| Стоимость "обучения" |
Преподаватель
Вы можете этот курс.
Опубликован: 20.04.2011 | Уровень: для всех | Доступ: свободно
Лекция 5:
Распределение моментов поступления вызовов
Крутые распределения
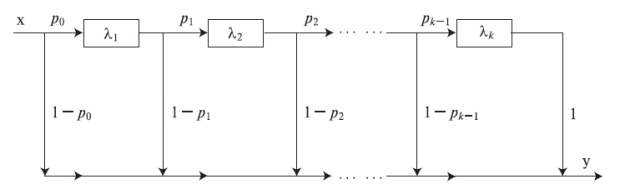
Крутые распределения также называют гиперэкспоненциальными распределениями или обобщенными распределениями Эрланга с коэффициентом формы в интервале 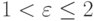 . Эта обобщенная функция распределения получена свертыванием k экспоненциальных распределений (рис.4.2). Здесь мы рассматриваем только случай, где все k экспоненциальных распределений идентичны. Тогда мы получаем следующую плотность функция, которая называется k распределением Эрланга (распределение Эрланга k -го порядка):
. Эта обобщенная функция распределения получена свертыванием k экспоненциальных распределений (рис.4.2). Здесь мы рассматриваем только случай, где все k экспоненциальных распределений идентичны. Тогда мы получаем следующую плотность функция, которая называется k распределением Эрланга (распределение Эрланга k -го порядка):
 |
( 4.8) |
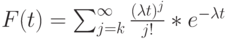 |
( 4.9) |
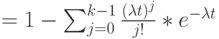 |
( 4.10) |
Следующие моменты могут быть найдены с использованием (3.31) и (3.32):
 |
( 4.11) |
 |
( 4.12) |
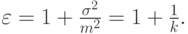 |
( 4.13) |
i -тый нецентральный момент:
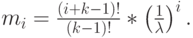 |
( 4.14) |
Функция плотности получена в секции 6.2.2. Средний остаток времени "жизни" 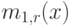 для
для  будет меньше, чем средняя величина:
будет меньше, чем средняя величина:
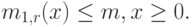

Рис. 4.3. k распределения Эрланга со средней величиной. Случай k = 1 соответствует экспоненциальному распределению (функции плотности)
С этим распределением мы имеем два параметра  , доступные для наблюдений. Средняя величина часто сохраняется фиксированной. Чтобы изучить влияние параметра k в функции распределения, мы нормализуем все k распределения Эрланга к одной и той же самой средней величине как 1, распределение Эрланга, то есть экспоненциальное распределение заменим средним значением
, доступные для наблюдений. Средняя величина часто сохраняется фиксированной. Чтобы изучить влияние параметра k в функции распределения, мы нормализуем все k распределения Эрланга к одной и той же самой средней величине как 1, распределение Эрланга, то есть экспоненциальное распределение заменим средним значением 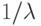 , a t -на k t или
, a t -на k t или 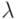 на
на  :
:
 |
( 4.15) |
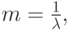 |
( 4.16) |
 |
( 4.17) |
 |
( 4.18) |
Заметим, что коэффициент формы независим от времени. Функция (4.15) плотности проиллюстрирована на рис.4.3 для различных значений k с  . Возьмем случай, когда k = 1 соответствует экспоненциальному распределению. Если
. Возьмем случай, когда k = 1 соответствует экспоненциальному распределению. Если 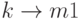 , мы получаем постоянный временной интервал (
, мы получаем постоянный временной интервал ( 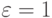 ). Решая f(t) = 0, находим максимальное значение:
). Решая f(t) = 0, находим максимальное значение:
 |
( 4.19) |
Так называемые крутые распределения носят такое имя, потому что увеличение функций распределения от 0 до 1 идет быстрее, чем в экспоненциальном распределении. В теории телетрафика мы иногда используем название - распределение Эрланга для усеченного Пуассоновского распределения (секция 7.3).
Плоские распределения
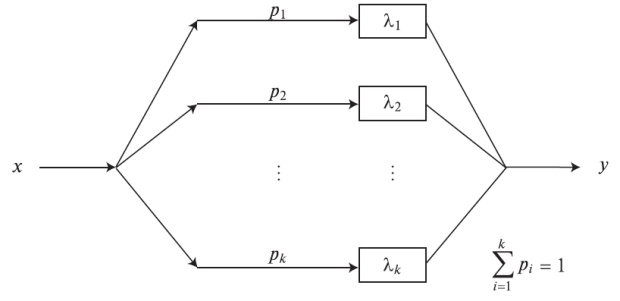
Общая функция распределения находится в этом случае с помощью взвешенной суммы экспоненциальных распределений (составное распределение) с коэффициентом формы  :
:
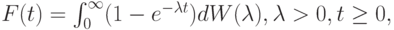 |
( 4.20) |
Функция веса может быть дискретна или непрерывна (интеграл Стилтьеса). Этот класс распределения соответствует параллельной комбинации экспоненциальных распределений (рис.4.4). Функция плотности называется полностью монотонной с чередующимися знаками (Пальма, 1957 [82]:
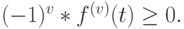 |
( 4.21) |
Среднее остаточное время "жизни" 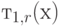 для всего
для всего  является большим, чем средняя величина:
является большим, чем средняя величина:
 |
( 4.22) |
Комбинируя k экспоненциальных параллельных распределений и выбирая i - число ветви i с вероятностью 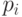 , мы получаем гиперэкспоненциальное распределение, которое является плоским распределением ( )
, мы получаем гиперэкспоненциальное распределение, которое является плоским распределением ( )
Гиперэкспоненциальное распределение
В этом случае  - дискретно. Предположим, что нам даны следующие значения:
- дискретно. Предположим, что нам даны следующие значения:

и что имеет положительные и увеличивающие значения:
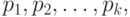
где
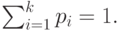 |
( 4.23) |
Для всех других значений является постоянным. В этом случае (4.20) становится:
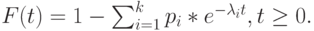 |
( 4.24) |
Средние величины и коэффициент формы могут быть найдены из (3.36)и(3.37)(  ):
):
 |
( 4.25) |
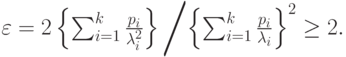 |
( 4.26) |
Если k = 1 или все 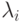 равны, мы получаем экспоненциальное распределение.
равны, мы получаем экспоненциальное распределение.
Распределения этого класса называются гиперэкспоненциальными распределениями, и могут быть получены комбинацией k параллельных экспоненциальных распределений, где вероятность выбора i -того распределения - . Распределение называется плоским, потому что увеличения его функции распределения от 0 до 1 идет медленнее, чем при экспоненциальном распределении.
Практически, трудно оценить больше, чем один или два параметра. Самый важный случай - для 
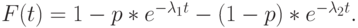 |
( 4.27) |
Статистические проблемы возникают, даже когда мы имеем дело с тремя параметрами. Так, для практических приложений, мы обычно выбираем 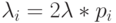 . и, таким образом, уменьшаем число параметров до двух.
. и, таким образом, уменьшаем число параметров до двух.
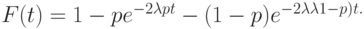 |
( 4.28) |
Средняя величина и коэффициент формы получаются равными:
 |
( 4.29) |
При таком выборе параметров две ветви имеют тот же самый вклад в среднюю величину. Pис.4.5 иллюстрирует пример.
Распределения Кокса
Комбинируя крутые и плоские распределения, мы получаем общий класс распределений (распределения фазового типа), которые может быть описаны с помощью экспоненциальной фазы в последовательном и параллельном случае (например,  матрицу). Чтобы проанализировать модель с таким видом распределений, мы можем применить теорию Марковских процессов, для которых имеются мощные инструментальные средства, такие, как метод диаграмм состояний (фазовый метод). В общем случае мы можем учесть обратную связь между состояниями (фазами).
матрицу). Чтобы проанализировать модель с таким видом распределений, мы можем применить теорию Марковских процессов, для которых имеются мощные инструментальные средства, такие, как метод диаграмм состояний (фазовый метод). В общем случае мы можем учесть обратную связь между состояниями (фазами).
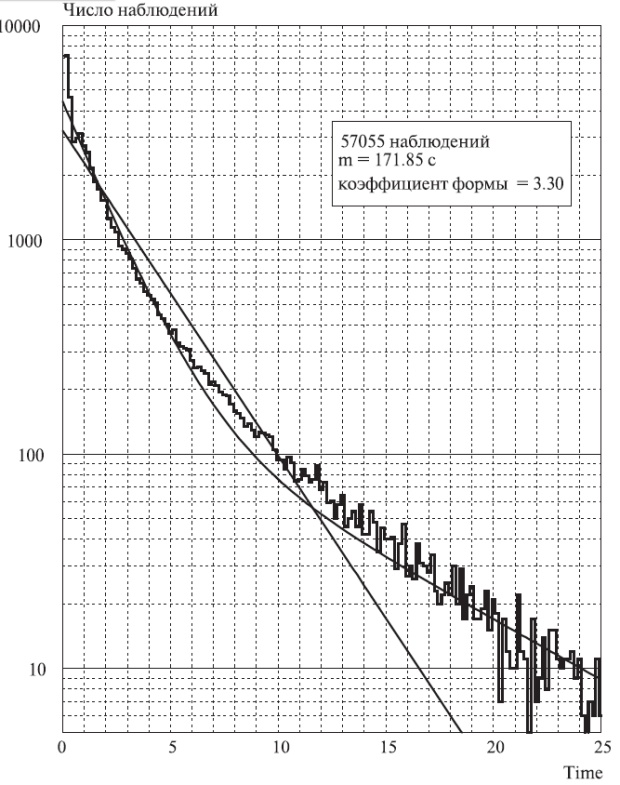
Рис. 4.5. Функция плотности (частотная) для времен пребывания в системе наблюдаемых линий на местной станции в течение часа наибольшей нагрузки.
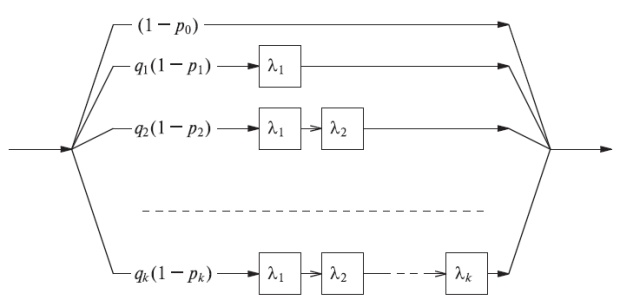
Рис. 4.6. Распределение Кокса - обобщенное распределение Эрланга, имеющее параллельные и последовательные экспоненциальные распределения.
Диаграмма состояния эквивалентна рис.4.7.
Рассмотрим распределение Кокса, которое показано на рис.4.6 (Кокс, 1955 [17]). Оно также иногда называется распределением эрланговского разветвления (иначе, распределением Эрланга с ветвями).
Средняя величина и дисперсия этого распределения Кокса (рис.4.7) получаются из формулы в секции 3.2 для последовательных и параллельных случайных переменных, как это показано на рис.4.6:
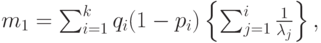 |
( 4.30) |
где
 |
( 4.31) |
Выражение  - вероятность перехода процесса, когда он находится в i -том состоянии. Средняя величина может быть выражена простой формулой:
- вероятность перехода процесса, когда он находится в i -том состоянии. Средняя величина может быть выражена простой формулой:
 |
( 4.32) |
где  - средняя величина в i -том состоянии. Второй момент получается
- средняя величина в i -том состоянии. Второй момент получается
 |
( 4.33) |
где 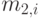 получен из (3.8):
получен из (3.8): 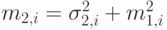 .; это можно записать как:
.; это можно записать как:
 |
( 4.34) |
После чего получаем дисперсию (3.8):
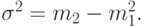
Сложение двух распределений Кокса для случайных переменных дает другое распределение Кокса для случайной переменной, то есть этот класс является замкнутым по отношению к сложению.
Функция распределения Кокса может быть записана как сумма экспоненциальных функций:
 |
( 4.35) |
где
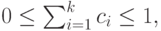
и
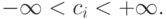
Мультиноминальное распределение
Для более поздних приложений важны следующие свойства. Если мы полагаем, что точка выбрана наугад в пределах временного интервала, подчиняющегося распределению Кокса, то вероятность, что эта точка - в пределах фазы i, равна:
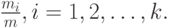 |
( 4.36) |
Если мы повторяем этот эксперимент  раз (независимо), то вероятность, что фаза
раз (независимо), то вероятность, что фаза  наступала
наступала  раз, определяется с помощью мулътиноми-нальногораспределения (оно же - полиномиальное распределение):
раз, определяется с помощью мулътиноми-нальногораспределения (оно же - полиномиальное распределение):
 |
( 4.37) |
где

и
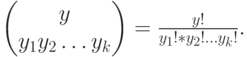 |
( 4.38) |
Элементы в (4.38) называются мультиноминальными коэффициентами. Благодаря свойству экспоненциальных распределений - отсутствию памяти, - мы имеем полную информацию об остаточном времени "жизни", если знаем номер текущей фазы.