|
приветствую создателей курса и благодарю за доступ к информации! понимаю, что это уже никто не исправит, но, возможно, будут следующие версии и было бы неплохо дать расшифровку сокращений имен регистров итд, дабы закрепить понимание их роли в общем процессе. |
Опубликован: 03.03.2010 | Уровень: специалист | Доступ: свободно | ВУЗ: Национальный исследовательский ядерный университет «МИФИ»
Лекция 13:
Многопроцессорные и многомашинные вычислительные системы
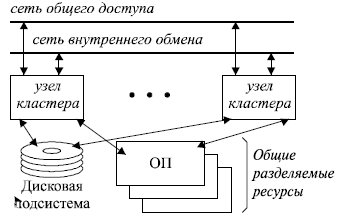
Кластер представляет собой систему из нескольких компьютеров (в большинстве случаев серийно выпускаемых), имеющих общий разделяемый ресурс для хранения совместно обрабатываемых данных (обычно набор дисков или дисковых массивов) и объединенных высокоскоростной магистралью (рис. 13.3).
В кластерной системе некоторое распределенное приложение параллельно на нескольких узлах обрабатывает общий набор данных, как правило, таким образом, чтобы у пользователя возникла иллюзия работы на одной машине.
Обычно в кластерных системах не обеспечивается единая операционная среда для работы общего набора приложений на всех узлах кластера. То есть каждый компьютер кластера - это автономная система с отдельным экземпляром ОС и своими, принадлежащими только ей системными ресурсами: набором заведенных пользователей, системными буферами, областью свопинга и т. п. Приложение, запущенное на нем, может видеть только общие диски или отдельные участки памяти. На узлах кластера работают специально написанные для такой конфигурации приложения, параллельно обрабатывающие общий набор данных. На каждой из машин они представлены рядом процессов, программ, взаимодействующих с помощью кластерного программного обеспечения. Таким образом, кластерное ПО - это лишь средство для взаимодействия узлов и синхронизации доступа к общим данным. Кластер как параллельная система формируется на прикладном уровне, а не на уровне операционной системы.
В настоящее время такие системы имеют две основные области применения: параллельные серверы баз данных и высоконадежные вычислительные комплексы. Рынок параллельных СУБД и есть фактически рынок кластеров приложений. Высоконадежные комплексы представляют собой группу узлов, на которых независимо друг от друга выполняются некоторые важные приложения, требующие постоянной, непрерывной работы. То есть в такой системе на аппаратном уровне фактически поддерживается основной механизм повышения надежности - резервирование. Причем узлы находятся в так называемом "горячем" резерве, и каждый из них в любой момент готов продолжить вычисления при выходе из строя какого-либо узла. При этом все приложения с отказавшего узла автоматически переносятся на другие машины комплекса. Такая система также формально является кластером, хотя в ней отсутствует параллельная обработка общих данных. Эти данные обычно монопольно используются выполняемыми в рамках кластера приложениями и должны быть доступны для всех узлов.
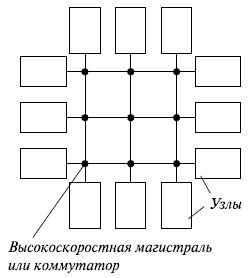
Если в кластере его узлы разделяют некоторые ресурсы, то параллельные системы другого класса - системы вычислений с массовым параллелизмом (MPP) - строятся из отдельных полностью независимых компьютеров, соединенных только высокоскоростной магистралью или коммуникационными каналами (рис. 13.4). Это могут быть либо просто несколько серийно выпускаемых UNIX-машин, соединенных с помощью высокопроизводительной сетевой среды, либо специально сконструированная система из отдельных функциональных блоков, объединенных коммутатором.
В такой системе адресное пространство состоит из отдельных адресных пространств, которые логически не связаны между собой и доступ к которым не может быть осуществлен аппаратно другим процессором.
При этом для обмена данными используется механизм передачи сообщений между процессорами. Поэтому эти машины часто называют машинами с передачей сообщений. Пользователь может определить логический номер процессора, к которому он подключен, и организовать обмен сообщениями с другими процессорами.
На машинах MPP-архитектуры используются два варианта работы операционной системы. В одном из них полноценная операционная система работает только на управляющей машине (front-end); на каждом отдельном модуле функционирует сильно урезанный вариант ОС, обеспечивающий работу только расположенной в нем ветви параллельного приложения. Во втором варианте на каждом модуле работает полноценная, как правило, UNIX-подобная ОС, устанавливаемая отдельно.
Программирование в такой системе - достаточно сложная задача.
Она требует специального инструментария и особого системного программного обеспечения для работы параллельных приложений, которые ориентированы на функционирование параллельных процессов, распределенных по узлам MPP-системы, с обменом сообщениями между ними.
Повышение производительности машин с массовым параллелизмом путем увеличения в них числа процессоров имеет определенные ограничения. Чем большее число процессоров входит в состав MPP-системы, тем длиннее каналы передачи управления и данных, а значит, и тем меньше тактовая частота. Происшедшее возрастание нормы массивности для больших машин до 512 и даже 64К процессоров обусловлено не ростом размеров машины, а увеличением степени интеграции схем, позволившей за последние годы резко повысить плотность размещения элементов в устройствах. Топология сети межпроцессорного обмена в такого рода системах может быть различной.
Главным преимуществом MPP-систем является их хорошая масштабируемость: в отличие от SMP-систем, здесь каждый процессор имеет доступ только к своей локальной памяти, в связи с чем не возникает необходимости в потактовой синхронизации процессоров. Практически все рекорды по производительности на сегодня устанавливаются на машинах именно такой архитектуры, состоящих из нескольких тысяч процессоров.
Основными недостатками систем данного типа являются следующие:
- отсутствие общей памяти заметно снижает скорость межпроцессорного обмена, поскольку нет общей среды для хранения данных, предназначенных для обмена между процессорами;
- требуется специальная техника программирования для реализации обмена сообщениями между процессорами;
- каждый процессор может использовать только ограниченный объем локального банка памяти;
- вследствие указанных архитектурных недостатков требуются значительные усилия для того, чтобы максимально задействовать системные ресурсы, следствием чего является высокая цена программного обеспечения для MPP-систем с раздельной памятью.
Подведем некоторые итоги, касающиеся областей применимости систем параллельной обработки данных различных типов.
SMP-системы потенциально обладают достаточными возможностями для обеспечения необходимой для большинства применений производительности: вполне естественно увеличивать число процессоров, а не ставить рядом еще один компьютер. Добавление одного процессора гарантированно увеличивает производительность, а добавление, например, узла в кластер адекватного ускорения не даст. Более того, в некоторых случаях общая производительность системы может даже упасть, когда узлы кластера начинают активно конкурировать за доступ к общим ресурсам, и взаимные блокировки сводят на нет преимущества параллельной обработки.
NUMA-системы создаются для вполне определенных целей - обеспечения масштабных расчетов. Системы, использующие эту архитектуру, прежде всего применяются для уникальных высококачественных и высокопроизводительных прикладных программ, требующих более восьми процессоров. Однако они имеют высокую стоимость и требуют уникального ПО (прикладные программы и ОС).
Для современных систем помимо вполне традиционных требований по производительности, масштабируемости, цене дополнительные высокие требования предъявляются к надежности их работы. Именно по этим соображениям вычислительные комплексы на основе кластеров или MPP-машин завоевывают все большую популярность.
MPP-системы обладают рядом преимуществ, главным из которых является лучшая среди всех рассмотренных архитектур масштабируемость. Именно поэтому MPP-компьютеры обычно используются при больших ресурсоемких вычислениях. Конечно, они применяются и при построении больших баз данных, и в отказоустойчивых вычислительных комплексах. Но здесь их использование довольно ограничено. Это отчасти связано с тем, что они все-таки дороже кластеров и имеют достаточно большую начальную цену. Кластер же можно построить из относительно дешевых машин произвольной конфигурации.
Приведенная классификация систем параллельной обработки данных достаточно условна. Разработчики вычислительных систем не проектируют машину какого-то специального класса, а стараются создать более производительную архитектуру. Кроме этого, сам пользователь может с использованием стандартных компонентов спроектировать комплекс, архитектурно и функционально наиболее подходящий для решения конкретной задачи.
Владислав Салангин
