Использование инструментов Intel® для оптимизации программ

Просмотр по вычислительным потокам
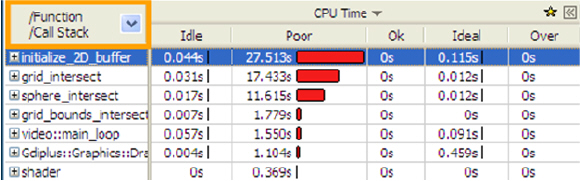

- 1 – время
- 2 – вычислительные потоки
- 3 – использование процессора
Исходный код

- 1 – код программы, 2 – ассемблерный код,
- 3 – процессорное время,
- 4 и 5 – элементы навигации для быстрого перемещения по горячим строкам кода
Сравнение результатов
Для определения выигрыша, вызванного оптимизациями удобно воспользоваться функцией сравнения
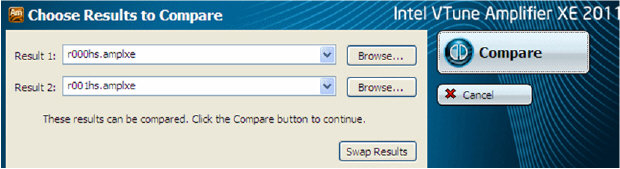
Сравнение результатов

- 1 – различие во времени между версиями
- 2 – время до оптимизаций
- 3 – время после оптимизаций
Оценка эффективности использования вычислительных ресурсов
Аналогичным образом можно произвести другие виды анализа, например, locks and waits
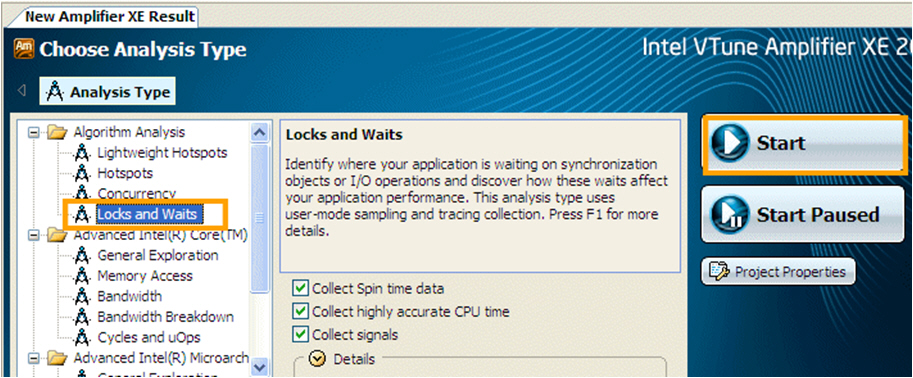
Осуществление анализа
После выполнения анализа вам также будет представлена краткая информация, но уже по другому аспекту
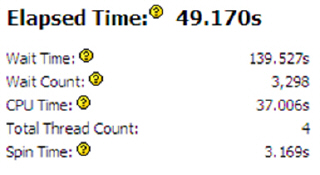

Осуществление анализа
Также имеется возможность просмотра более детальной информации по стеку вызова и объектам синхронизации
- 1 – объект,
- 2 – использование процессора,
- 3 – количество циклов ожидания

Анализ исходного кода
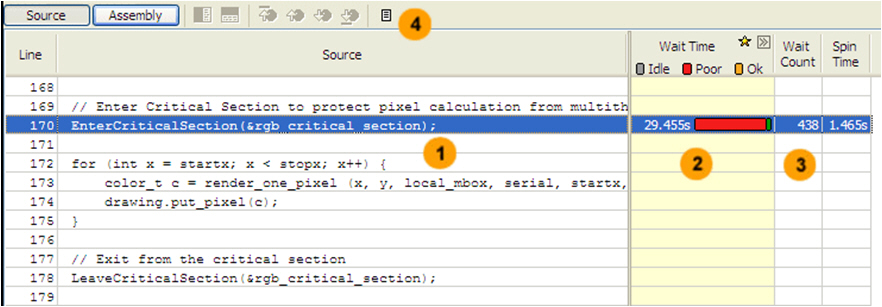
- 1 – строки кода,
- 2 – использование процессора,
- 3 – общее количество циклов ожидания,
- 4 - навигация
Сравнение результатов
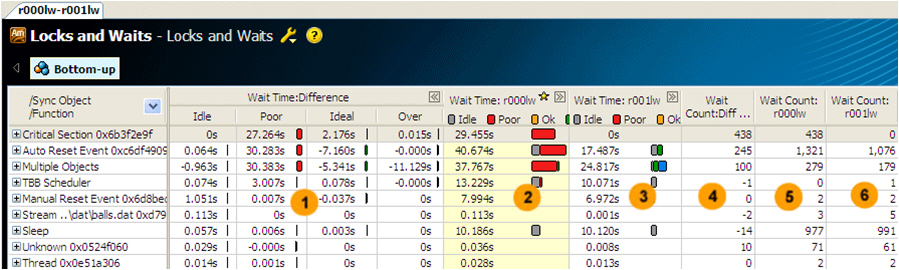
- 1 – различия во времени ожидания,
- 2 – время ожидания до оптимизаций,
- 3 – время ожидания после оптимизаций,
- 4 – разница в количестве циклов ожидания,
- 5 и 6 – количество циклов ожидания
Некоторые события
Здесь представлены названия некоторых счётчиков событий. Наиболее полезными для начала будут первые два – это такты процессора и количество исполненных инструкций. Ведь само по себе то, что ваша программа проводит 95% времени в одной функции и тратит на это миллионы тактов ещё ни о чём не говорит. Вот если за это время она успевает выполнить всего лишь тысячу инструкций, то где-то тут проблема. Соотношение CPU_CLK_UNHALTED / INST_RETIRED называется CPI (Clocks per Instruction) и оно позволяет грубо оценить насколько хорошо работает ваш код. Современные процессоры способны выполнять несколько инструкций за такт, так что это соотношение может быть значительно меньше единицы. Если же оно больше единицы, стоит посмотреть на это место внимательнее, возможно собрать дополнительную информацию. Например, может быть вы постоянно ждёте данных из памяти – об этом скажут следующие два события. От версии VTune и от того, какое "железо" вы используете, события могут называться по другому. Тем не менее в файлах помощи они все описаны и каталогизированы, какие события относятся к каким проблемам.
Про то, что неправильное предсказание переходов ломает конвеер и логику Out-Of-Order Execution мы уже говорили. Последнее событие как раз позволит вам оценить, всё ли хорошо в вашем коде с этой точки зрения.
Время доступа к памяти


Небольшое отступление по поводу доступа к памяти. Эти графики показывают пропускную способность (bandwidth) и время ожидания (latency) при обращении к памяти. Сняты они были на стареньком Pentium M, сейчас всё получше, но идея та же. Вы видите чёткие ступеньки. Первая это пока мы работаем с кэшем первого уровня, вторая – данные перестали попадать в кэш первого уровня, но спасает кэш второго уровня. Затем (а на той машине кэш был всего двухуровневый) начинается непосредственно прямой доступ в память. Вначале нам всё ещё помогает аппаратная логика предподкачки данных (hardware prefetch), но она тоже не всесильна, плюс у шины данных тоже есть максимальная пропускная способность. Но это уже крайний пример и вряд ли он вам будет часто встречаться в повседневной разработке.
Что влияет на то, насколько плохо использует ресурсы компьютера программа?
Итак, что у нас есть – конкуренция за общие ресурсы, такие как вычислительные устройства процессора. Особо к узким местам я хочу отнести какие-то постоянные синхронизации, которые не позволяют загрузить все ядра на полную мощность, а также просто неиспользование всего предлагаемого функционала. Кстати, это может происходить при переносе вручную написанного "высокооптимизированного" ассемблерного кода на новую платформу. Ну или при использовании неподходящего компилятора.