|
Хотелось бы иметь возможность читать текст сносок при использовании режима "Версия для печати" |
Опубликован: 10.10.2005 | Уровень: специалист | Доступ: свободно | ВУЗ: Московский физико-технический институт
Лекция 2:
Введение в реляционную модель данных
Отсутствие упорядоченности атрибутов
Атрибуты отношений не упорядочены, поскольку по определению заголовок отношения есть множество пар <имя атрибута, имя домена> . Для ссылки на значение атрибута в кортеже отношения всегда используется имя атрибута. Легко заметить явную аналогию между заголовками отношений и структурными типами в языках программирования. Даже в языке программирования C с его практически неограниченными возможностями работы с указателями настойчиво рекомендуется обращаться к полям структур только по их именам. Если, например, на языке C определена структурная переменная
struct {int a; char b; int c} d;
то в стандарте языка решительно не рекомендуется использовать для доступа к символьному полю b конструкцию *(&d + sizeof(int)) (взять адрес структурной переменной d, прибавить к нему число байтов в целом числе и взять значение байта по полученному адресу). Это объясняется тем, что при реальном расположении в памяти полей такой структурной переменной в том порядке, как они определены, во многих компьютерах потребуется выровнять поле c по байту с четным адресом. Поэтому один байт просто пропадет. При расположении структурной переменной в памяти экономный компилятор (вернее, оптимизатор) переставит местами поля b и c, и указанная выше конструкция не обеспечит доступа к полю b. Для корректного обращения к полю b переменной d нужно использовать конструкции d.b или &d->b, т. е. явно указывать имя поля.
Аналогичными практическими соображениями оправдывается и отсутствие упорядоченности атрибутов в заголовке отношения. В этом случае СУБД сама принимает решение о том, в каком физическом порядке следует хранить значения атрибутов кортежей (хотя обычно один и тот же физический порядок поддерживается для всех кортежей каждого отношения ). Кроме того, это свойство облегчает выполнение операции модификации схем существующих отношений не только путем добавления новых атрибутов, но и путем удаления существующих.
Снова забегая вперед, заметим, что в языке SQL в некоторых случаях допускается индексное указание атрибутов, причем в качестве неявного порядка атрибутов используется их порядок в линейной форме определения схемы отношения (это одна из осуждаемых особенностей языка SQL).
Атомарность значений атрибутов, первая нормальная форма отношения
Значения всех атрибутов являются атомарными (вернее, скалярными). Это следует из определения домена как потенциального множества значений скалярного типа данных, т. е. среди значений домена не могут содержаться значения с видимой структурой, в том числе множества значений ( отношения ). Заметим, что это не противоречит тому, что говорилось в разделе "Основные понятия реляционных баз данных" о потенциальной возможности использования при спецификации атрибутов типов данных, определяемых пользователями. Например, можно было бы добавить в схему отношения СЛУЖАЩИЕ атрибут СЛУ_ФОТО, определенный на домене (или типе данных ) ФОТОГРАФИИ. Главное в атомарности значений атрибутов состоит в том, что реляционная СУБД не должна обеспечивать пользователям явной видимости внутренней структуры значения. Со всеми значениями можно обращаться только с помощью операций, определенных в соответствующем типе данных.
Принято говорить, что в реляционных базах данных допускаются только нормализованные отношения, или отношения, представленные в первой нормальной форме.
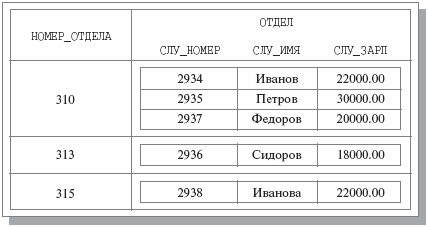
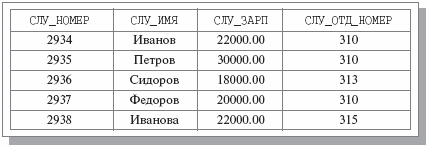
Пример ненормализованного отношения показан на рис. 2.2. Можно сказать, что здесь мы имеем бинарное отношение, в котором значениями атрибута ОТДЕЛЫ являются отношения. Заметим, что исходное отношение СЛУЖАЩИЕ является нормализованным вариантом отношения ОТДЕЛЫ-СЛУЖАЩИЕ. Нормализованный вариант показан на рис. 2.3.
Нормализованные отношения составляют основу классического реляционного подхода к организации баз данных. Они обладают некоторыми ограничениями6Эти ограничения все более ослабляются в последовательности стандартов языка SQL. (не всякую информацию удобно представлять в виде плоских таблиц), но существенно упрощают манипулирование данными. Рассмотрим, например, два идентичных оператора занесения кортежа:
- зачислить служащего Кузнецова (пропуск номер 3000, зарплата 25000.00) в отдел номер 320;
- зачислить служащего Кузнецова (пропуск номер 3000, зарплата 25000.00) в отдел номер 310.
Если информация о служащих представлена в виде отношения СЛУЖАЩИЕ, оба оператора будут выполняться одинаково (вставить кортеж в отношение СЛУЖАЩИЕ ). Если же работать с ненормализованным отношением ОТДЕЛЫ-СЛУЖАЩИЕ, то первый оператор приведет к простой вставке кортежа, а второй – к добавлению кортежа в значение- отношение атрибута ОТДЕЛ кортежа с первичным ключом 310.
При работе с ненормализованными отношениями аналогичные затруднения возникают при выполнении операций удаления и модификации кортежей.