|
приветствую создателей курса и благодарю за доступ к информации! понимаю, что это уже никто не исправит, но, возможно, будут следующие версии и было бы неплохо дать расшифровку сокращений имен регистров итд, дабы закрепить понимание их роли в общем процессе. |
Опубликован: 03.03.2010 | Уровень: специалист | Доступ: свободно | ВУЗ: Национальный исследовательский ядерный университет «МИФИ»
Лекция 13:
Многопроцессорные и многомашинные вычислительные системы
Аннотация: Цель лекции: рассмотреть способы организации и области применения многопроцессорных и многомашинных вычислительных систем.
Ключевые слова: параллельная обработка данных, ПО, SISD, MISD, SIMD, MIMD, instruction stream, data stream, одиночный поток команд, одиночный поток данных, поток команд, команда, процессор, конвейерная обработка, множественный поток данных, MMX, SSE, микропроцессорная система, процессорный элемент, память, множественный поток команд, определение, поток, модель вычислений, разделяемые данные, архитектура, стоимость, производительность, многопроцессорная система, symmetric multiprocessing, SMPS, memory access, NUMA, &-параллелизм, massive parallelism, processor-specific, MPP, доступ, системное ПО, разделяемый ресурс, механизмы, распараллеливание вычислений, процессорное ядро, быстродействие, межпроцессорный, приложение, общая память, пропускная способность, шина, разрешение конфликтов, Вычислительный элемент, конфликт, слот, увеличение производительности, поддержка, магистраль, микропроцессор, pentium pro, APIC, advanced, programmability, interrupt controller, CPU, идентификация, арбитраж, шина данных, MCM, суперкомпьютер, серверное приложение, исполнение, критическая область, коммутатор, пространство, единое адресное пространство, права доступа, DSM, shared memory, адрес, cc-numa, coherency, неоднородный доступ к памяти, кэширование данных, разделы, время доступа, tera, itanium, ресурс, кластерная система, операционная среда, компьютер, системный ресурс, свопинг, кластер, СУБД, параллельная обработка, адресное пространство, пользователь, логический, обмен сообщениями, операционная система, front, программирование, параллельный процесс, тактовая частота, топология, масштабируемость, скорость межпроцессорного обмена, computer, транспьютер, АЛУ, линк, встроенный интерфейс, работ, буфер, деятельность, планировщик , программа, мощность, EPIC, фирма, extension, MODULE, Ethernet, SCSI, класс
Многопроцессорные и многомашинные вычислительные системы
В настоящее время тенденция в развитии микропроцессоров и систем, построенных на их основе, направлена на все большее повышение их производительности. Вычислительные возможности любой системы достигают своей наивысшей производительности благодаря двум факторам:
использованию высокоскоростных элементов и параллельному выполнению большого числа операций. Направления, связанные с повышением производительности отдельных микропроцессоров, мы рассматривали в предыдущих лекциях, а в этой лекции остановимся на вопросах распараллеливания обработки информации.
Существует несколько вариантов классификации систем параллельной обработки данных. По-видимому, самой ранней и наиболее известной является классификация архитектур вычислительных систем, предложенная в 1966 году М. Флинном. Классификация базируется на понятии потока, под которым понимается последовательность элементов, команд или данных, обрабатываемая процессором. На основе числа потоков команд и потоков данных выделяются четыре класса архитектур:
SISD ( sINgle INsTRuction sTReam / sINgle data sTReam ) - одиночный поток команд и одиночный поток данных. К этому классу относятся прежде всего классические последовательные машины, или, иначе, машины фон-неймановского типа. В таких машинах есть только один поток команд, все команды обрабатываются последовательно друг за другом и каждая команда инициирует одну операцию с одним потоком данных. Не имеет значения тот факт, что для увеличения скорости обработки команд и скорости выполнения арифметических операций процессор может использовать конвейерную обработку. В таком понимании машины данного класса фактически не относятся к параллельным системам.
SIMD ( sINgle INsTRuction sTReam / multIPle data sTReam ) - одиночный поток команд и множественный поток данных. Применительно к одному микропроцессору этот подход реализован в MMX- и SSE- расширениях современных микропроцессоров. Микропроцессорные системы типа SIMD состоят из большого числа идентичных процессорных элементов, имеющих собственную память. Все процессорные элементы в такой машине выполняют одну и ту же программу. Это позволяет выполнять одну арифметическую операцию сразу над многими данными - элементами вектора. Очевидно, что такая система, составленная из большого числа процессоров, может обеспечить существенное повышение производительности только на тех задачах, при решении которых все процессоры могут делать одну и ту же работу.
MISD (multIPe INsTRuction sTReam / sINgle data sTReam ) - множественный поток команд и одиночный поток данных. Определение подразумевает наличие в архитектуре многих процессоров, обрабатывающих один и тот же поток данных. Ряд исследователей к данному классу относят конвейерные машины.
MIMD (multIPe INsTRuction sTReam / multIPle data sTReam ) - множественный поток команд и множественный поток данных. Базовой моделью вычислений в этом случае является совокупность независимых процессов, эпизодически обращающихся к разделяемым данным. В такой системе каждый процессорный элемент выполняет свою программу достаточно независимо от других процессорных элементов. Архитектура MIMD дает большую гибкость: при наличии адекватной поддержки со стороны аппаратных средств и программного обеспечения MIMD может работать как однопользовательская система, обеспечивая высокопроизводительную обработку данных для одной прикладной задачи, как многопрограммная машина, выполняющая множество задач параллельно, и как некоторая комбинация этих возможностей. К тому же архитектура MIMD может использовать все преимущества современной микропроцессорной технологии на основе строгого учета соотношения стоимость/производительность. В действительности практически все современные многопроцессорные системы строятся на тех же микропроцессорах, которые можно найти в персональных компьютерах, рабочих станциях и небольших однопроцессорных серверах.
Как и любая другая, приведенная выше классификация несовершенна: существуют машины, прямо в нее не попадающие, имеются также важные признаки, которые в этой классификации не учтены. Рассмотрим классификацию многопроцессорных и многомашинных систем на основе другого признака - степени разделения вычислительных ресурсов системы.
В этом случае выделяют следующие 4 класса систем:
- системы с симметричной мультипроцессорной обработкой (symmeTRic multIProcessINg), или SMP-системы;
- системы, построенные по технологии неоднородного доступа к памяти (non-un IForm memory access), или NUMA-системы;
- кластеры;
- системы вычислений с массовым параллелизмом (massively parallel processor), или MPP-системы.
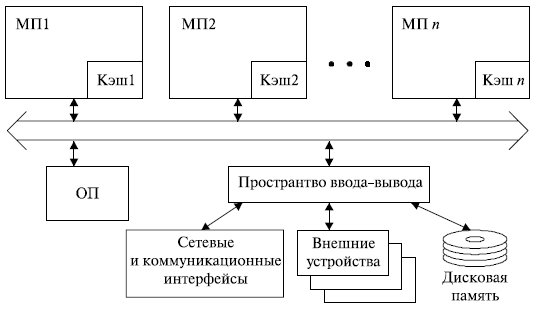
Самым высоким уровнем интеграции ресурсов обладает система с симметричной мультипроцессорной обработкой, или SMP-система (рис. 13.1).
В этой архитектуре все процессоры имеют равноправный доступ ко всему пространству оперативной памяти и ввода/вывода. Поэтому SMP-архитектура называется симметричной. Ее интерфейсы доступа к пространству ввода/вывода и ОП, система управления кэш-памятью, системное ПО и т. п. построены таким образом, чтобы обеспечить согласованный доступ к разделяемым ресурсам. Соответствующие механизмы блокировки заложены и в шинном интерфейсе, и в компонентах операционной системы, и при построении кэша.
С точки зрения прикладной задачи, SMP-система представляет собой единый вычислительный комплекс с вычислительными ресурсами, пропорциональными количеству процессоров. Распараллеливание вычислений обеспечивается операционной системой, установленной на одном из процессоров. Вся система работает под управлением единой ОС (обычно UNIX-подобной, но для Intel-платформ поддерживается WINdows NT).
ОС автоматически в процессе работы распределяет процессы по процессорным ядрам, оптимизируя использование ресурсов. Ядра задействуются равномерно, и прикладные программы могут выполняться параллельно на всем множестве ядер. При этом достигается максимальное быстродействие системы. Важно, что для синхронизации приложений вместо сложных механизмов и протоколов межпроцессорной коммуникации применяются стандартные функции ОС. Таким образом, проще реализовать проекты с распараллеливанием программных потоков. Общая для совокупности ядер ОС позволяет с помощью служебных инструментов собирать статистику, единую для всей архитектуры. Соответственно, можно облегчить отладку и оптимизацию приложений на этапе разработки или масштабирования для других форм многопроцессорной обработки.
В общем случае приложение, написанное для однопроцессорной системы, не требует модификации при его переносе в мультипроцессорную среду. Однако для оптимальной работы программы или частей ОС они переписываются специально для работы в мультипроцессорной среде.
Сравнительно небольшое количество процессоров в таких машинах позволяет иметь одну централизованную общую память и объединить процессоры и память с помощью одной шины.
Сдерживающим фактором в подобных системах является пропускная способность магистрали, что приводит к их плохой масштабируемости. Причиной этого является то, что в каждый момент времени шина способна обрабатывать только одну транзакцию, вследствие чего возникают проблемы разрешения конфликтов при одновременном обращении нескольких процессоров к одним и тем же областям общей физической памяти. Вычислительные элементы начинают мешать друг другу. Когда произойдет такой конфликт, зависит от скорости связи и от количества вычислительных элементов. Кроме того, системная шина имеет ограниченное число слотов. Все это очевидно препятствует увеличению производительности при увеличении числа процессоров. В реальных системах можно задействовать не более 32 процессоров.
В современных микропроцессорах поддержка построения мультипроцессорной системы закладывается на уровне аппаратной реализации МП, что делает многопроцессорные системы сравнительно недорогими.
Так, для обеспечения возможности работы на общую магистраль каждый микропроцессор фирмы Intel начиная с Pentium Pro имеет встроенную поддержку двухразрядного идентификатора процессора - APIC (Advanced Programmable INTerrupt ConTRoller). По умолчанию CPU с самым высоким номером идентификатора становится процессором начальной загрузки. Такая идентификация облегчает арбитраж шины данных в SMP-системе. Подобные средства мы видели и в МП Power4, где на аппаратном уровне поддерживается создание микросхемного модуля MCM из 4 микропроцессоров, включающего в совокупности 8 процессорных ядер.
Сегодня SMP широко применяют в многопроцессорных суперкомпьютерах и серверных приложениях. Однако если необходимо детерминированное исполнение программ в реальном масштабе времени, например, при визуализации мультимедийных данных, возможности сугубо симметричной обработки весьма ограничены. Может возникнуть ситуация, когда приложения, выполняемые на различных ядрах, обращаются к одному ресурсу ОС. В этом случае доступ получит только одно из ядер.
Остальные будут простаивать до высвобождения критической области.
Естественно, при этом резко снижается производительность приложений реального времени.
Исчерпание производительности системной шины в SMP-системах при доступе большого числа процессоров к общему пространству оперативной памяти и принципиальные ограничения шинной технологии стали причиной сдерживания роста производительности SMP-систем. На данный момент эта проблема получила два решения. Первое - замена системной шины на высокопроизводительный коммутатор, обеспечивающий одновременный неблокирующий доступ к различным участкам памяти. Второе решение предлагает технология NUMA.
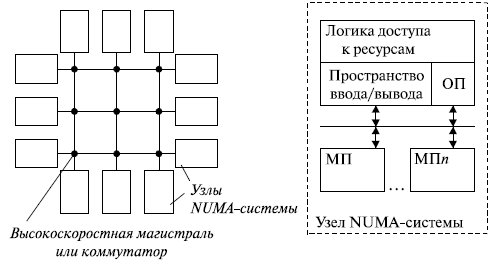
Система, построенная по технологии NUMA, представляет собой набор узлов, каждый из которых, по сути, является функционально законченным однопроцессорным или SMP-компьютером. Каждый имеет свое локальное пространство оперативной памяти и ввода/вывода. Но с помощью специальной логики каждый имеет доступ к пространству оперативной памяти и ввода/вывода любого другого узла (рис. 13.2). Физически отдельные устройства памяти могут адресоваться как логически единое адресное пространство - это означает, что любой процессор может выполнять обращения к любым ячейкам памяти, в предположении, что он имеет соответствующие права доступа. Поэтому иногда такие системы называются системами с распределенной разделяемой памятью (DSM - disTRibuted shared memory).
При такой организации память каждого узла системы имеет свою адресацию в адресном пространстве всей системы. Логика доступа к ресурсам определяет, к памяти какого узла относится выработанный процессором адрес. Если он не принадлежит памяти данного узла, организуется обращение к другому узлу согласно заложенной в логике доступа карте адресов. При этом доступ к локальной памяти осуществляется в несколько раз быстрее, чем к удаленной.
При использовании наиболее распространенного сейчас варианта cc-NUMA (cache-coherent NUMA - неоднородный доступ к памяти с согласованием содержимого кэш-памяти) обеспечивается кэширование данных оперативной памяти других узлов.
Обычно вся система работает под управлением единой ОС, как в SMP. Возможны также варианты динамического разделения системы, когда отдельные разделы системы работают под управлением разных ОС.
Довольно большое время доступа к оперативной памяти соседних узлов по сравнению с доступом к ОП своего узла в NUMA-системах на настоящий момент делает такое использование не вполне оптимальным.
Так что полной функциональностью SMP-систем NUMA-компьютеры на сегодняшний день не обладают. Однако среди систем общего назначения NUMA-системы имеют один из наиболее высоких показателей по масштабируемости и, соответственно, по производительности. На сегодня максимальное число процессоров в cc-NUMA-системах может превышать 1000 (серия OrigIN3000). Один из наиболее производительных суперкомпьютеров - Tera 10 - имеет производительностью 60 Тфлопс и состоит из 544 SMP-узлов, в каждом из которых находится от 8 до 16 процессоров Itanium 2.
Следующим уровнем в иерархии параллельных систем являются комплексы, также состоящие из отдельных машин, но лишь частично разделяющие некоторые ресурсы. Речь идет о кластерах.
Владислав Салангин
