстов) в двух заданных текстах a и b. Метод решения: "вырезаем" и сравниваем символы на одинаковых позициях в текстах на совпадение.
Program EquSimb;
Uses Crt;
Var i, k, j: integer;
a, b: string;
Begin
ClrScr;
WriteLn('Введите строку a = '); { приглашение к вводу входного параметра }
ReadLn(a); { ввод первого входного параметра }
WriteLn('Введите строку b='); { приглашение к вводу второго параметра }
ReadLn(b); { ввод второго входного параметра }
k:=abs(length(a)–length(b)); { вычисление разницы длин текстов }
if (length(a)<length(b)) { если текст b длиннее текста a,}
then j:=length(a) { то проверять нужно до длины a, }
else j:=length(b); { иначе – до длины b }
for i:=1 to j do { цикл проверки на совпадение символов }
if (a[i]<>b[i]) { если символы тестов на одинаковых позициях не равны, }
then k:=k+1; { то увеличиваем счетчик количества таких символов }
WriteLn('k = ',k); { вывод результата }
End.