Простейшие оптимизации программ
Презентацию к лекции Вы можете скачать здесь.

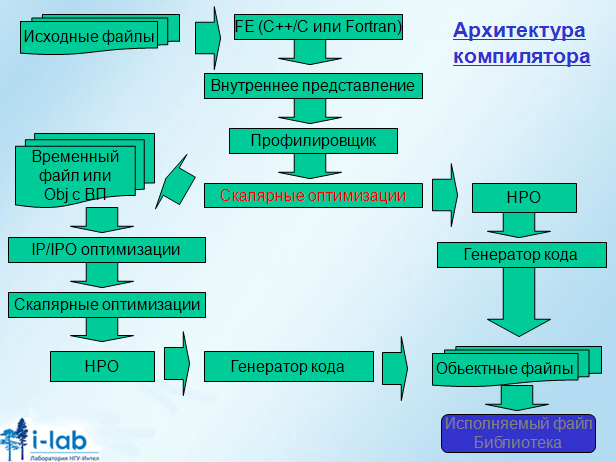
Начнем разговор о архитектуре компилятора с разговора о FE и о внутреннем представлении компилируемой программы.
Front End

Синтаксический анализ (parsing) — это процесс анализа входной последовательности символов, с целью разбора грамматической структуры, обычно в соответствии с заданной формальной грамматикой.
При этом исходный текст преобразуется в структуру данных, обычно — в дерево, которое отражает синтаксическую структуру входной последовательности и хорошо подходит для дальнейшей обработки.
Обычно синтаксический анализ делится на два уровня:
- Лексический анализ — входной поток символов разбивается на линейную последовательность токенов — "слов" языка (напр. целые числа, идентификаторы, строковые константы и т. д.);
- Семантический анализ — из токенов выделяются "предложения" языка, согласно грамматическим правилам, и создается дерево разбора
На выходе FE мы получаем взаимосвязанные таблицы, которые называются внутренним представлением программы. Обычной практикой является использование общего внутреннего представления для разных языков высокого уровня
В современном оптимизирующем компиляторе фронт-енды составляют малую часть от всей функциональности компилятора. В данном случае разные языковые конструкции (С,С++,Fortran) переводятся в общее внутреннее представление.
Зависимости (Dependence)
Вычисления являются эквивалентными, если на одинаковых данных они вычисляют одинаковые значения для выходных переменных и сохраняется порядок вывода результатов.
Это определение позволяет использовать для вычисления различные последовательности инструкций (некоторые из которых могут быть более эффективными, чем другие).
Какие особенности утверждений могут привести к изменению результата в процессе вычисления?
Мы рассмотрели примеры некоторых базовых цикловых оптимизаций. Чтобы понять область их применения обсудим зависимости и что подразумевается под допустимыми оптимизациями.
Скалярные оптимизации
Свертка констант, протяжка констант, протяжка копий (Constant folding, constant propagation, copy propagation)
Свертка констант - процесс вычисления констант во время компиляции.
Протяжка констант – подстановка величин известных констант в выражение
int x = 14;
int y = 7 - x / 2;
=> constant propagation =>
int x = 14;
int y = 7 – 14 / 2;
Протяжка копий – процесс замены переменных их значениями
y = x;
z = 3 + y
=> copy propagation =>
z = 3 + x
Скалярные оптимизации
Удаление повторных вычислений (Common subexpression elimination) – поиск идентичных подвыражений и сохранение результата вычисления во временной переменной для последующего повторного использования.
a = b * c + g;
d = b * c * d;
=> CSE =>
tmp = b * c;
a = tmp + g;
d = tmp * d;
Скалярные оптимизации
Удаление мертвого кода (Dead code elimination) это удаление кода, который не изменяет выходных данных программы. К мертвому коду относится код, который никогда не выполняется или изменяет только не влияющие на результат переменные.
int foo() {
int a = 24;
int b = 25; /* Присвоение не влияющей на результат переменной */
int c;
c = a << 2;
return c;
b = 24; /* Недостижимый код */ }
Мертвый код может появиться после многих оптимизаций компилятора, после протяжки констант и копий, после прямой подстановки (inlining) и т.п.
Скалярные оптимизации
Удаление излишнего ветвления, протяжка условий
Удаляются блоки кода, которые не могут быть достижимы из-за цепочки условных ветвлений.
if(x>0) {
…
if(x>0) { a=x; }
else { a=-x; }
…
}
=>
if(x>0) {
…
a=x;
…
}
Также может возникнуть из-за скалярных оптимизаций или прямой подстановки.
Анализ потоков данных (Data Flow Analysis)
Сбор информации о возможном наборе значений переменных вычисляемых в различных точках программы. Граф потока управления (CFG) используется для определения тех частей программы, в которые может быть передано некоторое значение, присвоенное переменной.
Граф определения/использования (definition-use graph) – это граф, который содержит дуги из каждой точки определения переменной в программе к каждой точке ее использования.
Скалярные оптимизации базируются на анализе потоков данных. Анализ потоков данных работает с графом потока управления. Действительно, все сложности с анализом данных появляются из-за различных ветвлений управления, циклов и переходов. В непрерывном коде (именно непрерывные части кода и являются телами базовых блоков CFG) задача анализа потока данных очень проста.
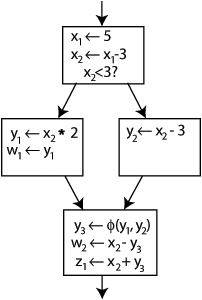
SSA-форма
SSA форма не позволяет создавать сложные цепочки зависимостей для переменных. Сила SSA заключается в том, что каждая переменная имеет только одно определение внутри программы. Поэтому любая зависимость очевидна. SSA представление вводит специальные Phi-функции в местах, в местах ветвления или условных операторов (например, if). Это так называемые псевдо-присваивания.
При построении необходимо расставить Phi – функции и породить новые уникальные переменные.
Новые переменные порождаются путем добавления к имени переменной уникального варианта.
SSA-форма может использоваться не только разработчиком при создании программы, но и компилятором в процессе её оптимизации.
Любая программа на императивном языке программирования может быть приведена к SSA-форме