

|
Подскажите, пожалуйста, планируете ли вы возобновление программ высшего образования? Если да, есть ли какие-то примерные сроки? Спасибо! |
Опубликован: 20.12.2010 | Уровень: специалист | Доступ: свободно
Лекция 17:
SQL в хранилищах данных: аналитическая обработка данных
Аннотация: В настоящей лекции рассматривается расширение диалектов SQL промышленных СУБД для аналитической обработки данных в хранилищах данных. Изучаются статистические функции, ранжирующие функции, оконные функции в диалекте Transact-SQL СУБД MS SQL Server 2008. Разбираются примеры использования, в том числе для формирования отчетов и построения гистограмм.
Ключевые слова: аналитические функции, статистические функции, предложение OVER, оконные функции, SQL, СУБД, server, поддержка, вычисление, ранжирование, функции ранжирования, функции для генерирования отчетов, секционирование таблиц, значение, агрегатные функции, таблица, физическая структура, population, variance, квота, quota, функция, запрос, запись, целый, ключ, identity, ID, кластеризованные индексы, индекс, выражение, остаток, ISO, ORDER BY, доступ, секционирование, checksumming, collate, киоски данных, номер последовательности, aggregate function, NULL, множества, Top, синтаксис, job, Гистограмма, customer, Oracle, функция регрессии, равенство, 'slope', пересечение, ранг, CASE
Цель лекции
Изучив материал настоящей лекции, вы будете знать:
- что такое аналитические функции в SQL;
- что такое статистические функции в Transact-SQL;
- что такое ранжирующие функции в Transact-SQL;
- что такое функции генерации отчетов в Transact-SQL;
и научитесь:
- использовать предложение OVER ;
- использовать статистические функции ;
- использовать оконные функции ;
- использовать ранжирующие функции;
- применять предложение CASE для построения диаграмм.
SQL для анализа данных
В настоящей лекции мы сконцентрируем внимание на тех возможностях, которые предоставляет SQL по аналитической обработке данных в ХД. В приводимых примерах будем придерживаться диалекта Transact-SQL СУБД семейства MS SQL Server.
Отметим, что в целом SQL не имеет хорошей поддержки для решения аналитических задач. Однако встроенная поддержка аналитических функций в Transact-SQL и его ориентированность на работу с множествами делают его хорошим инструментом для выполнения таких вычислений над данными, хранящимися в ХД. Аналитические функции и ориентированность на работу с множествами дают Transact-SQL определенные преимущества перед другими языками манипулирования данными.
Основные вычисления в системах бизнес-аналитики — вычисление скользящего среднего, ранжирование выборки, и т. д. — требуют большого объема программирования в стандартном SQL. Функции такого типа называются аналитическими функциями.
Аналитические функции подразделяются на следующие категории:
- статистические функции ;
- функции ранжирования ;
- оконные функции ;
- функции для генерирования отчетов.
В табл. 23.1 приведена краткая характеристика категорий аналитических функций.
Для выполнения этих операций добавлено несколько элементов в обработку команд SQL. Эти элементы встроены в SQL. Существует несколько новых понятий, используемых аналитическими функциями.
- Порядок обработки (Processing Order). Запросы, использующие аналитические функции, обрабатываются в три стадии. Первая включает все соединения, WHERE, GROUP BY и HAVING. Вторая — применение аналитических функций к результирующему множеству. Третья — если есть предложение ORDER BY, то оно обрабатывается.
- Секционирование результирующего множества (Result Set Partitions). Аналитические функции позволяют пользователю разделить результирующее множество запроса на группы строк, называемых секциями. Термин "секция" (partitions) используется в другом смысле, отличающемся по значению от того, что использовался при секционировании таблицы. Он применяется для обозначения групп, которые создаются после группировки предложением GROUP BY. Эти секции строятся в соответствии со значением колонки группировки.
- Окна (Window). Для каждой строки в секции вы можете определить скользящее окно данных (sliding window of data). Это окно определяет интервал строк, используемых для вычислений от текущей строки. Размер окна может быть задан либо как физическое число строк, либо как логическое число строк (условием). Окно имеет начальную строку (starting row) и конечную строку (ending row). В зависимости от определения окно может перемещаться по результирующему множеству в один или оба конца. Например, окно, определенное для функции кумулятивных сумм, будет иметь своей стартовой строкой первую строку секции, и ее конечная строка будет скользить от начальной точки через все к последней строке секции. В противоположность этому, окно, определенное для скользящего среднего, будет иметь и начальную, и конечную точки, скользящие так, чтобы захватывать постоянный физический или логический интервал.
- Текущая строка (Current Row). Каждое вычисление с аналитическими функциями основывается на текущей строке в секции. Текущая строка поддерживается как ссылка на строку (позицию) внутри окна. Например, вычисление центрированного скользящего среднего может потребовать определения окна с 5-ю строками, предшествующими текущей, и 6-ю следующими за ней. Окно будет иметь размер в 12 строк.
Агрегатные и статистические функции
В Transact-SQL поддерживаются девять различных агрегатных функций, которые необходимы при проведении статистических расчетов. Помимо агрегатных функций, которые уже упоминались в предыдущей лекции, — SUM(), MIN(), MAX(), COUNT() и AVG() — имеются еще четыре, непосредственно предназначенные для финансовых и статистических вычислений: STDEV(), STDEVP(), VAR(), VARP() (табл. 23.2).
Статистические функции выполняют вычисление на наборе значений и возвращают одиночное значение. За исключением функции COUNT, эти функции не учитывают значения NULL. Также они часто используются в выражении GROUP BY команды SELECT.
Эти функции могут использоваться в качестве выражений только в следующих случаях:
- список выбора инструкции SELECT (вложенный или внешний запрос);
- предложение COMPUTE или COMPUTE BY ;
- предложение HAVING.
Указание ALL применяет функцию ко всем значениям. ALL является аргументом по умолчанию, а DISTINCT указывает, что рассматривается каждое уникальное значение.
Рассмотрим пример, в котором применяются встроенные агрегатные функции для вычисления основных статистических параметров.
Пример 23.1. Агрегатные и статистические функции
Пусть в ХД имеется таблица фактов "Население" ( Population ), содержание которой приведено в табл. 23.3, и таблица измерений "Район" ( Region ), физическая структура которых приведена на рис. 23.1.
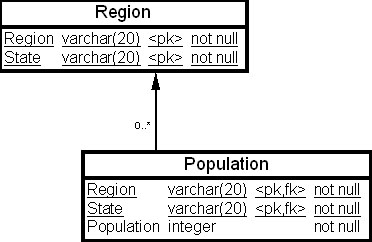
Рис. 23.1. Физическая структура таблицы фактов "Население" (Population) и таблицы измерений "Район" (Region)
Оператор SELECT, приведенный ниже, иллюстрирует применение агрегатных и статистических функций.
SELECT Region. MIN(Population) AS Minimum, MAX(Populations)AS Maximum, AVG(Population) AS Average. VAR(Population) AS Variance FROM Region GROUP BY Region ORDER BY Maximum DESC
Результат выполнения запроса приведен ниже.
Вывод 1.
Пример 23.2. Использование GROUPING
Предположим, что нам необходимо произвести статистическую обработку значений колонки "Объем продаж" (Sale), сгруппированных по колонке "Квота" (Quota) в таблице "Продажи" (Sales), структура которой показана на рис. 23.2. Функция GROUPING применяется к колонке Quota.
Следующий запрос решает поставленную задачу:
SELECT Quota, SUM(Sale) 'TotalSales', GROUPING(Quota) AS 'Grouping' FROM Sales GROUP BY Quota WITH ROLLUP; GO
В результирующем наборе показаны два значения NULL в колонке Quota. Первое значение NULL представляет группу значений NULL из этого столбца в таблице. Второе значение NULL находится в строке итогов, добавленной операцией ROLLUP. Строка итогов показывает суммы TotalSales для всех групп Quota и обозначается 1 в столбце Grouping.
Результат выполнения запроса приведен ниже.
Вывод 2.
| Quota | TotalSales | Grouping |
|---|---|---|
| NULL | 1533087.5999 | 0 |
| 250000.00 | 33461260.59 | 0 |
| 300000.00 | 9299677.9445 | 0 |
| NULL | 44294026.1344 | 1 |
В прикладной статистике используется много статистических функций. В следующем разделе мы покажем, как вычислять некоторые из них средствами языка SQL.
Медианы
Задачи позиционирования записей или задачи нахождения записей на основании их физического расположения в выборке исторически были сложными для решения средствами SQL. Найти запись по значению в языках, ориентированных на работу с множествами, довольно просто; найти же запись по позиции является сложной задачей.
Задача нахождения медиан представляет собой задачу позиционирования записей. Если в выборке нечетное количество записей, значение медианы равно значению записи, расположенной точно в середине выборки. Выше и ниже этого значения существует одинаковое количество элементов. Если в выборке четное количество значений, значение медианы равно либо среднему двух центральных значений (в случае финансовых медиан), либо меньшему из них (в случае статистических медиан).
Задача позиционирования записей значительно упрощается, когда в таблице есть уникальный последовательный целый ключ (identity-колонка). Если это так, ключ становится виртуальным номером записи, и имеется возможность обращаться к записям в любой позиции таблицы как к массиву. За счет этого мы можем вычислять медианы практически мгновенно даже для выборок, состоящих из миллионов значений.
Пример. 16.3. Вычисление медианы.
Пусть в ХД имеется таблица фактов "Финансы" (Finance), содержащая несколько миллионов значений цен на товары. Физическая структура таблицы приведена на рис. 23.3. Колонка ID создана с квалификатором типа identity. Записи отсортированы по значению колонки "Цена" (Price) за счет создания кластеризованного индекса, для чего была добавлена колонка ID, т.е. записи были просто перенумерованы. Индекс на колонку "Цена" (Price) был удален, а на колонку ID — создан.
Следующий запрос вычисляет финансовую медиану:
SELECT AVG(Price) AS "Финансовая медиана" FROM finance
WHERE ID BETWEEN MAX(ID) / 2 AND (MAX(ID) / 2) + SIGN(MAX{(ID) +1 % 2)Функция SIGN() используется для того, чтобы сделать обработку четного и нечетного числа записей в одном предложении BETWEEN. Выражение с этой функцией добавляет к количеству записей в выборке 1, чтобы изменить его с четного на нечетное или наоборот, затем вычисляет остаток от деления на число 2, чтобы понять, четное или нечетное число, и возвращает 1 или 0 в зависимости от знака.
Владислав Нагорный
Лариса Парфенова
|
1) Можно ли экстерном получить второе высшее образование "Программная инженерия" ? 2) Трудоустраиваете ли Вы выпускников? 3) Можно ли с Вашим дипломом поступить в аспирантуру?
|