Инспектор

Вы можете этот курс.
Опубликован: 05.04.2015 | Уровень: для всех | Доступ: платный | ВУЗ: Компания ALT Linux
Лекция 2:
Основные алгоритмы и их реализация на Python
2.5 Работа с ассоциативными массивами (таблицами данных)
Ассоциативный массив лучше всего описывается табличным представлением данных, когда каждая строка таблицы описывает характеристики какого-то объекта из множества однородных объектов (типичный пример — список учеников, их домашних телефонов и адресов). Таким образом, по значению из первого столбца такой таблицы (ключу) можно однозначно определить значения из остальных столбцов, т. е. значение ключа ассоциируется с остальными характеристиками объекта (в случае ученика — по фамилии можно найти другую информацию).
Если в ассоциативном массиве только два столбца ("ключ" и "значение"), то такой массив называется "хэш". Такие ассоциативные массивы очень часто используются в современных информационных системах (например, пары "логин—пароль").
В области моделирования процессов и явлений часто встречаются задачи, в которых значению "ключа" соответствует несколько параметров (например, номеру химического элемента однозначно соответствует название, атомный вес, валентность, количество протонов и пр.). В таких задачах простые хэш-массивы использовать уже неудобно.
Эффективный алгоритм обработки ассоциативных массивов (поиска значений, добавления и удаления значений и ключей, сортировки и пр.) в значительной степени зависит от используемого языка программирования и определённых в этом языке типов и структур данных. Так, в языке программирования Basic ассоциативный массив образуется из нескольких согласованных одномерных массивов. В языке программирования Pascal для представления ассоциативных массивов используется структура данных "запись" (record). В Python для ассоциативных массивов определена специальная структура данных — словарь, но мы рассмотрим работу с ассоциативными массивами с помощью списков и функций работы со списками.
Рассмотрим задачу из области экономического анализа.
Оценить экономическую деятельность нескольких предприятий. Известны названия предприятий, значения планового объёма розничного товарооборота и значения фактического объёма розничного товарооборота.
Требуется определить:
- процент выполнения плана каждым предприятием;
- количество предприятий, недовыполнивших план;
- наибольший плановый товарооборот;
- упорядочить предприятия по возрастанию планового товарооборота.
Обозначим количество предприятий как  и сформируем три списка — список названий предприятий (пусть он называется name), список значений планового товарооборота (назовём его plan), список значений фактического товарооборота (с именем fact). На основании этих данных создадим список значений процентов выполнения плана (пусть он называется procent).
и сформируем три списка — список названий предприятий (пусть он называется name), список значений планового товарооборота (назовём его plan), список значений фактического товарооборота (с именем fact). На основании этих данных создадим список значений процентов выполнения плана (пусть он называется procent).
Количество предприятий, недовыполнивших план, будем определять в результате сравнения процента выполнения со 100 процентами в цикле по всем предприятиям.
Текст программы на Python может выглядеть, как показано ниже.
# -*- coding: utf-8 -*-
#
# k - количество предприятий
# name - список названий предприятий
# plan - список значений планового товарооборота
# fact - список значений фактического товарооборота
# procent - список значений % выполнения плана
#
k=input("Количество предприятий: ")
name=[]
plan=[]
fact=[]
#
for i in range(k):
n=raw_input("Название: ")
name.append(n)
p1=input("План: ")
plan.append(p1)
p2=input("Факт: ")
fact.append(p2)
#
procent=map(lambda x, y:x*100/y, fact, plan)
fakt y=zip(name, procent)
plan y=zip(plan, name)
plany.sort()
print 16* "="
print "Процент выполнения плана каждым предприятием:"
#
nedo=0
for i in range(k):
s1=fakt y[i][0]
s2=fakt y[i][1]
if s2 < 100:
nedo=nedo+1
#
print s1,": ", s2
print "Количество предприятий, недовыполнивших план: ", nedo
print "Наибольший плановый товарооборот: ", max(plan)
#
print "Предприятия по возрастанию плана:"
for i in range(k):
s1=plan y[i][1]
s2=plan y[i][0]
print s1, ": ", s2
Здесь с помощью функции map() и "одноразовой" lambda-функции создаётся список процентов выполнения плана и с помощью функции zip() формируется два итоговых ассоциативных массива. Сортировка таких ассоциативных массивов производится "по первому столбику", поэтому важен порядок аргументов в функции zip(), а также порядок индексов при выводе результатов.
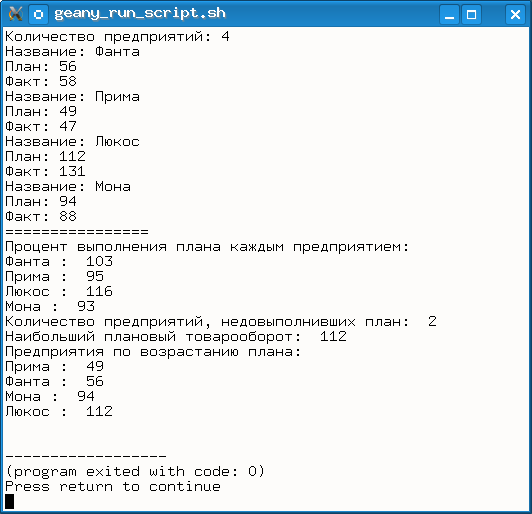
Пример решения задачи показан на рис. 2.16.
2.5.1 Задачи для самостоятельного решения
- Используя данные таблицы отсортировать блюда по возрастанию цены. Вывести отсортированный вариант списка блюд.
- Имеется список учеников и результаты трёх тестов (баллы от 0 до 100). Определить средний балл каждого ученика по трём тестам, вывести список учеников по убыванию среднего балла.
- Известны данные о количестве мальчиков и девочек в нескольких классах. Отсортировать названия классов по возрастанию процента мальчиков, определить количество классов, в которых мальчиков больше, чем девочек, и вывести названия этих классов отдельно.
- Решить задачу, связанную с оценкой экономической деятельности группы предприятий на основе известных данных:
- название предприятий;
- плановый объем розничного товарооборота;
- фактический объем розничного товарооборота.
- процент выполнения плана каждым предприятием;
- количество предприятий, недовыполнивших план на 10% и более;
- наименьший плановый товарооборот;
- упорядочить предприятия по убыванию планового товарооборота
Александр Кудлаев
|
Ознакомился с курсом "Практика по алгоритмизации и программированию на Python". Хотел сдать экзамен. Вместо традиционного тестирования было предложено написать курсовую работу. Написал. Отослал.Ответ на следующий день: "Задание не прверено". Сколько ожидать результата проверки работы? |