Хэш-таблицы, стеки, очереди
7.2. Распределители
Массивы и хеш-таблицы являются индексируемыми структурами.
- При вставке элемента необходимо задать некоторую идентифицирующую информацию: индекс – для массивов, ключ – для таблиц.
- При доступе необходимо указать ассоциированный индекс элемента или его ключ.
Структуры, к изучению которых мы приступаем, следуют другой политике. Они не используют ключей или другой идентифицирующей информации. Вы просто вставляете элемент, применяя для этого обычную процедуру:
put (x: G)
— Добавить x в текущую структуру.
Сравните c put(x:G, i:INTEGER) для массивов или с put(x:G, k:KEY) для хеш-таблиц. Когда же приходится получать элемент, у вас нет возможности его выбора. Вы делаете запрос
item: G
— Элемент, полученный из текущей структуры
require
not is_empty
У запроса нет аргументов (сравните с запросом item(i:INTEGER):G для массивов или с item( k:KEY):G для хеш-таблиц). Мы называем такие структуры распределителями по аналогии с автоматом, выдающим банки с напитком. Автомат, а не покупатель, решает, какую банку выдать покупателю.

Распределители отличаются политикой, используемой для выбора выдаваемого элемента.
- Last-In First-Out: выбирается элемент, поступивший последним из существующих. Распределитель с политикой LIFO называется стеком.
- First-In First-Out: выбирается элемент, поступивший первым из существующих. Распределитель с политикой FIFO называется очередью.
- Для очереди с приоритетами элементы обладают приоритетами (целое или вещественное число). Тогда по запросу будет выдаваться элемент, обладающий наибольшим приоритетом среди присутствующих. Может показаться, что этот случай ближе к индексированным структурам, но все же это пример распределителя, поскольку приоритет – это внутреннее свойство элемента, и распределитель, а не пользователь выбирает, какой элемент будет выдан.
У всех распределителей существуют четыре базисных метода: put и item с сигнатурами и предусловиями, показанными выше, а также булевский запрос
is_empty: BOOLEAN
— Правда, что элементов нет?)
и команда для удаления элемента:
remove
— Удалить элемент из текущей структуры.
require
not is_empty
Точно так же, как item не позволяет выбирать получаемый элемент, remove не позволяет выбирать удаляемый элемент. Удаляется тот элемент, который можно получить по запросу item, если выполнить его непосредственно перед вызовом remove.
Хорошая реализация распределителей должна выполнять все эти операции за время O(1). Примеры вскоре будут даны.
В некоторых библиотеках можно найти операции, которые комбинируют эффект item и remove: функцию, скажем, get, которая удаляет элемент, а в качестве результата выдает удаленный элемент. Такую функцию можно реализовать в терминах item и remove:
get: G
— Функция с побочным эффектом, нарушающая принципы методологии!
do
Result:= item
remove
end
Мы не будем использовать такие функции, так как они меняют структуру и возвращают результат, нарушая правило, что только команды, но не запросы, могут менять состояние структуры (принцип разделения команд и запросов). По причинам, объясненным в предыдущих лекциях, предпочтительнее позволять клиентам получать доступ и удалять элементы двумя разными методами – запросом, свободным от побочного эффекта, и командой.
В следующих двух разделах рассматриваются стеки и очереди. Мы не будем рассматривать очереди с приоритетами, но всегда можно обратиться к библиотеке EiffelBase и ознакомиться с классом PRIORITY_QUEUE.
7.3. Стеки
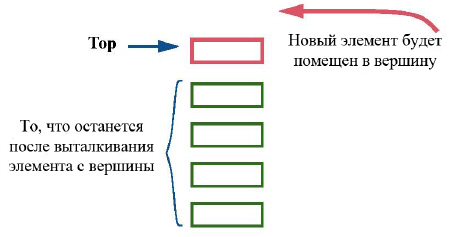
Стек – это распределитель с политикой LIFO: элемент, к которому можно получить доступ, есть элемент, поступивший последним из существующих в распределителе. Этот элемент располагается в "вершине" стека, что соответствует естественному образу стека в обыденном смысле этого термина. Примером может служить множество словарей, громоздящихся на моем столе в предположении, что первым я могу взять словарь, находящийся на вершине этой груды (стека).

Стек. Основы
Операции над стеком часто известны как:
- Push (втолкнуть элемент на вершину стека – команда put);
- Pop (вытолкнуть элемент с вершины – команда remove);
- доступ к элементу вершины (запрос item).
Эти операции можно визуализировать.
Использование стеков
Стеки имеют множество применений в компьютерной науке. Два примера из реализации языка программирования: один – статический (разбор, иллюстрируемый в простейшем случае обработкой "польской нотации"), другой – динамический, управление вызовами программ в период выполнения.
Предположим, что вы хотите вычислить математическое выражение в "польской нотации" – форме, часто применяемой в калькуляторах, а иногда и во внутреннем представлении компиляторов и интерпретаторов. Преимущество этой нотации в том, что устраняется неопределенность порядка вычислений без использования скобок – каждый знак операции применим к операндам, непосредственно предшествующим знаку. Результат операции над операндами является операндом следующей операции.
Рассмотрим для примера выражение
2 + (a + b) * (c – d)
В польской записи оно выглядит так
2 a b + c d – * +
Как будет происходить вычисление этого выражения? Первым знаком операции является +, так что выполнится сложение операндов a и b, предшествующих плюсу. Затем выполнится операция вычитания, затем умножение двух вычисленных операндов, последним выполнится сложение полученного результата с константой 2. Для простоты все операции бинарны, но схема легко адаптируется на произвольную "-арность" операций.
Следующий алгоритм, использующий стек операндов s, вычисляет общее выражение в польской записи с бинарными операциями:
from — Инициализация пуста
until
"Все термы выражения уже прочитаны"
loop
"Чтение очередного терма выражения - x"
if "x является операндом" then
s.put (x)
else — x является знаком бинарной операции
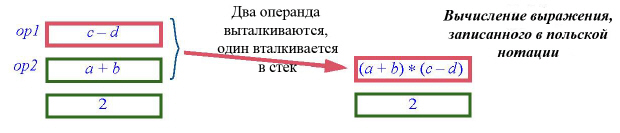
— Получить два верхних операнда
op1:= s.item; s.remove
op2:= s.item; s.remove
— Применить операцию к операндам и поместить результат в стек:
s.put (application (x, op1, op2))
end
end
В алгоритме используются две локальные переменные op1 и op2, представляющие операнды. Функция application вычисляет результат применения бинарной операции к ее операндам, например, application('+', 2, 3) возвращает значение 5. На следующем рисунке показана ключевая операция алгоритма, соответствующая предложению else, – обрабатывается знак умножения для выражения нашего примера.
Корректная реализация алгоритма должна справляться с ошибочным вводом (проверяя s.is_empty перед вызовом item и remove и проверяя, что x является знаком операции); необходимо также предусматривать возможность операций различной "-арности".
Наш второй пример лежит в основе поддержки исполняемой среды при реализации каждого современного языка программирования и присутствует в каждой операционной системе (это, конечно, сильное утверждение, но ни один контрпример не приходит на ум). Рассмотрим язык программирования, позволяющий методу вызывать другой метод, который, в свою очередь, может вызывать метод, и ситуация может повторяться. В результате появляется цепочка вызовов:

В любой момент времени в период выполнения несколько методов – от p до t на рисунке – были вызваны, начали свою работу, но еще ее не завершили. Последний вызванный метод в этом случае называется текущим методом. Рассмотрим одну из его команд, например, присваивание x:= y + z. Если только x, y, z не являются атрибутами охватывающего класса, то они должны принадлежать текущему методу и быть либо его аргументами (но не x, поскольку аргументу нельзя присваивать значения), либо локальными переменными. Будем использовать термин "локальные" для обеих категорий. Для выполнения операторов программы, таких как присваивание, код, генерируемый компилятором, должен иметь доступ ко всем локальным переменным. Решением этой проблемы является создание для каждого вызова метода активирующей записи, содержащей его локальные переменные:
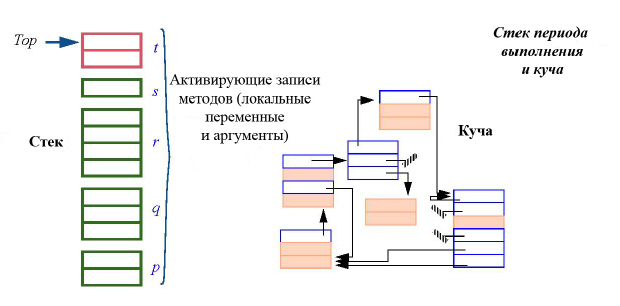
Структура справа называется "кучей", она содержит объекты, получаемые в результате вызова процедуры создания или ее эквивалента. Для нашего обсуждения интерес представляет стек вызовов, также называемый стек периода выполнения (чаще всего просто стек), содержащий активирующие записи для всех текущих активных методов. Поскольку метод не может завершиться, пока не завершатся методы, вызовы которых он инициировал, и стартовавшие позже него, подходящей схемой активации является стратегия LIFO и стек будет подходящей структурой.
В момент вызова метода механизм создает новую активизационную запись с локальными переменными метода, инициализированными значениями по умолчанию, и аргументами метода, которые инициализируются значениями фактических аргументов, переданных в точку вызова. Эта запись размещается в вершине стека. При завершении работы метода запись удаляется из стека и на вершину поднимается следующая в стеке запись.
Преимущество использования стека в том, что записи представляют не различные методы, а только различные сеансы выполнения. Как результат, эта техника позволяет поддерживать рекурсивные методы – методы, вызывающие себя непосредственно или косвенно. Создавая новую запись при вызове рекурсивного метода, позволяем каждому вызову хранить множество своих локальных переменных. Рекурсия – тема следующей лекции, а ее реализация, основанная главным образом на стеках, – тема отдельного раздела.
Реализация стеков
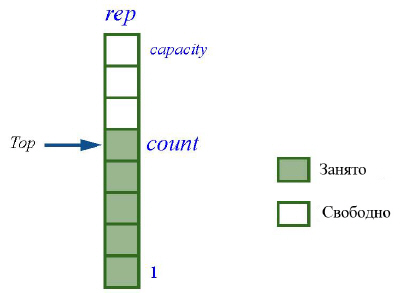
Как и для некоторых других структур этой лекции, существуют две общие категории реализации стеков, основанные на массивах и на связных списках. Наиболее общая реализация использует массив rep типа ARRAY[G] и целочисленную переменную count с инвариантом
count >= 0 ; count <= rep.capacity
Здесь емкость capacity представляет число элементов массива (upper – lower + 1). Для массивов, индексируемых с 1, элементы стека, если они есть, хранятся в позициях от 1 до count.
Мы уже сталкивались с этим различием, когда рассматривали список, реализованный на массиве. В обоих случаях реализация построена на массиве, в то время как спецификация задает другой контейнерный тип.
В этой реализации запрос item, который дает элемент, расположенный в вершине стека, просто возвращает rep[count] – элемент массива в позиции count. Достаточно просто может быть реализована и команда remove: count:= count -1, а команда put(x) – как
count:= count + 1 [9]
rep.force (x, count)
Листинг
7.9.
Здесь используется команда force для массивов, заставляющая перестроить массив, если отведенной памяти становится недостаточно.
Более подробно с реализацией можно познакомиться, изучая класс ARRAYED_STACK из библиотеки EiffelBase (фактически классу не нужен rep, поскольку он наследуется от ARRAY, но концептуально это эквивалентно, а мы все же формально наследование еще не изучали). Использование force в алгоритме для put означает, что можно не беспокоиться о размере массива – массив будет создаваться с установками по умолчанию, а потом подстраиваться под нужный размер данных.
Конечно, физическая память компьютера ограничена, но в большинстве случаев ее хватает для наших потребностей.
Перестройка массива, применяемая в Eiffel, не является общедоступной в других программных средах, поэтому там часто стеки, базируемые на массиве, имеют ограниченную емкость. Соответствующий класс есть и в Eiffel – BOUNDED_STACK. Для такого стека наряду с count используется и запрос capacity, и булевский запрос is_full, чье значение дается выражением count = capacity. В этом случае, так же, как существует предусловие для команды remove, будет существовать предусловие и для команды put – is_full. Реализация этой команды для такого стека использует put для массива, а не force, как в вышеприведенном примере 7.9. Выполнение предусловия гарантирует корректность выполнения put.
Все рассмотренные выше операции имеют сложность O(1).
Вариантом стека ограниченной емкости, реализованного на массиве, является стек, растущий вниз:
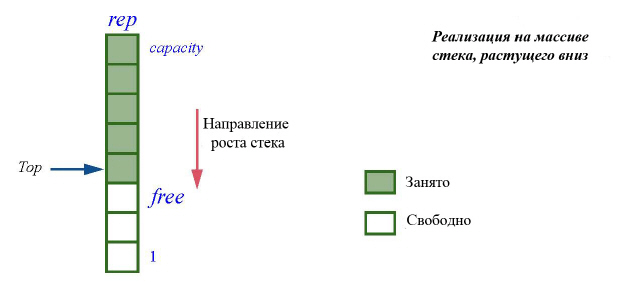
В этом представлении count более не является атрибутом, вместо этого появляется скрытый атрибут free, задающий индекс первой свободной ячейки. Запрос count по-прежнему остается доступным, но реализуется он теперь функцией, возвращающей значение capacity – free.
Инвариант теперь устанавливает, что free >= 0 и free <= capacity. Сравните этот инвариант с инвариантом для count в предыдущем представлении стека.
Случай free = 0 соответствует is_full, а free = capacity соответствует is_empty. Элементы стека, если они есть, располагаются в позициях от capacity до free +1. Метод remove реализуется просто: free = free +1, а put реализуется как
rep.force (x, free)
free:= free – 1
Если память ограничена и приходится одновременно работать с двумя стеками, то можно оба стека располагать на одном массиве, но на разных его концах; один растет вверх, другой вниз, что отражено на следующем рисунке:
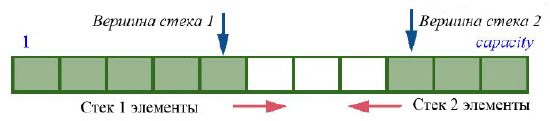
Преимущество этого подхода в том, что оптимальным образом используется память, если только оба стека не достигают своего максимума одновременно, поскольку
max (count1 + count2) ? max (count1) + max (count2)
В упражнении вас попросят написать реализацию класса TWO_STACK, воплощающего эту идею.
Наряду с реализацией на массивах вполне допустимо строить стек на связном списке. Действительно, связный список, изученный ранее в этой лекции, содержит готовую реализацию стека. Рисунок ниже иллюстрирует этот подход: первая ячейка является вершиной стека, а остальные – телом стека.
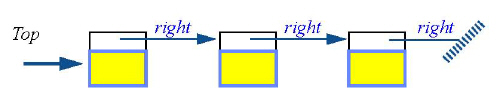
Операция put(x) реализуется просто как rep.put_front(x), где rep задает связный список. Аналогично, item реализуется как rep.first и так далее. Класс LINKED_STACK в EiffelBase обеспечивает такую реализацию. Все базисные операции имеют сложность O(1), хотя чуть медленнее, чем их двойники на массивах, например, put_front из класса LINKED_LIST, а следовательно, и put из LINKED_STACK должны сперва создать и отвести память ячейке LINKABLE.
Все базисные операции над стеком во всех рассмотренных реализациях выполняются за константное время, за исключением, как отмечалось, редкой операции force в перестраиваемом массиве, реализующем стек.