Алтайский государственный университет
Опубликован: 12.07.2010 | Доступ: свободный | Студентов: 1468 / 390 | Оценка: 4.02 / 3.93 | Длительность: 16:32:00
ISBN: 978-5-9963-0349-6
Тема: Аппаратное обеспечение
Специальности: Разработчик аппаратуры
Лекция 7:
Проект ATAC
Структура межъядерных связей
Архитектура АТАС представляет собой "плиточную/ячеистую" многоядерную архитектуру, сочетающую технологию электрических соединений с оптической накристальной сетью. Применяется связанный двумерный массив простых вычислительных ядер, каждое из которых содержит одиночный или двойной RISC-процессор и кэш данных первого уровня. ATAC использует протокол распределенных директорий. Часть распределенной директории расположена в каждом узле.
Ядра в АТАС связаны двумя сетями — электрической EMesh и оптико-электрической ANet. ENet — обычная двумерная электрическая сеть типа "точка-точка", аналогичная существующим в обычных мультипроцессорах. EMesh идеальна для предсказуемых, близких взаимодействий. ANet предлагает технологию для организации оптической накристальной сети, основанную на технологии оптической памяти. Ядро сети ANet составляет ONet ( рис. 7.5). Сеть ANet содержит 64 оптически соединенных кластера, включающих в себя небольшие электрические структуры, служащие для взаимодействия с оптической сетью, — это сети ENet и BNet.
ANet используется обычно для осуществления передачи данных между удаленными ядрами или для глобальных передач в рамках сети (широковещательные передачи).
Ключ к эффективной организации глобальных коммуникаций в пределах кристалла — оптическая сеть ONet. Она обеспечивает связь между отдельными конечными точками, называемыми хабами. Хабы соединены между собой световодом, проходящим через весь кристалл, формируя замкнутое кольцо ( рис. 7.5). При помощи модулятора, оптических фильтров и приемника хаб имеет возможность передавать и принимать данные из световодов. Сигнал, посланный одним из хабов, быстро достигает остальных. Таким образом, любая передача в сети может быть широковещательной. Для передачи независимых данных применяется частотное мультиплексирование каналов. Каждый хаб имеет фильтры, настроенные на уникальную длину волны, и фильтры, позволяющие ему принимать сигналы на всех длинах волн. Эта возможность используется при организации глобальных передач, синхронизации ядер, управлении сетью. В дополнение к этому повышенная скорость передачи исключает разнородную задержку распространения сигнала, зависящую от расстояния между ядрами, — в любой паре хабы взаимодействуют между собой с малой фиксированной задержкой, вместо задержки на один цикл на узел в связях типа "точка-точка". В общем, функциональность сети ONet можно сравнить с полносвязной сетью с двунаправленными связями между узлами и с дополнительной функцией широковещания. Частотное разделение каналов позволяет задействовать один световод для нескольких перекрывающихся передач в различных направлениях (для сравнения, электрическая связь обычно используется для передачи одного бита). Для многих сетевых операций, трудно реализуемых в электрических сетях, применение АТАС существенно увеличивает эффективность. ONet может масштабироваться до как минимум 64 хабов (возможно до 100). Количество длин волн, на которые могут быть настроены фильтры, ограничено минимально необходимым расстоянием, спектральной шириной канала и общей шириной полосы излучения в питающем световоде. Также существуют ограничения по общему количеству энергии, которое может передать световод в отношении к количеству энергии, требуемому детектором для приема сигнала, и по максимальной длине волновода, зависящей от потерь распространения.
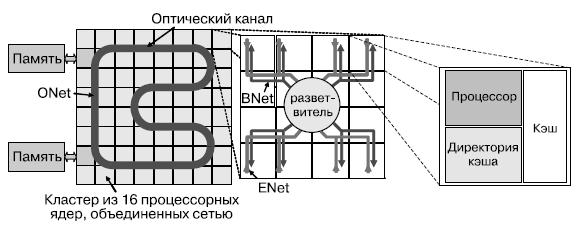
Указанные ограничения могут быть обойдены использованием нескольких волноводов и распределением каналов передачи данных между ними. Как правило, при этом площадь, необходимая для реализации световода, может также стать ограничением. Оптические компоненты сети и сама сеть могут быть вынесены на отдельный уровень КМОП-стека и накладываться на электронные компоненты, к которым они подключаются. К примеру, на кристалле площадью 400 мм2 может разместиться оптическая сеть с 384 хабами. Для рассматриваемого случая ONet соединяет 64 одинаковых кластера при помощи 64-битной оптической шины, проложенной по всему кристаллу. Каждый кластер содержит 16 вычислительных ядер и хаб сети ONet. Внутри кластера ядра связаны между собой и с оптическим хабом двумя сетями — ENet и BNet. ENet используется только для передачи данных от ядер кластера к хабу ONet. BNet — широковещательная электрическая сеть для передачи данных от оптической сети вычислителям.
Передача данных и согласование кэш-памяти
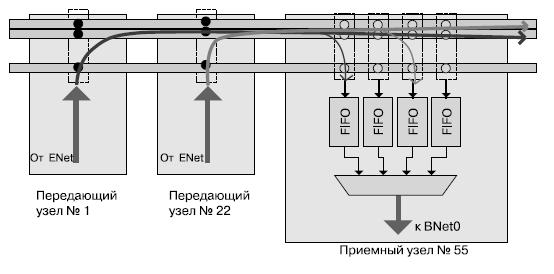
Более детально процесс передачи данных с применением сети ANet показан на рис. 7.6. Сообщения ядер достигают хаба, который, в свою очередь, пересылает их в сеть ONet на своей уникальной длине волны. Это позволяет двум хабам передавать данные одновременно без интерференции. ONet состоит из нескольких световодов: 64 для данных, 1 для управления и несколько для метаданных. Световоды метаданных служат для указания типа передаваемого сообщения (чтение памяти, данные и пр.) или как тэг сообщения (для устранения двусмысленности при нескольких сообщениях от одного источника). Хаб приемника принимает оба значения последовательно в FIFO-буфер, связанный с конкретным отправителем. Затем данные пересылаются вычислительным ядрам через BNet. Оптическая часть позволяет эффективно реализовывать широковещательную передачу с большей скоростью и меньшими затратами на регенерацию сигнала.
Ядра в АТАС — простые процессоры с кэшем данных и команд первого уровня. Когерентность кэшей поддерживается при помощи протокола, известного как ACKwise. Кэши поддерживают когерентность при помощи протокола распределенных директорий MOESI.
Директории распределены равномерно между ядрами, более того, каждое ядро является "домом" для определенного пула адресов (распределяется статически). Рис 7.7 представляет три ядра, находящиеся в различных кластерах. Каждое ядро содержит процессор, кэш данных и директории кэша. Для примера ( рис. 7.7) предположим, что обращение к директории кэша всегда приводит к промаху (необходимости синхронизации кэша). Стрелками на рисунке обозначены типовые операции по согласованию кэшей: промах по записи по адресу А ядром а. В данном примере ядро б является "домом" адреса А, и начальное состояние адреса А в кэше — "занято" (O-state) ядром с. Трафик по согласованию кэшей передается по сети ANet. Последовательность действий для согласования кэшей для данного случая будет следующей:
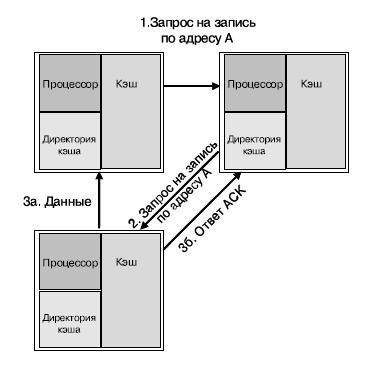
- процессор в ядре а пытается осуществить запись по адресу А и получает ошибку записи;
- ядро а посылает запрос на запись ядру б, к которому относится адрес А;
- ядро б не имеет данных в кэше, но указывается, что этот адрес занят ядром с. Ядро б посылает запрос на запись по этому адресу от имени ядра а;
- линия кэша, содержащая адрес А, обновляется на ядре а, и линия получает статус "модифицирована";
- процессор ядра а производит запись по адресу А.
Когда ядрам необходимо обратиться к внешней памяти, они делают это при помощи нескольких встроенных в кристалл контроллеров памяти. Каждый контроллер памяти замещает кластер ядер и, таким образом, имеет свой выделенный оптический хаб. После получения запроса по оптической сети он обращается к внешним DRAM-модулям посредством стандартных линий ввода-вывода. Результаты передаются в оптическую сеть. Изменяя количество контроллеров памяти и количество кластеров, можно на различных АТАС-процессорах достигать различных значений показателей пропускной способности подсистемы памяти и вычислительной мощности. Основная задача контроллера памяти — преобразовать запросы от процессорных ядер в транзакции на шине памяти. Выбор технологии шины, таким образом, не зависит от архитектуры накристальной сети.
Вполне допустим вариант использования оптических интерфейсов как на ввод-вывод, так и для шины памяти. Это даст преимущество в пропускной способности и потребляемой мощности.
Каждый оптический вывод может поддерживать до 64 длин волн со скоростями до 20 ГГц. Скорость передачи данных будет ограничена скоростью работы электронных компонент, управляющих оптическим потоком. Предполагается, что скорость в 5 ГГц вполне может быть достигнута. При этом полоса пропускания оптического вывода может достигать 320 Гб/с (40 Гб/с). Для сравнения, 64-битная DDR3 имеет пиковую пропускную способность 12,8 Гб/с. Поскольку оптическая шина памяти состоит только из одного световода, уменьшается количество выводов, и это при увеличении пропускной способности практически в три раза. Все это де- лает применение оптического ввода-вывода востребованным для АТАС- процессоров с несколькими контроллерами памяти.
Краткие итоги
Архитектура ATAC предлагает способ масштабирования многоядерных систем за счет объединения кластеров ядер оптической сетью в пределах кристалла. Предусматривается до 64 отдельных оптических каналов передачи данных за счет использования различных длин волн. Упрощается обмен широковещательными сообщениями, увеличивается скорость обмена данными.
Архитектура ориентируется на 11-нм техпроцесс, который, по мнению ее разработчиков, может быть реализован к середине десятилетия (ориентировочно 2012-2016 гг.).
Контрольные вопросы
- В чем состоят принципы построения многоядерных систем на основе технологии ATAC?
- Укажите способы передачи данных в ATAC.
- Опишите структуру и принцип работы оптического приемопередатчика (модулятора и фильтра).
- Каким образом осуществляется согласование кэшей в ATAC?
Упражнения
- Найдите и сравните между собой гибридные технологии производства процессоров.
- Оцените состояние разработок оптических, квантовых и клеточных процессоров.