Опубликован: 22.08.2012 | Уровень: для всех | Доступ: свободно | ВУЗ: Московский государственный открытый университет им. В.С. Черномырдина
Лекция 11:
Интеллектуальные задачи в экономике
Обобщённо-регрессионная нейронная сеть
Обобщенно-регрессионная нейронная сеть (GRNN) устроена аналогично вероятностной нейронной сети (PNN), но она предназначена для решения задач регрессии, а не классификации (Speckt, 1991; Patterson, 1996; Bishop, 1995). Как и в случае PNN-сети, в точку расположения каждого обучающего наблюдения помещается гауссова ядерная функция. Считается, что каждое наблюдение свидетельствует о некоторой уверенности в том, что поверхность отклика в данной точке имеет определённую высоту, и эта уверенность убывает при отходе в сторону от точки. GRNN-сеть копирует внутрь себя все обучающие наблюдения и использует их для оценки отклика в произвольной точке. Окончательная выходная оценка сети получается как взвешенное среднее выходов по всем обучающим наблюдениям, где величины весов отражают расстояние от этих наблюдений до той точки, в которой производится оценивание (и, таким образом, более близкие точки вносят больший вклад в оценку).
Первый промежуточный слой сети GRNN состоит из радиальных элементов. Второй промежуточный слой содержит элементы, которые помогают оценить взвешенное среднее. Для этого используется специальная процедура. Каждый выход имеет в этом слое свой элемент, формирующий для него взвешенную сумму. Чтобы получить из взвешенной суммы взвешенное среднее, эту сумму нужно поделить на сумму весовых коэффициентов. Последнюю сумму вычисляет специальный элемент второго слоя. После этого в выходном слое производится собственно деление (с помощью специальных элементов "деления"). Таким образом, число элементов во втором промежуточном слое на единицу больше, чем в выходном слое. Как правило, в задачах регрессии требуется оценить одно выходное значение, и, соответственно, второй промежуточный слой содержит два элемента.
Можно модифицировать GRNN-сеть таким образом, чтобы радиальные элементы соответствовали не отдельным обучающим случаям, а их кластерам. Это уменьшает размеры сети и увеличивает скорость обучения. Центры для таких элементов можно выбирать с помощью любого предназначенного для этой цели алгоритма (выборки из выборки, K-средних или Кохонена), и программа ST Neural Networks соответствующим образом корректирует внутренние веса.
Достоинства и недостатки у сетей GRNN в основном такие же, как и у сетей PNN - единственное различие в том, что GRNN используются в задачах регрессии, а PNN - в задачах классификации. GRNN-сеть обучается почти мгновенно, но может получиться большой и медленной (хотя здесь, в отличие от PNN, не обязательно иметь по одному радиальному элементу на каждый обучающий пример, их число все равно будет большим). Как и сеть RBF, сеть GRNN не обладает способностью экстраполировать данные.
Линейная сеть
Согласно общепринятому в науке принципу, если более сложная модель не даёт лучших результатов, чем более простая, то из них следует предпочесть вторую. В терминах аппроксимации отображений самой простой моделью будет линейная, в которой подгоночная функция определяется гиперплоскостью. В задаче классификации гиперплоскость размещается таким образом, чтобы она разделяла собой два класса (линейная дискриминантная функция); в задаче регрессии гиперплоскость должна проходить через заданные точки. Линейная модель обычно записывается с помощью матрицы NxN и вектора смещения размера N.
На языке нейронных сетей линейная модель представляется сетью без промежуточных слоёв, которая в выходном слое содержит только линейные элементы (то есть элементы с линейной функцией активации). Веса соответствуют элементам матрицы, а пороги - компонентам вектора смещения. Во время работы сеть фактически умножает вектор входов на матрицу весов, а затем к полученному вектору прибавляет вектор смещения.
В пакете ST Neural Networks имеется возможность создать линейную сеть и обучить её с помощью стандартного алгоритма линейной оптимизации, основанного на псевдообратных матрицах (SVD) (Golub and Kahan, 1965). Разумеется, метод линейной оптимизации реализован также в модуле Множественная регрессия системы STATISTICA; однако, линейные сети пакета ST Neural Networks имеют то преимущество, что здесь возможно в единой среде сравнивать такие сети с "настоящими" нейронными сетями.
Линейная сеть является хорошей точкой отсчёта для оценки качества построенных нейронных сетей. Может оказаться так, что задачу, считавшуюся очень сложной, можно успешно решить не только нейронной сетью, но и простым линейным методом. Если же в задаче не так много обучающих данных, то, вероятно, просто нет оснований использовать более сложные модели.
Сеть Кохонена
Сети Кохонена принципиально отличаются от всех других типов сетей, реализованных в пакете ST Neural Networks. В то время как все остальные сети предназначены для задач с управляемым обучением, сети Кохонена главным образом рассчитаны на неуправляемое обучение (Kohonen, 1982; Haykin, 1994; Patterson, 1996; Fausett, 1994).
При управляемом обучении наблюдения, составляющие обучающие данные, вместе с входными переменными содержат также и соответствующие им выходные значения, и сеть должна восстановить отображение, переводящее первые во вторые. В случае же неуправляемого обучения обучающие данные содержат только значения входных переменных.
На первый взгляд это может показаться странным. Как сеть сможет чему-то научиться, не имея выходных значений? Ответ заключается в том, что сеть Кохонена учится понимать саму структуру данных.
Одно из возможных применений таких сетей - разведочный анализ данных. Сеть Кохонена может распознавать кластеры в данных, а также устанавливать близость классов. Таким образом, пользователь может улучшить свое понимание структуры данных, чтобы затем уточнить нейросетевую модель. Если в данных распознаны классы, то их можно обозначить, после чего сеть сможет решать задачи классификации. Сети Кохонена можно использовать и в тех задачах классификации, где классы уже заданы, - тогда преимущество будет в том, что сеть сможет выявить сходство между различными классами.
Другая возможная область применения - обнаружение новых явлений. Сеть Кохонена распознает кластеры в обучающих данных и относит все данные к тем или иным кластерам. Если после этого сеть встретится с набором данных, непохожим ни на один из известных образцов, то она не сможет классифицировать такой набор и тем самым выявит его новизну.
Сеть Кохонена имеет всего два слоя: входной и выходной, составленный из радиальных элементов (выходной слой называют также слоем топологической карты). Элементы топологической карты располагаются в некотором пространстве - как правило, двумерном (в пакете ST Neural Networks реализованы также одномерные сети Кохонена).
Обучается сеть Кохонена методом последовательных приближений. Начиная со случайным образом выбранного исходного расположения центров, алгоритм постепенно улучшает его так, чтобы улавливать кластеризацию обучающих данных. В некотором отношении эти действия похожи на алгоритмы выборки из выборки и K-средних, которые используются для размещения центров в сетях RBF и GRNN, и действительно, алгоритм Кохонена можно использовать для размещения центров в сетях этих типов. Однако данный алгоритм работает и на другом уровне.
Помимо того, что уже сказано, в результате итеративной процедуры обучения сеть организуется таким образом, что элементы, соответствующие центрам, расположенным близко друг от друга в пространстве входов, будут располагаться близко друг от друга и на топологической карте. Топологический слой сети можно представлять себе как двумерную решётку, которую нужно так отобразить в N-мерное пространство входов, чтобы по возможности сохранить исходную структуру данных. Конечно же, при любой попытке представить N-мерное пространство на плоскости будут потеряны многие детали; однако, такой приём иногда полезен, так как он позволяет пользователю визуализировать данные, которые никаким иным способом понять невозможно.
Основной итерационный алгоритм Кохонена последовательно проходит одну за другой ряд эпох, при этом на каждой эпохе он обрабатывает каждый из обучающих примеров, и затем применяет следующий алгоритм:
- Выбрать выигравший нейрон (то есть тот, который расположен ближе всего к входному примеру);
- Скорректировать выигравший нейрон так, чтобы он стал более похож на этот входной пример (взяв взвешенную сумму прежнего центра нейрона и обучающего примера).
В алгоритме при вычислении взвешенной суммы используется постепенно убывающий коэффициент скорости обучения, с тем чтобы на каждой новой эпохе коррекция становилась все более тонкой. В результате положение центра установится в некоторой позиции, которая удовлетворительным образом представляет те наблюдения, для которых данный нейрон оказался выигравшим.
Свойство топологической упорядоченности достигается в алгоритме с помощью дополнительного использования понятия окрестности. Окрестность - это несколько нейронов, окружающих выигравший нейрон. Подобно скорости обучения, размер окрестности убывает со временем, так что вначале к ней принадлежит довольно большое число нейронов (возможно, почти вся топологическая карта); на самых последних этапах окрестность становится нулевой (т.е. состоящей только из самого выигравшего нейрона). На самом деле в алгоритме Кохонена корректировка применяется не только к выигравшему нейрону, но и ко всем нейронам из его текущей окрестности.
Результатом такого изменения окрестностей является то, что изначально довольно большие участки сети "перетягиваются" - и притом заметно - в сторону обучающих примеров. Сеть формирует грубую структуру топологического порядка, при которой похожие наблюдения активируют группы близко лежащих нейронов на топологической карте. С каждой новой эпохой скорость обучения и размер окрестности уменьшаются, тем самым внутри участков карты выявляются всё более тонкие различия, что, в конце концов, приводит к тонкой настройке каждого нейрона. Часто обучение умышленно разбивают на две фазы: более короткую, с большой скоростью обучения и большими окрестностями, и более длинную, с малой скоростью обучения и нулевыми или почти нулевыми окрестностями.
После того, как сеть обучена распознаванию структуры данных, ее можно использовать как средство визуализации при анализе данных. С помощью данных, выводимых в окне "Частоты выигрышей" - Win Frequencies, (где для каждого нейрона подсчитывается, сколько раз он выигрывал при обработке обучающих примеров), можно определить, разбивается ли карта на отдельные кластеры. Можно также обрабатывать отдельные наблюдения и смотреть, как при этом меняется топологическая карта, - это позволяет понять, имеют ли кластеры какой-то содержательный смысл (как правило, при этом приходится возвращаться к содержательному смыслу задачи, чтобы установить, как соотносятся друг с другом кластеры наблюдений). После того, как кластеры выявлены, нейроны топологической карты помечаются содержательными по смыслу метками (в некоторых случаях помечены могут быть и отдельные наблюдения). После того, как топологическая карта в описанном здесь виде построена, на вход сети можно подавать новые наблюдения. Если выигравший при этом нейрон был ранее помечен именем класса, то сеть осуществляет классификацию. В противном случае считается, что сеть не приняла никакого решения.
При решении задач классификации в сетях Кохонена используется так называемый порог доступа. Ввиду того, что в такой сети уровень активации нейрона есть расстояние от него до входного примера, порог доступа играет роль максимального расстояния, на котором происходит распознавание. Если уровень активации выигравшего нейрона превышает это пороговое значение, то сеть считается не принявшей никакого решения. Поэтому, когда все нейроны помечены, а пороги установлены на нужном уровне, сеть Кохонена может служить как детектор новых явлений (она сообщает о непринятии решения только в том случае, если поданный ей на вход случай значительно отличается от всех радиальных элементов).
Идея сети Кохонена возникла по аналогии с некоторыми известными свойствами человеческого мозга. Кора головного мозга представляет собой большой плоский лист (площадью около 0.5 кв.м.; чтобы поместиться в черепе, она свернута складками) с известными топологическими свойствами (например, участок, ответственный за кисть руки, примыкает к участку, ответственному за движения всей руки, и таким образом все изображение человеческого тела непрерывно отображается на эту двумерную поверхность).
11.4. Генетические алгоритмы в экономике
Генетический алгоритм представляет собой метод, отражающий естественную эволюцию методов решения проблем, и в первую очередь задач оптимизации. Генетические алгоритмы - это процедуры поиска, основанные на механизмах естественного отбора и наследования. В них используется эволюционный принцип выживания наиболее приспособленных особей. Они отличаются от традиционных методов оптимизации несколькими базовыми элементами. В частности, генетические алгоритмы:
- Обрабатывают не значения параметров самой задачи, а их закодированную форму.
- Осуществляют поиск решения исходя не из единственной точки, а из их некоторой популяции.
- Используют только целевую функцию, а не её производные либо иную дополнительную информацию.
- Применяют вероятностные, а не детерминированные правила выбора.
Перечисленные четыре свойства, которые можно сформулировать также как кодирование параметров, операции на популяциях, использование минимума информации о задаче и рандомизация операций приводят в результате к устойчивости генетических алгоритмов и к их превосходству над другими широко применяемыми технологиями.
Основные понятия генетических алгоритмов
При описании генетических алгоритмов используются определения, заимствованные из генетики. Например, речь идет о популяции особей, а в качестве базовых понятий применяются ген, хромосома, генотип, фенотип, аллель. Также используются соответствующие этим терминам определения из технического лексикона, в частности, цепь, двоичная последовательность, структура.
Популяция - это конечное множество особей.
Особи, входящие в популяцию, в генетических алгоритмах представляются хромосомами с закодированным в них множествами параметров задачи, т.е. решений, которые иначе называются точками в пространстве поиска (search points). В некоторых работах особи называются организмами.
Хромосомы (другие названия - цепочки или кодовые последовательности) - это упорядоченные последовательности генов.
Ген (также называемый свойством, знаком или детектором) - это атомарный элемент генотипа, в частности, хромосомы.
Генотип или структура - это набор хромосом данной особи. Следовательно, особями популяции могут быть генотипы либо единичные хромосомы (в довольно распространённом случае, когда генотип состоит из одной хромосомы).
Фенотип - это набор значений, соответствующих данному генотипу, т.е. декодированная структура или множество параметров задачи (решение, точка пространства поиска).
Аллель - это значение конкретного гена, также определяемое как значение свойства или вариант свойства.
Локус или позиция указывает место размещения данного гена в хромосоме (цепочке). Множество позиций генов - это локи.
Очень важным понятием в генетических алгоритмах считается функция приспособленности {fitness function), иначе называемая функцией оценки. Она представляет меру приспособленности данной особи в популяции. Эта функция играет важнейшую роль, поскольку позволяет оценить степень приспособленности конкретных особей в популяции и выбрать из них наиболее приспособленные (т.е. имеющие наибольшие значения функции приспособленности) в соответствии с эволюционным принципом выживания "сильнейших" (лучше всего приспособившихся). Функция приспособленности также получила свое название непосредственно из генетики. Она оказывает сильное влияние на функционирование генетических алгоритмов и должна иметь точное и корректное определение. В задачах оптимизации функция приспособленности, как правило, оптимизируется (точнее говоря, максимизируется) и называется целевой функцией. В задачах минимизации целевая функция преобразуется, и проблема сводится к максимизации. В теории управления функция приспособленности может принимать вид функции погрешности, а в теории игр - стоимостной функции. На каждой итерации генетического алгоритма приспособленность каждой особи данной популяции оценивается при помощи функции приспособленности, и на этой основе создается следующая популяция особей, составляющих множество потенциальных решений проблемы, например, задачи оптимизации.
Очередная популяция в генетическом алгоритме называется поколением, а к вновь создаваемой популяции особей применяется термин "новое поколение" или "поколение потомков".
Классический генетический алгоритм
Основной (классический) генетический алгоритм (также называемый элементарным или простым генетическим алгоритмом) состоит из следующих шагов:
- инициализация, или выбор исходной популяции хромосом;
- оценка приспособленности хромосом в популяции;
- проверка условия остановки алгоритма;
- селекция хромосом;
- применение генетических операторов;
- формирование новой популяции;
- выбор "наилучшей" хромосомы.
Блок-схема основного генетического алгоритма изображена на рис.11.14.
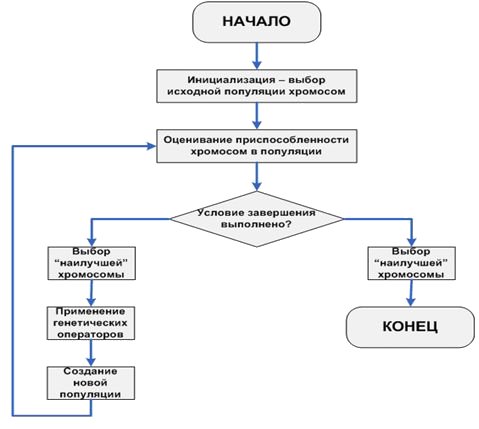
Инициализация, т.е. формирование исходной популяции, заключается в случайном выборе заданного количества хромосом (особей), представляемых двоичными последовательностями фиксированной длины.
Оценивание приспособленности хромосом в популяции состоит в расчёте функции приспособленности для каждой хромосомы этой популяции. Чем больше значение этой функции, тем выше "качество" хромосомы. Форма функции приспособленности зависит от характера решаемой задачи. Предполагается, что функция приспособленности всегда принимает неотрицательные значения и, кроме того, что для решения оптимизационной задачи требуется максимизировать эту функцию. Если исходная форма функции приспособленности не удовлетворяет этим условиям, то выполняется соответствующее преобразование (например, задачу минимизации функции можно легко свести к задаче максимизации).
Проверка условия остановки алгоритма. Определение условия остановки генетического алгоритма зависит от его конкретного применения. В оптимизационных задачах, если известно максимальное (или минимальное) значение функции приспособленности, то остановка алгоритма может произойти после достижения ожидаемого оптимального значения, возможно - с заданной точностью. Остановка алгоритма также может произойти в случае, когда его выполнение не приводит к улучшению уже достигнутого значения. Алгоритм может быть остановлен по истечении определённого времени выполнения либо после выполнения заданного количества итераций. Если условие остановки выполнено, то производится переход к завершающему этапу выбора "наилучшей" хромосомы. В противном случае на следующем шаге выполняется селекция.
Селекция хромосом заключается в выборе (по рассчитанным на втором этапе значениям функции приспособленности) тех хромосом, которые будут участвовать в создании потомков для следующей популяции, т.е. для очередного поколения. Такой выбор производится согласно принципу естественного отбора, по которому наибольшие шансы на участие в создании новых особей имеют хромосомы с наибольшими значениями функции приспособленности. Существуют различные методы селекции. Наиболее популярным считается так называемый метод рулетки (roulette wheel selection), который свое название получил по аналогии с известной азартной игрой. Каждой хромосоме может быть сопоставлен сектор колеса рулетки, величина которого устанавливается пропорциональной значению функции приспособленности данной хромосомы. Поэтому чем больше значение функции приспособленности, тем больше сектор на колесе рулетки. Все колесо рулетки соответствует сумме значений функции приспособленности всех хромосом рассматриваемой популяции. Каждой хромосоме, обозначаемой 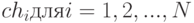 (где N обозначает численность популяции) соответствует сектор колеса v(chi), выраженный в процентах согласно формуле
(где N обозначает численность популяции) соответствует сектор колеса v(chi), выраженный в процентах согласно формуле
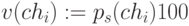
где
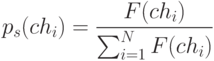
причём 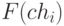 - значение функции приспособленности хромосомы chi, a ps(chi) -вероятность селекции хромосомы chi. Селекция хромосомы может быть представлена как результат поворота колеса рулетки, поскольку "выигравшая" (т.е. выбранная) хромосома относится к выпавшему сектору этого колеса. Очевидно, что чем больше сектор, тем больше вероятность "победы" соответствующей хромосомы. Поэтому вероятность выбора данной хромосомы оказывается пропорциональной значению её функции приспособленности. Если всю окружность колеса рулетки представить в виде цифрового интервала [0, 100], то выбор хромосомы можно отождествить с выбором числа из интервала [а, b], где а и b обозначают, соответственно, начало и окончание фрагмента окружности, соответствующего этому сектору колеса; очевидно, что
- значение функции приспособленности хромосомы chi, a ps(chi) -вероятность селекции хромосомы chi. Селекция хромосомы может быть представлена как результат поворота колеса рулетки, поскольку "выигравшая" (т.е. выбранная) хромосома относится к выпавшему сектору этого колеса. Очевидно, что чем больше сектор, тем больше вероятность "победы" соответствующей хромосомы. Поэтому вероятность выбора данной хромосомы оказывается пропорциональной значению её функции приспособленности. Если всю окружность колеса рулетки представить в виде цифрового интервала [0, 100], то выбор хромосомы можно отождествить с выбором числа из интервала [а, b], где а и b обозначают, соответственно, начало и окончание фрагмента окружности, соответствующего этому сектору колеса; очевидно, что 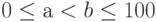 . В этом случае выбор с помощью колеса рулетки сводится к выбору числа из интервала [0, 100], которое соответствует конкретной точке на окружности колеса.
. В этом случае выбор с помощью колеса рулетки сводится к выбору числа из интервала [0, 100], которое соответствует конкретной точке на окружности колеса.
В результате процесса селекции создается родительская популяция, также называемая родительским пулом (mating pool) с численностью N, равной численности текущей популяции.
Применение генетических операторов к хромосомам, отобранным с помощью селекции, приводит к формированию новой популяции потомков от созданной на предыдущем шаге родительской популяции.
В классическом генетическом алгоритме применяются два основных генетических оператора: оператор скрещивания (crossover) и оператор мутации (mutation). Однако следует отметить, что оператор мутации играет явно второстепенную роль по сравнению с оператором скрещивания. Это означает, что скрещивание в классическом генетическом алгоритме производится практически всегда, тогда как мутация - достаточно редко. Вероятность скрещивания, как правило, достаточно велика (обычно 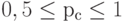 ), тогда как вероятность мутации устанавливается весьма малой (чаще всего
), тогда как вероятность мутации устанавливается весьма малой (чаще всего 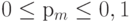 ). Это следует из аналогии с миром живых организмов, где мутации происходят чрезвычайно редко.
). Это следует из аналогии с миром живых организмов, где мутации происходят чрезвычайно редко.
В генетическом алгоритме мутация хромосом может выполняться на популяции родителей перед скрещиванием либо на популяции потомков, образованных в результате скрещивания.
Виталий Елин
|
Здравствуйте! Здесь вначале говориться что выдается диплом, а внизу страницы сказано что нет |
{kind=link}
{kind=link}