
|
Подскажите, пожалуйста, планируете ли вы возобновление программ высшего образования? Если да, есть ли какие-то примерные сроки? Спасибо! |
Опубликован: 20.12.2010 | Уровень: специалист | Доступ: свободно
Лекция 2:
Хранилища данных
Аннотация: В настоящей лекции рассматривается концепция систем складирования данных и хранилищ данных, основные причины ее возникновения и сферы применения, вводятся и обсуждаются основные понятия, приведены примеры.
Ключевые слова: системы складирования данных, хранилища данных, системы операционной обработки данных, системы анализа данных, СППР, транзакционная обработка, автоматизированные информационные системы, конфликт по данным, оптимизация запросов, legacy systems, VMS, прогрессирующее, ИСР, EIS, business process reengineering, downsizing, business analyst, ПО, анализ, перекрестный запрос, гранулированность данных, Задача синхронизации, трансформация данных, data transfer, data scrubbing, депозитный счет, расширение моделей, статус завершения, денормализация, процесс нормализации, 1NF, 1НФ, вторая нормальная форма, 2NF, первичный ключ отношения, третья нормальная форма, 3NF, сущность предметной области, очистка данных, purge, атрибут сущности, уровни представления данных, corrupted data, реляционные операции, отгрузка товара, принятия решений, DSS, производительность, предметной области, рабочий цикл, data warehouse, СУБД, модель данных, БД
Цель лекции
Изучив материал настоящей лекции, вы будете:
- иметь представление о системах складирования данных и причинах их создания;
- понимать, что такое складирование данных (data warehousing) и хранилища данных (data warehouse) ;
- понимать необходимость разделения данных в системах операционной обработки данных и системах анализа данных ;
- иметь представление о представлении данных в хранилищах данных ;
- понимать особенности моделирования данных для хранилищ данных ;
и научитесь:
- определять причины создания хранилищ данных ;
- понимать процесс складирования данных, включая его основные элементы и средства управления этим процессом.
Литература: [1], [2], [3], [5], [7], [8], [9], [10], [11], [12], [13].
Концепция систем складирования данных
Введение
Информационная технология складирования данных (data warehousing) родилась в недрах компании IBM [1] и была окончательно сформулирована Б. Инмоном и Р. Кимбаллом в 90-х годах прошлого столетия [2,3] как метод решения информационно-аналитических задач в области принятия и поддержки решений. Возникнув на стыке технологии баз данных (БД), систем поддержки принятия решений (СППР — DSS) и компьютерного анализа данных, в дальнейшем концепция складирования данных претерпела эволюцию, поскольку оказалась пригодной для широкого круга приложений в бизнесе, науке и технологии.
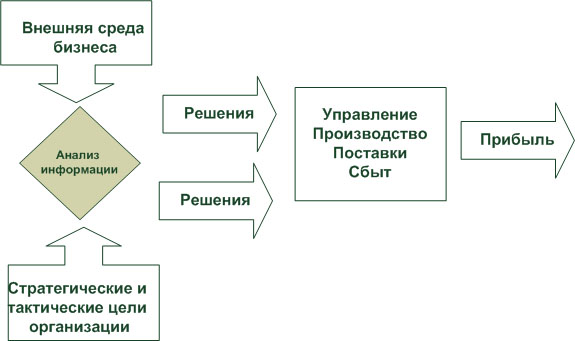
Основным посылом разработки концепции складирования данных явилось осознание руководством организаций потребности в анализе накопленных электронных массивов данных. На рис. 1.1 показана упрощенная принципиальная схема функционирования организации и место анализа непрерывно поступающей информации.
Во всем мире организации накапливают или уже накопили в процессе своей административно-хозяйственной деятельности большие объемы данных, в том числе и в электронном виде. Эти коллекции данных хранят в себе большие потенциальные возможности по извлечению новой аналитической информации, на основе которой можно и необходимо строить стратегию организации, выявлять тенденции развития рынка, находить новые решения, обусловливающие успешное развитие в условиях конкурентной борьбы. Для некоторых организаций такой анализ является неотъемлемой частью их повседневной деятельности, другие начинают активно приступать к такому анализу.
Системы, построенные на основе информационной технологии складирования данных, обладают рядом характерных особенностей, которые выделяют их как новый класс информационных систем (ИС). К таким особенностям относятся предметная ориентация системы, интегрированность хранимых в ней данных, собираемых из различных источников, инвариантность этих данных во времени, относительно высокая стабильность данных, необходимость поиска компромисса в избыточности данных.
Хранилище данных (ХД — data warehouse) является местом складирования собираемых в системе данных и информационным источником для решения задач анализа данных и принятия решений. Как правило, объем информации в ХД является достаточно большим. Упрощенно можно сказать, что хранилище данных управляет данными, которые были собраны как из операционных систем организации (OLTP-систем — On-Line Trasactions Processing), так и из внешних источников данных, и которые длительный период времени хранятся в системе. Более точное определение будет дано позже, после обсуждения истории создания концепции складирования данных.
Одной из главных целей создания систем складирования данных является их ориентация на анализ накопленных данных, т.е. структуризация данных в ХД должна быть выполнена таким образом, чтобы данные эффективно использовались в аналитических приложениях ( analytical applications ).
Заметим, что задачи анализа накопленных данных решали и до создания концепции складирования данных. В распоряжении аналитиков и сейчас имеется большой набор пакетов программ. Главным отличием использования концепции складирования данных является структуризация, систематизация, классификация, фильтрация и т. п. больших массивов электронной информации в виде, удобном для анализа, визуализации результатов анализа и производства корпоративной отчетности.
Концепция баз данных (БД) как метод представления и накопления данных в электронном виде сформировалась к середине 60-х годов прошлого века в фирме IBM. В 1969 году была создана первая СУБД для управления и манипулирования данными как самостоятельными информационными объектами. В 1970 году была предложена реляционная модель данных для БД [4], и на ее основе начали создаваться популярные ныне реляционные СУБД. В рамках реляционной модели с единых позиций были решены многие проблемы операционной (транзакционной) обработки данных.
С середины 80-х годов прошлого столетия стали интенсивно накапливаться электронные информационные массивы данных организаций, корпораций, научно-исследовательских учреждений. Так, в начале 90-х годов прошлого века только в области химических дисциплин было зарегистрировано более 7000 библиографических, фактографических и смешанных баз данных, ведущие мировые корпорации создали огромные электронные массивы конструкторской документации и документации по управлению производством. В это же время возникло четкое понимание, что сбор данных в электронном виде – не самоцель, накопленные информационные массивы могут быть полезны. Первыми осознали этот факт в области управления бизнесом и производством. В накопленных данных организации находится "информационный снимок" хронологии ее поведения на рынке. Анализ истории административно-хозяйственной деятельности организации позволил существенно увеличить эффективность ее управления, эффективно организовать взаимоотношения с клиентами, производство и сбыт.
Задачи анализа накопленных данных стали перелагаться "на плечи" компьютера и встраиваться в виде аналитических приложений в ИС с БД. Сейчас большинство исследователей сходятся к тому, что отправной точкой разработки концепции складирования данных явился ретроспективный (как иногда еще говорят, исторический) взгляд на данные, накопленные в организации как в электронном, так и в ином виде.
Отметим также, что использование технологий БД и ИС на уже разработанных моделях данных и методиках моделирования данных приводит к ряду проблем для аналитических приложений. Давайте рассмотрим, как управление анализом накопленных (и в этом смысле исторических) данных и какие факторы привели к развитию класса приложений складирования данных.
Предпосылки создания концепции складирования данных
Автоматизированная информационная система (ИС) с БД, будучи средством удовлетворения потребностей пользователей в информации как производственном ресурсе, работает с потоками информации, выраженными в потоках данных и операциях с ними. Как было указано выше, основной акцент на ранних стадиях эксплуатации ИС с БД строился на операционной концепции работы с данными. ИС, грубо говоря, должна была быстро и адекватно "переварить" поток данных для решения поставленных перед ней задач с помощью унифицированного набора операций манипулирования данными. Обработка данных сводилась к операциям вставки, удаления и обновления. Это было зафиксировано первоначально концепцией БД КОДАСИЛ [7].
Совместное действие этих операций в рамках ИС приводило к конфликтам в данных - потерям данных, ошибкам в обновлении и т.д. - так называемым аномалиям в данных. Предложив реляционную модель (которая является достаточно строго математической, а, следовательно, приемлемо контролируемой моделью), Е. Кодд в целом решил ряд проблем и задач операционной обработки данных [4,8-10]. Создание реляционных СУБД позволило достаточно грамотно (с учетом уровня компетентности разработчика) строить системы операционной (или, как ее еще называют, транзакционной) обработки данных - OLTP (On-Line Trasactions Proccessing).
На практике данные в операционных системах могут содержаться столь угодно долго, сколь в них имеется потребность. Несмотря на то, что производители жестких дисков постоянно увеличивают объемы этих дисков, хранить редко используемую информацию не имеет смысла по той простой причине, что производительность многих запросов с ростом объема данных начинает падать и совершенствование подсистем оптимизации запросов СУБД решает проблему ухудшения производительности запросов лишь отчасти. В целом с накоплением данных производительность обработки данных продолжает ухудшаться (эффект больших объемов).
Типичным организационным методом работы с редко используемыми данными является процедура архивизации. Во многих случаях процедура архивизации сводится к простому копированию данных на резервный носитель информации.
Таким образом, одной из проблем при решении задач анализа данных, помимо других скрытых проблем, в рамках операционных систем анализа данных является низкая производительность обработки запросов, которые готовят данные для последующего анализа. Такие запросы увеличивают нагрузку на процессоры ОС и в целом ухудшают обработку потока транзакций в БД, исходящего от систем операционной обработки данных.
Работа с архивом как чистой копией массива данных операционной системы обработки данных не решает проблему производительности. Отсюда простой практический ход - разделить решение задач обработки транзакций и задач анализа данных. В реляционных СУБД производительность запроса может быть улучшена за счет модификации модели данных. Архивные информационные массивы можно наделить структурой, отличной от структуры данных в несущей БД операционной ИС. Разработку таких структур данных можно связать с решением задач ретроспективного анализа данных, накопленных в системе. Это допустимо хотя бы потому, что в задачах анализа данных учитываются далеко не все функциональные зависимости, поддерживаемые в операционных БД. Поэтому структуру данных архивов стали проектировать под задачи анализа данных, неявно породив тем самым новый класс приложений.
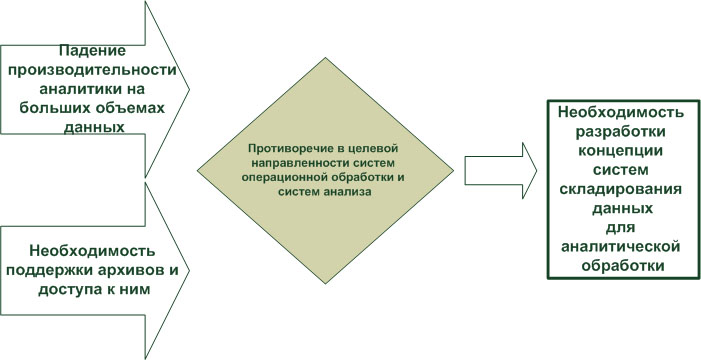
Фундаментальные требования к разработке операционных систем обработки данных и систем анализа данных различны: операционным системам нужна производительность, в то время как системам анализа данных нужны гибкость и широкие возможности для получения результата. Это противоречие в целевой направленности двух классов систем обработки данных явилось одной из основных предпосылок разработки концепции складирования данных ( рис. 1.3).
увеличить изображение
Рис. 1.3. Основной побудительный мотив разработки концепции систем складирования данных, следующий из опыта решения задач анализа на данных операционных систем обработки данных
Создание новой концепции потребовало пересмотра ряда традиционных подходов к обработке данных и перестройки технологических процедур. Поскольку перестройка технологических процедур является чрезвычайно затратным мероприятием, важно отметить те причины, которые явились дополнительными побудительными мотивами применения новой концепции на практике.
Системы, доставшиеся в наследство
Одной из первых таких причин является работа с данными, доставшимися по наследству (legacy systems — система, доставшаяся по наследству). Средства вычислительной техники (ВТ) быстро эволюционировали. В 80-х годах прошлого века появились миникомпьютеры на платформах AS/400 и VAX/VMS. Конец восьмидесятых и начало девяностых сделали ОС UNIX популярной серверной платформой для повсеместного введения новой архитектуры клиент /сервер. Начиная с 90-х, быстро стало прогрессировать семейство ОС MS Windows.
В то же время, начиная с 70-х годов, большинство систем обработки данных в сфере бизнеса создавалось на маэнфреймах фирмы IBM. Несмотря на все изменения в операционных платформах, архитектуре вычислительных систем, инструментальных средствах разработки программ и информационных технологиях, значительное количество бизнес-приложений в Америке и Европе продолжало и продолжает работать на оборудовании такого класса, что, кстати, стимулировало новый виток в развитии информационных технологий на мейнфреймах.
За годы эксплуатации в этих системах накоплены огромные бизнес-знания, было зафиксировано значительное количество бизнес-правил. Этот огромный объем информации невероятно трудно перенести на новые аппаратно-программные платформы или в приложения.
Системы, обобщенно называемые системами, доставшимися по наследству (legacy systems), продолжают быть самым большим источником данных для систем анализа данных. Однако время, требуемое на получение результатов работы таких приложений, часто оказывается значительно больше того, которое может позволить себе для ожидания конечный пользователь (по большей части руководство организации) в условиях современного бизнеса.
Перенос данных из централизованного ВЦ на рабочий стол пользователя
Второй причиной стал персональный компьютер, который позволил перенести данные из централизованного вычислительного центра на рабочий стол пользователя (в частности бизнес-аналитика).
Всего за несколько лет персональный компьютер (ПК) прочно утвердился на рабочем столе руководителей бизнеса, аналитиков и финансистов. Такая популярность ПК повлекла за собой интенсивную разработку программного обеспечения, в том числе и для анализа данных бизнеса. Хорошо подготовленные пользователи могут использовать настольные базы данных, которые позволяют им хранить и работать с информацией, извлеченной из источников данных систем, доставшихся по наследству. Персональный компьютер и его программный инструментарий перенесли работу по анализу данных из больших вычислительных центров (ВЦ) на рабочий стол пользователя. Эффективность аналитической работы в особенно крупных организациях стала расти.
Вовлечение конечных пользователей для решения задач управления данными в условиях коллективного их использования не является выходом из создавшейся ситуации. Во-первых, это требует времени и усилий конечных пользователей (а следовательно, денег). Во-вторых, у них есть основная работа – анализ данных, которая им интересна и за которую им платят жалованье. Вовлечение их в работу в сфере информационных технологий совершенно точно приведет к снижению эффективности их основной работы.
Широкое применение персональных компьютеров в анализе данных привело к другой проблеме. Отсутствие общих стандартов представления данных в организации, большая свобода в выборе представления данных конечным пользователем, сбрасывание со счетов требований коллективного использования данных приводит к анархии в работе с данными, и, как следствие, появляется опасная тенденция несогласованности коллективно используемых данных, которая может сказываться на качестве принятия стратегических решений.
Системы поддержки и принятия решений и управленческие информационные системы
Еще одной причиной стало интенсивное использование систем поддержки и принятия решений (СППР — DSS) и управленческих информационных систем (ИСР — EIS, информационная система руководителя). СППР обычно фокусируются на более детальном представлении информации и ориентированы больше на менеджеров среднего уровня. ИСР обеспечивают более высокий уровень консолидации и многоаспектного (многомерного представления) взгляда на данные, поскольку руководители высокого уровня нуждаются в большем многообразии представления тех же самых данных для детального анализа.
Эти два схожих и перекрывающихся по функциям класса систем являются одной из главных предпосылок для создания концепции систем складирования данных. Отметим некоторые признаки, обычно связываемые с системами этого класса.
- В этих системах данные представлены в стандартных терминах бизнеса, а не в закодированной форме (имена полей в БД ИС). Наименования элементов данных и структуры данных в этих системах проектируются для использования конечными пользователями с невысоким уровнем подготовки в области информационных систем.
- Данные в таких системах предварительно обрабатываются в контексте стандартных бизнес-правил, таких как размещения ассигнований по продуктам, производственным единицам и рынкам.
- Допускается консолидированное представление данных по таким категориям, как продукт, производитель и рынок. Хотя в таких системах время от времени допускается развертывание интегрированных данных, они способны обеспечить доступ ко всей детальной информации в одно и то же время.
В настоящее время системы складирования данных обеспечивают аналитические инструменты для решения таких задач, но их разработка строится не на специфических требованиях аналитиков или исполнителей, а основывается на структуре бизнеса организации. С этой точки зрения системы складирования данных дали новый виток в развитии СППР и ИСР.
Развитие технологий
Не следует забывать также о факторах, связанных с техническим прогрессом в области разработки аппаратного обеспечения ЭВМ и развитием компьютерных технологий в разработке программного обеспечения. Это обстоятельство привело к снижению цен на комплектующие с одновременным ростом их мощности, созданию дружественных интерфейсов для пользователей.
Наиболее важным фактором в развитии складирования данных стало увеличение мощности аппаратной платформы компьютеров, поскольку ХД хранят обычно очень большие объемы информации. Параллельно росла вычислительная мощность ПК и развитое программное обеспечение, которые позволили разработать и внедрить архитектуру клиент/сервер. Почти ко всем ХД можно обратиться с ПК, оснащенного развитыми инструментальными программными средствами. Эти средства изменяются от очень простых обработчиков запросов до мощных графических многомерных средств анализа данных. Создание серверных операционных систем, таких как Windows и Unix, повысило надежность в функционировании и дало мощные возможности распределенной вычислительной среде. Эти технологические факторы способствовали быстрому развитию систем складирования данных.
Создание и распространение Интернет/Интранет привело к тому, что бизнес стал перемещаться в Интернет. Сегодня одной из наиболее значительных областей компьютерной индустрии является разработка интранет-приложений. Грубо говоря, Интранет является совокупностью локальных компьютерных сетей, ориентированных на бизнес, которые основываются на стандартах сети Интернет, хотя проектируются для внутреннего использования в организации. ХД может быть доступно из любой точки сети, как локальной, так и глобальной, и стоимость доступа к нему значительно снижается по сравнению с обычной технологией. С другой стороны, использование технологии Интернет позволяет веб-серверу обеспечить обработку данных в узлах их размещения, что приводит к выполнению всех трудоемких процедур анализа до того, как его результаты представляются пользователю в его браузере.
Структурные изменения в бизнесе
Значительное влияние на формирование концепции складирования данных оказали фундаментальные изменения в организации бизнеса и изменения в его структуре в конце прошлого века. Появление ярко выраженной глобальной экономики изменило требования к информации и спрос на нее. Деятельность организаций пересекла границы своей страны и тем самым стала транснациональной.
Изменение экономических условий побудили большие корпорации к объединению (консолидации) своих усилий. Появление таких механизмов, как реинжениринг бизнес-процессов (business process reengineering) и перестраиваемость бизнеса (downsizing), вынудило руководителей переоценить практику ведения бизнеса. Пересмотр процедур ведения бизнеса и изменения в финансовых потоках сыграли важную роль в развитии концепции складирования данных.
Глобализация экономики выдвигает не только требования непрерывного анализа потоков экономических данных, но и определенные требования к сбору и размещению деловой информации. Теперь процесс сбора и свертывания производственных и коммерческих данных от разбросанных по всему миру производственных подразделений оказывает сильное влияние на принятие решений в корпорациях. Глобализация делает процедуры размещения данных в централизованном хранилище данных более сложными. Колебания стоимости валют или сезонные колебания в сбыте продукции в различных регионах мира добавили трудности к складированию данных и делают анализ данных более сложным.
Появление стандартов для программного обеспечения бизнеса
Еще одним важным фактором, который повлиял на развитие ХД, явилось появление специализированных поставщиков решений в автоматизации бизнеса. Фирмы-разработчики ПО SAP AG, Baan, Oracle, Microsoft, IBM и др. предлагают быстро адаптируемые к бизнес-процессам программные продукты для управления бизнесом. Разработка комплексного ПО для управления бизнесом привела к интенсификации процессов стандартизации бизнеса и стандартизации программного обеспечения. Информация в ХД поступает в унифицированном виде из всех ИС управления бизнесом, а не только из систем, доставшихся по наследству. Следует также отметить тенденцию последних лет в разработке ПО данного класса приложений — обеспечение возможности собирать информацию в ХД из данных любых внешних источников (например продукты компании SAS).
Требования пользователей
Один из наиболее важных результатов массивной инвестиции в технологию и создание высокопроизводительных ПК привел к созданию методов анализа, основанного на здравом смысле (technology-savvy business analyst). Даже если технология здравого смысла конечного пользователя не всегда выгодна для многих проектов, тенденция ее применения привела к созданию более сложных технологий анализа для сегодняшнего бизнеса. Однако именно на технологии здравого смысла была продемонстрирована выгода использования хранилищ данных и развития логических и физических моделей.
Текстовые редакторы и крупноформатные таблицы, столь популярные на первых ПК, оказали существенное влияние на представление данных в хранилищах данных.
Очень сильно влияют на тенденции развития информационных технологий требования к информации, предъявляемые средним и высшим звеном управляющего персонала. Информационные технологии стали производственным ресурсом компаний – это первый результат таких требований. Электронная почта, Интернет, мобильный телефон и карманный ПК вовлечены в процесс управления. Это также требования, приходящие от руководителей организаций и компаний. Им нужен быстрый и качественный доступ к аналитической информации в любой момент времени и по любому виду каналов связи.
Как видно из вышесказанного, потребности бизнеса в новых экономических условиях, создание мощной программно-аппаратной платформы, распространение информационных технологий создали предпосылки рождения нового класса приложений — систем складирования данных и концепции ХД как информационного носителя для таких приложений.
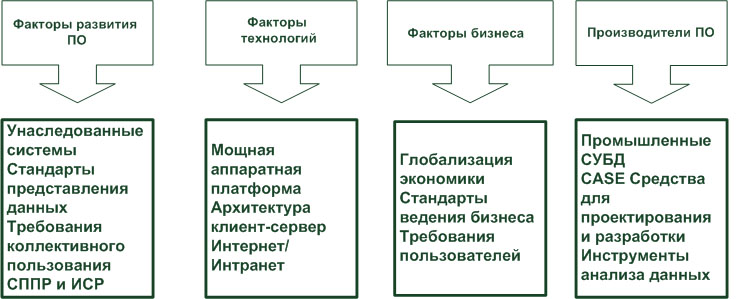
На рис. 1.4 просуммированные основные факторы, способствующие созданию и развитию концепции систем складирования данных и хранилищ данных.
Владислав Нагорный
Лариса Парфенова
|
1) Можно ли экстерном получить второе высшее образование "Программная инженерия" ? 2) Трудоустраиваете ли Вы выпускников? 3) Можно ли с Вашим дипломом поступить в аспирантуру?
|