Создание и использование индексов
Индексы – одно из самых мощных средств, доступных разработчику базы данных. Индекс – это вспомогательная структура, позволяющая вам повышать производительность запросов за счет снижения количества операций ввода-вывода, необходимых для поиска запрошенных данных; т.е. индекс позволяет системе Microsoft SQL Server 2000 находить данные, используя меньшее число операций ввода-вывода, чем при поиске данных путем доступа только к таблице базы данных. Если для поиска строки данных вы используете индекс таблицы базы данных, SQL Server может быстро определить, где хранятся эти данные и сразу считать эти данные. Таким образом, индексы таблиц базы данных во многом похожи на индексы (алфавитные указатели) в книгах: в обоих случаях обеспечивается быстрый доступ к большим объемам информации.
В этой лекции вы узнаете об основах индексирования, включая создание индекса и типы индексов, доступные в SQL Server. Вы также узнаете, когда использовать индексы и когда не нужно их использовать, поскольку использование индекса не всегда эффективно – в некоторых ситуациях это приводит к снижению производительности.
Что такое индекс?
Как уже говорилось, индекс – это вспомогательная структура данных, используемая системой SQL Server для доступа к данным. В зависимости от типа индекса он хранится вместе с данными или отдельно от данных. Независимо от типа все индексы действуют одинаковым в своей основе способом, о котором вы узнаете в этом разделе.
В системах без индексов весь поиск данных должен выполняться путем сканирования таблиц. При сканировании таблиц приходится читать все данные и сравнивать их с запрашиваемыми данными. Обычно стараются обойтись без сканирования таблиц – из-за количества операций ввода-вывода, которое для этого требуется: сканирование больших таблиц может занимать длительный период времени и требовать использования большого количества системных ресурсов. Используя индекс, вы можете кардинально снизить количество операций ввода-вывода, ускорив доступ к данным и освободив системные ресурсы для других операций.
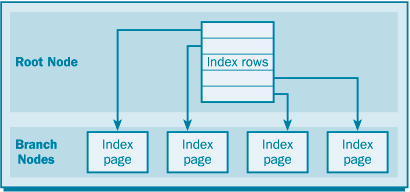
Индекс базы данных организован в виде структуры B-дерева. Каждая страница индекса называется индексной страницей, или узлом индекса. Структура индекса начинается на верхнем уровне с корневого узла. Корневой узел соответствует началу индекса: это первые данные, к которым осуществляется доступ при поиске данных. Корневой узел содержит ряд строк индекса. Эти строки содержат значение ключа и указатель на определенную индексную страницу (которая называется узлом-ветвью) (рис. 17.1). Эта конфигурация необходима, поскольку в случае таблицы данных среднего масштаба индекс состоит из тысяч или миллионов индексных страниц. Начав поиск с корневого узла и перемещаясь по узлам индекса, SQL Server может постепенно "приближаться" к нужным вам данным.
Если использовать в качестве аналога книгу, то индекс действует следующим образом: предположим, что началом индекса (алфавитного указателя) является страница, где указаны номера страниц для статей индекса на букву "a", "b", "c" и т.д. Затем предположим, что эти страницы содержат номера страниц для статей в диапазонах aa-ab, Ас-ad, ae-af и т.д., а соответствующие страницы – номера страниц для записей в диапазонах aaa-aab, aАс-aad, aae-aaf и т.д. При подобной организации вы можете быстро найти то, что вам нужно, с использованием относительно небольшого количества операций поиска. Такая структура аналогична индексу таблицы базы данных, когда первой страницей является корневой узел.
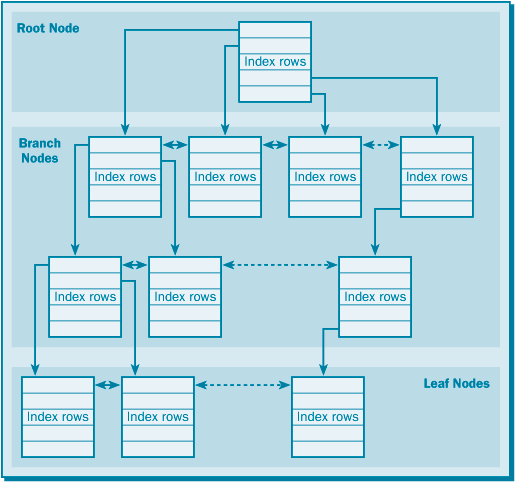
Как и корневой узел, каждый узел-ветвь содержит ряд индексных строк в структуре индексной страницы. Каждая индексная строка указывает на другой узел-ветвь или на узел-лист (конечный узел) (рис. 17.2). Узел-лист является последним уровнем индекса. В отличие от корневого узла каждый узел-ветвь содержит также связанный список узлов-ветвей того же уровня. Иными словами, узел "знает" о смежных узлах и об узлах более низкого уровня.
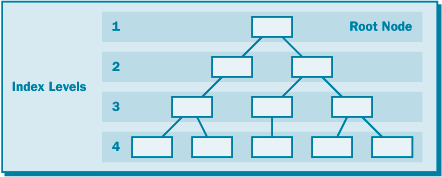
Как следует из названия "B-дерево", узлы-ветви разветвляются от корневого узла в древовидной форме. Каждая группа узлов-ветвей одного уровня в древовидной структуре называется уровнем индекса (рис. 17.3). Количество операций ввода-вывода, которое требуется для достижения узлов-листьев (узлов самого нижнего уровня дерева), зависит от количества уровней индекса. Если таблица базы данных содержит лишь небольшое количество данных, то корневой узел может указывать непосредственно узлы-листья, и тогда для индекса вообще не требуется никаких узлов-ветвей (маловероятная ситуация).
В некластеризованном индексе узел-лист содержит значение ключа, а также идентификатор строки (Row ID), указывающий нужную строку в таблице, или ключ кластеризованного индекса, если имеется также кластеризованный индекс по этой таблице. А в кластеризованном индексе в узле-листе находятся сами данные. (О кластеризованных и некластеризованных индексах см. раздел "Типы индексов" далее.) Количество строк в узле-листе зависит от размера индексных записей, а в случае кластеризованного индекса – от размера данных.
 Примечание. Row ID – это указатель, который автоматически формируется системой SQL Server из идентификатора файла (File ID), номера страницы и номера строки данных. Используя Row ID, вы можете считывать данные с помощью всего лишь одной дополнительной операции ввода-вывода. Поскольку вы знаете, какую страницу нужно считывать, а SQL Server "знает", где эта страница находится, то она считывается в память с помощью единственного запроса ввода-вывода. Именно простота этого процесса определяет эффективность использования индексов для считывания данных и обеспечивает столь значительное повышение производительности.
Примечание. Row ID – это указатель, который автоматически формируется системой SQL Server из идентификатора файла (File ID), номера страницы и номера строки данных. Используя Row ID, вы можете считывать данные с помощью всего лишь одной дополнительной операции ввода-вывода. Поскольку вы знаете, какую страницу нужно считывать, а SQL Server "знает", где эта страница находится, то она считывается в память с помощью единственного запроса ввода-вывода. Именно простота этого процесса определяет эффективность использования индексов для считывания данных и обеспечивает столь значительное повышение производительности.Имейте в виду, что, поскольку индекс создается в отсортированном порядке, любые изменения в данных могут приводить к дополнительной нагрузке на систему. Например, если вставка приводит к созданию новой строки индекса, которую нужно поместить в узел-лист, который уже заполнен до конца, то SQL Server должен создать место для новой строки индекса. Он выполняет эту задачу, перемещая приблизительно половину строк узла-листа на другую страницу. Это перемещение данных называется расщеплением страницы. Расщепление страницы на одном уровне дерева может приводить к каскадным расщеплениям на более высоких уровнях. Расщепления страниц можно избежать путем соответствующей настройки коэффициента заполнения. (См. раздел "Использование коэффициента заполнения для предупреждения расщеплений страниц" далее.)