Архитектура микропроцессора Intel и основные факторы, влияющие на его производительность
Презентацию к лекции Вы можете скачать здесь.

Дополнительная информация:
Прототипом схемы служит отчасти описание архитектуры фон Неймана, которая имеет следующие принципы:
- Принцип двоичности
- Принцип программного управления
- Принцип однородности памяти
- Принцип адресуемости памяти
- Принцип последовательного программного управления
- Принцип условного перехода
Чтобы легче было понять, что из себя представляет современная вычислительная система, надо рассматривать ее в развитии. Поэтому я здесь привел самую простую схему, которая приходит в голову. По сути дела, эта упрощенная модель. У нас существует некое устройство управления внутри процессора, арифметико-логическое устройство, системные регистры, системная шина, которая позволяет вести обмен между устройством управления и другими устройствами, память и периферийные устройства. Устройство управления получает инструкции, делает их дешифрацию, управляет арифметико-логическим устройством, осуществляет пересылку данных между регистрами процессора, памятью, периферийными устройствами.
Упрощенная модель процессора
- устройство управления (Control Unit, CU)
- арифметико-логическое устройство (Arithmetic and Logic Unit, ALU)
- системные регистры
- системная шина (Front Side Bus, FSB)
- память
- периферийные устройства
Устройство управления (CU):
- выполняет дешифрацию инструкций, поступающих из памяти компьютера.
- управляет ALU.
- осуществляет пересылку данных между регистрами ЦП, памятью, периферийными устройствами.
Арифметико-логическое устройство:
- позволяет производить арифметические и логические операции над системными регистрами.
Системные регистры:
- определенный участок памяти внутри ЦП, используемый для промежуточного хранения информации, обрабатываемой процессором.
Системная шина:
- используется для пересылки данных между ЦП и памятью, а также между ЦП и периферийными устройствами.
Арифметико-логическое устройство состоит из различных электронных компонент, позволяющих производить операции над системными регистрами. Системные регистры – это некие участки в памяти, внутри центрального процессора, используемые для хранения промежуточных результатов, обрабатываемых процессором. Системная шина используется для пересылки данных между центральным процессором и памятью, а также между центральным процессором и периферийными устройствами.
Высокая производительность МП (микропроцессора)– один из ключевых факторов в конкурентной борьбе производителей процессоров.
Производительность процессора напрямую связана с количеством работы, вычислений, которые он может выполнить за единицу времени.
Очень условно:
Производительность = Кол-во инструкций / Время
Мы будем рассматривать производительность процессоров на базе архитектур IA32 и IA32e. (IA32 with EM64T).
Факторы влияющие на производительность процессора:
- Тактовая частота процессора.
- Объем адресуемой памяти и скорость доступа к внешней памяти.
- Скорость выполнения и набор инструкций.
- Использование внутренней памяти, регистров.
- Качество конвейеризации.
- Качество предсказания переходов.
- Качество упреждающей выборки.
- Суперскалярность.
- Наличие векторных инструкций.
- Многоядерность.
Что такое производительность? Сложно дать однозначное определение производительности. Можно формально привязать его к процессору – сколько, инструкций за единицу времени может выполнять тот или иной процессор. Но проще дать сравнительное определение – взять два процессора и тот, который выполняет некий набор инструкций быстрее, тот более производительный. То есть, очень условно, можно сказать, что производительность – это количество инструкций на время выполнения. Мы здесь в основном будем исследовать те микропроцессорные архитектуры, которые выпускает Intel, то есть архитектуры IA32, которые сейчас называются Intel 64. Это архитектуры, которые с одной стороны поддерживает старые инструкции из набора IA32, с другой стороны имеют EM64T – это некое расширение, которое позволяет использовать 64 битные адреса, т.е. адресовать большие размеры памяти , а также включает в себя какие-то полезные дополнения, типа увеличенного количества системных регистров, увеличенное количество векторных регистров.
Какие факторы влияют на производительность? Перечислим все, которые приходят в голову. Это:
- Скорость выполнения инструкций, полнота базового набора инструкций.
- Использование внутренней памяти регистров.
- Качество конвейеризации.
- Качество предсказания переходов.
- Качество упреждающей выборки.
- Суперскалярность.
- Векторизация, использование векторных инструкций.
- Параллелизация и многоядерность.
Тактовая частота
Процессор состоит из компонент, срабатывающих в разное время и в нем существует таймер, который обеспечивает синхронизацию, посылая периодические импульсы. Его частота и называется тактовой частотой процессора.
Объем адресуемой памяти
Тактовая частота.
Поскольку процессор имеет много различных электронных компонент, которые работают независимо, то для того, чтобы синхронизировать их работу, чтобы они знали, в какой момент надо начать работать, когда нужно выполнить свою работу и ждать, существует таймер, который посылает синхроимпульс. Частота, с которой посылается синхроимпульс – и есть тактовая частота процессора. Есть устройства, которые успевают две операции выполнить за это время, тем не менее, к этому синхроимпульсу работа процессора привязана, и, можно сказать, что если мы эту частоту увеличим, то мы заставим все эти микросхемы работать с большим напряжением сил и меньше простаивать.
Объем адресуемой памяти и скорость доступа к памяти.
Объем памяти - необходимо, чтобы памяти хватало для нашей программы и наших данных. То есть, технология EM64T позволяет адресовать огромное количество памяти и на данный момент вопрос с тем, что нам не хватает адресуемой памяти не стоит.
Поскольку на эти факторы разработчики в общем случае не имеют возможности влиять, то я только упоминаю о них.
Скорость выполнения и набор инструкций
Производительность зависит от того, насколько качественно реализованы инструкции, насколько полно базовый набор инструкций покрывает все возможные задачи.
CISC,RISC (complex, reduced instruction set computing)
Современные процессоры Intel® представляют собой гибрид CISC и RISC процессоров, перед исполнением преобразуют CISC инструкции в более простой набор RISC инструкций.
Скорость выполнения инструкций и полнота базового набора инструкций.
По сути дела, когда архитекторы проектируют процессоры, они постоянно работают с целью улучшить его производительность. Одной из их задач является сбор статистики, для определения , какие инструкции или последовательности инструкций являются ключевыми с точки зрения производительности. Пытаясь улучшить производительность, архитекторы пытаются самые горячие инструкции сделать быстрее, для каких-то наборов инструкций сделать специальную инструкцию, которая заменит этот набор и будет работать эффективнее. От архитектуры к архитектуре изменяются характеристики инструкций, появляются новые инструкции, которые позволяют добиться лучшей производительности. Т.е. можно считать что от архитектуры к архитектуре базовый набор инструкций постоянно совершенствуется и расширяется. Но если вы не указываете на каких архитектурах будет выполняться ваша программа, то в вашем приложении будет задействован некий умолчательный набор инструкций, который поддерживают все последние микропроцессоры. Т.е. наилучшей производительности мы можем добиться только если будем четко специфицировать тот микропроцессор, на котором будет выполняться задача.
Использование регистров и оперативной памяти
Время доступа к регистрам наименьшее, поэтому кол-во доступных регистров влияет на производительность микропроцессора.
Вытеснение регистров (register spilling) – из-за недостаточного кол-ва регистров велик обмен между регистрами и стеком приложения.
С ростом производительности процессоров возникла проблема, связанная с тем, что скорость доступа к внешней памяти стала ниже скорости вычислений.
Существуют две характеристики для описания свойств памяти:
- Время отклика (latency) – число циклов процессора необходимых для передачи единицы данных из памяти.
- Пропускная способность (bandwidth) – количество элементов данных которые могут быть отправлены процессору из памяти за один цикл.
Две возможные стратегии для ускорения быстродействия– уменьшение времени отклика или упреждающий запрос нужной памяти.
Использование регистров и оперативной памяти.
Регистры – самые быстрые элементы памяти, они находятся непосредственно на ядре, и доступ к ним практически мгновенный. Если ваша программа делает какие-то вычисления, хотелось бы, чтобы все промежуточные данные хранились на регистрах. Понятно, что это невозможно. Одна из возможных проблем производительности– это проблема вытеснения регистров. Когда вы под каким-нибудь анализатором производительности смотрите на ассемблерный код, вы видите, что у вас очень много движения со стека в регистры и обратно выгрузка регистров на стек. Стоит вопрос – как оптимизировать код так, чтобы самые горячие адреса, самые горячие промежуточные данные, лежали именно на системных регистрах.
Следующая часть памяти – это обычная оперативная память. С ростом производительности процессоров стало ясно, что самым узким местом производительности является доступ к оперативной памяти. Для того, чтобы добраться до оперативной памяти, нужны сотня, а то и две сотни тактов процессора. То есть, запросив какую-то ячейку памяти в оперативной памяти, мы будем ждать двести тактов, а процессор будет простаивать.
Существует две характеристики для описания свойств памяти – это время отклика, то есть число циклов процессора, необходимое для передачи единицы данных из памяти, и пропускная способность — сколько элементов данных могут быть отправлены процессором из памяти за один цикл. Встретившись с проблемой, что у нас узким местом является доступ к памяти, мы можем решать эту проблему двумя путями – либо уменьшением времени отклика, либо делать упреждающие запросы нужной памяти. То есть, в данный момент нам значение какой-то переменной неинтересно, но мы знаем, что оно скоро нам понадобится, и мы его уже запрашиваем.
Кэширование
Кэш-память служит для уменьшения времени доступа к данным.
Для этого блоки оперативной памяти отображаются в более быструю кэш-память.
Если адрес памяти находится в кэше – происходит "попадание" и скорость получения данных значительно увеличивается.
В противном случае – "промах" (cache miss)
В этом случае блок оперативной памяти считывается в кэш-память за один или несколько циклов шины, называемых заполнением строки кэш-памяти.
Можно выделить следующие виды кэш-памяти:
- полностью ассоциативная кэш-память (каждый блок может отображаться в любое место кэша)
- память с прямым отображением (каждый блок может отображаться в одно место)
- гибридные варианты (секторная память, память с множественно-ассоциативным доступом)
Множественно-ассоциативный доступ – по младшим разрядам определяется строка кэша, куда может отображаться данная память, но в этой строке может находиться только несколько слов основной памяти, выбор из которых проводится на ассоциативной основе.
Качество использования кэша – ключевое условие быстродействия.
Уменьшение времени доступа было достигнуто введением кэш-памяти. Кэш-память – это буферная память, находящаяся между оперативной памятью и микропроцессором. Она реализована на ядре, то есть доступ к ней гораздо быстрее чем к обычной памяти, но она намного дороже, поэтому при разработке микроархитектуры нужно найти точный баланс между ценой и производительностью. Если вы посмотрите на описания предлагаемых в продаже процессоров, вы увидите, что всегда в описании пишется, сколько кэша памяти того или иного уровня на данном процессоре есть. Эта цифра серьезно влияет на цену данного изделия. Кэш-память устроена так, что обычная память отображается на кэш-память, отображение идет блоками. Вы, запрашивая в оперативной памяти какой-то адрес, делаете проверку, отображен ли этот адрес в кэш-памяти. Если этот адрес уже есть в кэш-памяти, то вы экономите время на обращение к памяти. Вы считываете эту информацию из быстрой памяти, и у вас время отклика существенно уменьшается, если же этого адреса в кэш-памяти нет, то мы должны обратиться к обычной памяти, чтобы этот необходимый нам адрес вместе с каким-то блоком, в котором он находится, отобразился в эту кэш-память.
Существуют разные реализации кэш-памяти. Бывает полностью ассоциативная кэш-память, когда каждый блок может отображаться в любое место кэша. Существует память с прямым отображением, когда каждый блок может отображаться в одно место, также существуют различные гибридные варианты – например кэш с множественно-ассоциативным доступом. В чем разница? Разница во времени и сложности проверки на наличие нужного адреса в кэш-памяти. Предположим, что нам нужен определенный адрес. В случае с ассоциативной памятью нам нужно проверить весь кэш – убедиться, что этого адреса в кэше нет. В случае с прямым отображением нам нужно проверить только одну ячейку. В случае с гибридными вариантами, например, когда используется кэш с множественно-ассоциативным доступом, нам нужно проверить, к примеру, четыре или восемь ячеек. То есть, задача определить есть ли адрес кэша – тоже важна. Качество использования кэша – важное условие быстродействия. Если нам удастся написать программу так, чтобы как можно чаще те данные, с которыми мы собирались работать, находились в кэше, то такая программа будет работать гораздо быстрее.
Характерные времена отклика при обращении к кэш памяти для Nehalem i7:
Время отклика для оперативной памяти > 100
Упреждающий механизм доступа к памяти реализован при помощи механизма упреждающей выборки (hardware prefetching).
Есть специальный набор инструкций, позволяющий побудить процессор загрузить в кэш память расположенную по определенному адресу (software prefetching).
Для примера возьмем наш последний процессор Nehalem: i7.
Здесь мы имеем не просто кэш, а некий иерархический кэш. Долгое время он был двухуровневый, в современной системе Nehalem он трехуровневый – совсем немного очень быстрого кэша, чуть побольше кэша второго уровня и достаточно большое количество кэша третьего уровня. При этом, эта система построена так, что если какой-то адрес находится в кэше первого уровня, он автоматически находится во втором и в третьем уровнях. Это и есть иерархическая система. Для кэша первого уровня задержка – 4 такта, для второго – 11, третьего – 38 и время отклика оперативной памяти – больше 100 тактов процессора.
Принцип локальности. Качество упреждающей выборки.
Локальность ссылки (locality of reference) – повторное использование переменных или взаимосвязанных данных. Различают временную локальность (temporal locality) – когда речь идет об одних и тех же данных и пространственную локальность (spatial locality) – использование различных данных, имеющих относительно близкие области хранения.
Механизм кэширования использует принцип временной локальности. (Стремится сохранять в кэше наиболее часто используемые данные).
Механизм упреждающей выборки использует принцип пространственной локальности. (Стремится определить закономерность в доступе к памяти, чтобы заранее подгружать в кэш необходимую память). При этом, чем выше пространственная локальность (элементы расположены ближе в памяти), тем меньше данных требуется загружать в кэш и меньше нагрузка на системную шину.
Кэш aliasing – из-за неудачного расположения в памяти различных объектов, участвующих в вычислении, происходит вытеснению из кэш памяти одних адресов другими.
Второй вариант улучшения быстродействия и работы с памятью, про который мы упомянули – это подкладывать в кэш заранее необходимые адреса – упреждающий механизм доступа к памяти (Hardware Prefetching). Этот механизм выявляет закономерности, с которыми вы обращаетесь к памяти, и заранее закачивает в кэш адреса, которые могут вам понадобиться. Если вы обрабатываете несколько массивов, движетесь по ним последовательно или с каким-то постоянным шагом, то, скорее всего, этот механизм начнет эти адреса заранее подгружать. Есть специальный набор инструкций, позволяющий загрузить в кэш память, расположенную по определенному адресу. (Software Prefetching)
Кэш имеет внутренние алгоритмы работы. Введем несколько понятий.
Локальность ссылки – переиспользование переменных или взаимосвязанных данных. Различают временную локальность – переиспользование определенных данных и ресурсов и пространственную локальность - использование данных, имеющих относительно близкие области хранения.
Механизм кэширования использует механизм временной локальности. Он пытается отследить те адреса, которые чаще всего используются, и сохранять их в кэше, а те, которые больше не используются – из кэша удалять. То есть каждый раз, когда вы запрашиваете из памяти какой-то новый адрес, механизм кэширования оценивает, какие блоки у него есть, какой из имеющихся у него блоков давно не использовался, и удаляет этот блок, заменяя его на новый. Этот механизм пытается сохранять только те данные, с которыми ведется активная работа.
Механизм упреждающей выборки использует принцип пространственной локальности, то есть подгружает соседние элементы.
При работе механизма кэширования могут происходить неприятные моменты. Например, вы работаете с двумя массивами, но они расположены в памяти так, что взяв адреса одного массива, которые вам нужны, вы вытесняете из кэша адреса другого массива, которые будут вам нужны. Формально, ничего не мешает расположить эти массивы в памяти по-другому и избежать этой проблемы.
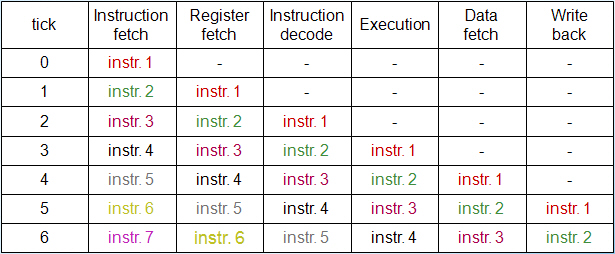
Обычно подобную картинку приводят, чтобы иллюстрировать работу конвейера.
Качество конвейеризации, уровень параллелизма инструкций
Конвейеризация предполагает, что последовательные инструкции будут перекрываться при выполнении.
Выполнение типичной команды можно разделить на следующие этапы:
- выборка команды – IF;
- декодирование команды / выборка операндов из регистров - ID;
- выполнение операции / вычисление эффективного адреса памяти - EX;
- обращение к памяти - MEM;
- запоминание результата - WB.
Конвейеризация улучшает пропускную способность процессора, но если инструкции зависят от результатов выполнения предыдущих инструкций, то возникают задержки. Таким образом, польза от конвейеризации определяется уровнем инструкционного параллелизма.
Качество конвейеризации.
Было время, когда процессор выполнял одновременно одну инструкцию. После введения конвейеризации процесс обработки инструкции разбит на несколько этапов. Один из вариантов, который широко используется, приведен:
| выборка команды; |
| декодирования команды; |
| выполнение операции; |
| обращение к памяти; |
| запоминание результатов. |
Использование конвейера позволяет процессору одновременно обрабатывать несколько инструкций. Это невозможно в случае если инструкция зависит от результатов другой, поэтому чем больше у вас независимых инструкций, тем лучше работает конвейер. Если у вас все инструкции не зависят от результатов предыдущих, то он должен работать оптимально.