Опубликован: 30.05.2023 | Уровень: для всех | Доступ: свободно
Лекция 3:
Эволюция ИИ в процессе решения практических задач
![Базовые приложения на основе технологии NLP. Источник: [78]](/EDI/18_12_24_2/1734474022-28631/tutorial/963/objects/2/files/02-18.jpg)
Дополнительно об NLP-приложениях и типах компаний, занятых в их разработке, речь пойдет во второй лекции данного курса, а в данном разделе более подробно поговорим об истории формирования и эволюции NLP-технологий.
Можно сказать, что NLP находится на пересечении лингвистики 23Наука о естественном языке, его природе и структурах. Области лингвистического анализа включают: синтаксис (правила, регулирующие структуру предложений); семантику (значение); морфологию (структуру слов); фонетику (звуки речи) и т. п. и технологий искусственного интеллекта (см. рис. 2.19), при том, что вектор эволюции NLP направлен от лингвистики к технологиям глубокого обучения.
![NLP находится на пересечении лингвистики и технологий искусственного интеллекта. Источник: [79]](/EDI/18_12_24_2/1734474022-28631/tutorial/963/objects/2/files/02-19.jpg)
Рис. 2.19. NLP находится на пересечении лингвистики и технологий искусственного интеллекта. Источник: [79]
В самом общем плане в развитии NLP можно выделить три этапа - символьный (с 1950-х до начала 1990-х годов), статистический (1990-2010) и нейросетевой (2010 - до настоящего времени). Отмеченные периоды достаточно наглядно просматриваются на примере машинного перевода, о котором следует сказать более подробно (рис. 2.20).
![Краткая история машинного перевода. Источник: [80]](/EDI/18_12_24_2/1734474022-28631/tutorial/963/objects/2/files/02-20.jpg)
Историю машинного перевода обычно отсчитывают с так называемого Джорджтаунского эксперимента (1954 год), когда программа, состоявшая из шести правил, перевела 60 предложений с транслитерированного 24Транслитерация - передача знаков одной письменности знаками другой письменности, в данном случае русский текст был записан с помощью латинского алфавита русского на английский язык.
Задачи обработки естественного языка потребовали разработки модели представления текстов для компьютерной обработки. Об одной из первых таких моделей - "мешок слов" - следует кратко напомнить читателю, что будет полезно для дальнейших рассуждений 25Одно из первых упоминаний о модели "мешок слов" в лингвистическом контексте можно найти в статье Зеллига Харриса за 1954 год . Мешок слов Bagof-words (BoW) - это простейшая модель представления информации о тексте в числовом виде, используемая в обработке естественного языка. Текст в этой модели представляется как набор слов, без учета грамматики и порядка.
Поясним методику на простом примере. Пусть имеется документ с текстом из известной песни "Пусть всегда будет солнце, пусть всегда …" и так далее (рис.2.21).
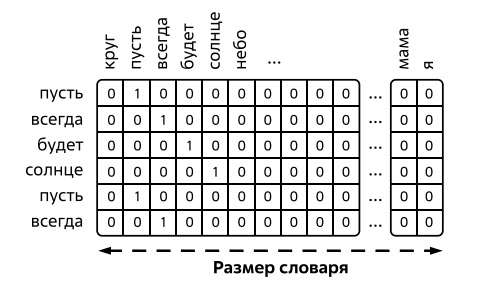
Сверху выписаны все слова, встречающиеся в документе (словарь). Для кодирования слов использована процедура так называемого "One Hot Encoding", или OHE-кодирования, суть которой поясняется на рис. 2.21 - каждое слово представляется вектором, длина которого равна длине словаря. Во всех позициях вектора стоят нули, кроме позиции, соответствующий номеру этого слова в словаре, - там, соответственно, стоит единица.
Как видно из рисунка, строчки соответствуют словам текста песни. Чтобы создать вектор, который кодировал бы весь документ (мешок слов), достаточно сложить one-hot-вектора каждого из слов. В таком векторе теряется информация о последовательности слов в тексте и остается только информация о наборе слов в рассматриваемом документе, отсюда и происходит название "мешок слов".
Недостатком подхода является то, что информация о взаимном расположении слов и связях между ними отбрасывается. Кроме того, при большом словаре векторы содержат большое количество нулей - такая "разреженная" форма представления информации имеет свои недостатки, поскольку работа с подобными векторами требует большого объема памяти и вычислительных ресурсов.
Рассмотрим основные этапы эволюции систем машинного перевода. Первый этап - это перевод, основанный на правилах, или RBMT-перевод (сокращение от "Rule Based Machine Translation"). Самая первая и элементарная форма RBMT-перевода - это прямой машинный перевод, или "перевод по словам": исходное предложение разбивается на слова, которые сравниваются с введенным словарем, осуществляется перевод по словам, который затем корректируется на основе морфологии и синтаксиса. Данный метод был отправной точкой машинного перевода, но в силу своих ограничений вскоре был заменен более совершенным трансферным машинным переводом, который позволил перейти от задания правил перевода каждого слова к возможности манипулирования более объемными синтаксическими конструкциями - перевод предваряет определение набора грамматических правил предложения на исходном языке и преобразование предложения в форму, совместимую с целевым языком.
Следующий этап в развитии RBMT - это так называемый "интерлингва-перевод" (или межъязыковый перевод) - метод, при котором осуществляется перевод с исходного языка на интерлингву, искусственный язык, разработанный для перевода слов и значений с одного языка на другой, впоследствии происходит перевод с интерлингвы на целевой язык.
Машинный перевод, основанный на правилах (RBMT), был первым шагом в решении задачи машинного перевода. Он относится к символьным методам в NLP, когда в фокусе было исследование синтаксического анализа на основе правил. Большинство исследований в данный период было посвящено обучению на ограниченных объемах данных. RBMT-перевод имел ограниченную точность, требовал наличия огромного числа правил, написанных вручную, основным недостатком метода являлось то, что не была решена проблема определения значения слова в зависимости от контекста. Наиболее популярным приложением того времени была система машинного перевода Systran, которая была разработана в 1968 году компанией Latsec.