|
Подскажите, пожалуйста, планируете ли вы возобновление программ высшего образования? Если да, есть ли какие-то примерные сроки? Спасибо! |
Опубликован: 20.12.2010 | Доступ: свободный | Студентов: 2424 / 171 | Оценка: 4.27 / 3.91 | Длительность: 39:39:00
ISBN: 978-5-9963-0353-3
Тема: Базы данных
Специальности: Администратор баз данных
Лекция 17:
SQL в хранилищах данных: аналитическая обработка данных
Функции ранжирования
Функции ранжирования вычисляют ранг записи по отношению к другим записям в наборе данных, основываясь на значении набора метрик (measures). Они возвращают ранжирующее значение для каждой строки в секции. В зависимости от используемой функции значения некоторых строк могут совпадать.
Типы ранжирующих функций приведены в табл. 23.4.
| Функция | Возвращаемое значение |
|---|---|
| RANK | Возвращает ранг каждой строки в секции результирующего набора. Ранг строки вычисляется как единица плюс количество рангов, находящихся до этой строки. Возвращаемый тип данных — bigint |
| DENSE_RANK | Возвращает ранг строк в секции результирующего набора без промежутков в ранжировании. Ранг строки равен количеству различных значений рангов, которые предшествуют строке, увеличенному на единицу. Возвращаемый тип данных — bigint |
| NTILE | Распределяет строки упорядоченной секции в заданное количество групп. Группы нумеруются, начиная с единицы. Для каждой строки функция NTILE возвращает номер группы, которой принадлежит строка |
| ROW_NUMBER | Возвращает последовательный номер строки в секции результирующего набора, 1 соответствует первой строке в каждой из секций. Возвращаемый тип данных — bigint |
Функции RANK и DENSE_RANK
Функции RANK и DENSE_RANK позволяют ранжировать итемы в группе, например, найти top 3 товаров, продаваемых в Калифорнии в последний год. Существуют две функции ранжирования с синтаксисом:
RANK ( ) OVER ( [ < partition_by_clause > ] < order_by_clause > )
< partition_by_clause > ([PARTITION BY <value expression1> [, ...]]) делит результирующий набор, полученный с помощью предложения FROM, на секции, к которым применяется функция RANK.
< order_by_clause > ( ORDER BY <value expression2> [collate clause] [ASC|DESC] ) определяет порядок, в котором значения RANK применяются к строкам в секции. Целое значение не может представлять столбец < order_by_clause > при использовании его в ранжирующей функции.
Если две и более строки претендуют на один ранг, то все они получат одинаковый ранг. Например, если двум лучшим продавцам соответствует одинаковое значение объема продаж, им обоим присваивается ранг 1. Менеджер по продажам со следующим по величине значением объема продаж получит ранг номер 3, так как перед ним находятся две строки с более высоким рангом. Поэтому функция RANK не всегда возвращает последовательные целые числа.
Порядок сортировки, используемый для всего запроса, определяет порядок, в котором строки будут появляться в результирующем наборе.
DENSE_RANK ( ) OVER ( [ < partition_by_clause > ] < order_by_clause > )
< partition_by_clause > делит результирующий набор, полученный с помощью предложения FROM, на секции, к которым применяется функция DENSE_RANK.
< order_by_clause > определяет порядок, в котором значения DENSE_RANK применяются к строкам секции. Целое число не может представлять столбец в <order_by_clause>, который используется в ранжирующей функции.
Если две или более строки одной секции равны при ранжировании, каждой такой строке присваивается один и тот же ранг. Например, если двум лучшим продавцам соответствует одинаковое значение объема продаж, им обоим присваивается ранг 1. Менеджеру по продажам со следующим по величине значением объема продаж назначается ранг 2. Это на единицу больше, чем число разных рангов строк, расположенных перед этой строкой. Таким образом, между номерами, возвращаемыми функцией DENSE_RANK, нет промежутков, и они всегда имеют последовательные значения ранга.
Порядок сортировки строк в результате определяется порядком сортировки результата всего запроса. Из этого следует, что строка с рангом 1 не всегда является первой строкой в секции.
Таким образом, различие между RANK и DENSE_RANK состоит в том, что DENSE_RANK не оставляет промежутков в ранжируемой последовательности.
Функцию RANK рекомендуется применять в случаях, если:
- порядок сортировки для этих функций является принятым по умолчанию порядком сортировки - по возрастанию;
- выражения в предложении PARTITION BY делят результирующее множество запроса на группы, с которыми оперируют, функция RANK переопределяется при переходе к следующей группе. Фактически, <value expression> предложения PARTITION BY определяет границы действия функции;
- предложение PARTITION BY пропущено, тогда ранг вычисляется для всего результирующего множества запроса;
- предложение ORDER BY определяет метрики ( <value expressions> ), на которых вычисляется ранг, определяет порядок, в котором строки сортируются в каждой группе или секции. Когда данные сортируются в каждой секции, ранги даются для каждой строки, начиная с 1;
- <value expression2> может быть любым допустимым выражением, включающим ссылки на колонки, агрегаты или выражения, составленные из перечисленных элементов.
Рассмотрим ряд примеров применения ранжирующих функций.
Можно выполнять ранжирование по нескольким выражениям. Функции ранжирования необходимы для нахождения связи между значениями на множестве записей. Если первое выражение не может выявить связь, то второе используется для выявления связи и т.д.
Пример 23.5. Использование функции RANK().
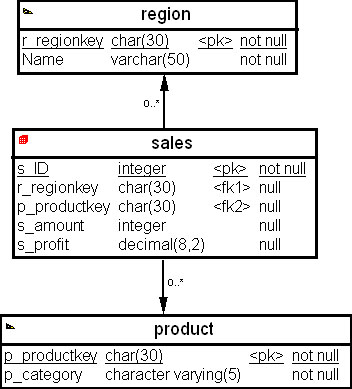
Путь нужно ранжировать товар, основываясь на продажах в рублях в каждом регионе, разрывая связь с доходом. Физическая схема киоска данных приведена на рис. 23.5.
На схеме представлены таблица фактов "Продажи" (sale) с метриками "Количество" (s_amount) и "Прибыль" (s_profit); две таблицы измерений "Регион" (region) и "Товар" (product).
Следующий запрос решает поставленную задачу:
SELECT r_regionkey, p_productkey, s_amount, s_profit, RANK() OVER (ORDER BY s_amount DESC, s_profit DESC) AS 'Ранг по востоку' FROM region, product, sales WHERE region.r_regionkey = sales.s_regionkey AND product.p_productkey = sales.s_productkey AND r_regionkey = 'Восток';
Результат выполнения запроса приведен ниже.
Вывод 5.
| R_REGIONKEY | S_PRODUCTKEY | S_AMOUNT | S_PROFIT | Ранг по востоку |
|---|---|---|---|---|
| Восток | Ботинки | 130 | 30 | 1 |
| Восток | Жакеты | 100 | 28 | 2 |
| Восток | Брюки | 100 | 24 | 3 |
| Восток | Свитеры | 75 | 24 | 4 |
| Восток | Рубашки | 75 | 24 | 4 |
| Восток | Ремни | 60 | 12 | 6 |
| Восток | Футболки | 20 | 10 | 7 |
Для жакетов и брюк колонка "Доход" (s_profit) показывает связь с колонкой "Количество" (s_amount). Но для свитеров и рубашек колонка "Доход" не может установить связь с колонкой "Количество". Следовательно, им присвоен один и тот же ранг.
Различие между RANK() и DENSE_RANK() может быть показано с помощью запроса к таблице фактов "Продажи":
SELECT р_productkey, SUM(s_amount) as 'Суммарное количество', RANK() OVER (ORDER BY SUM(s_amount) DESC) AS 'rank_all', DENSE_RANK() OVER (ORDER BY SUM(s_amount) DESC) AS 'rank_dense' FROM sales GROUP BY р_productkey;
Результат выполнения запроса приведен ниже.
Вывод 6.
| S_PRODUCTKEY | Суммарное количество | rank_all | rank_dense |
|---|---|---|---|
| Ботинки | 100 | 1 | 1 |
| Жакеты | 100 | 1 | 1 |
| Брюки | 89 | 3 | 2 |
| Свитеры | 75 | 4 | 3 |
| Рубашки | 75 | 4 | 3 |
| Ремни | 66 | 6 | 4 |
| Футболки | 66 | 6 | 4 |
Как видно по результирующему множеству, в случае функции DENSE_RANK() наибольшее значение ранга равно числу различных значение в наборе данных.
Функция RANK() может быть применена для операции в группах, т.е. ранг переустанавливается при изменении группы данных. Это важно для опции PARTITION BY. Группирующее выражение в PARTITION BY выделяет подклассы данных в наборе данных, с которыми работает RANK.
Пример 23.6. Необходимо ранжировать товары в каждом регионе по их продаже в рублях. Можно написать запрос для схемы на рис. 23.5, который ранжирует товары на основе их продаж в рублях в каждом регионе ( rank_of_product_per_region ) и во всех регионах ( rank_of_product_total ).
SELECT r_regionkey, p_productkey, SUM(s_amount) AS 'SUM_S_AMOUNT', RANK() OVER (PARTITION BY r_regionkey ORDER BY SUM(s_amount) DESC) AS 'rank_of_product_per_region', RANK() OVER (ORDER BY SUM(s_amount) DESC) AS 'rank_of_product_total' FROM product, region, sales WHERE region.r_regionkey = sales.r_regionkey AND product.p_productkey = sales.p_productkey GROUP BY r_regionkey, p_productkey ORDER BY r_regionkey;
Результат выполнения запроса приведен ниже.
Вывод 7.
| R_REGIONKEY | P_PRODUCTKEY | SUM_S_AMOUNT | RANK_OF_PRODUCT_PER_REGION | RANK_OF_PRODUCT_TOTAL |
|---|---|---|---|---|
| Восток | Ботинки | 130 | 1 | 1 |
| Восток | Жакеты | 95 | 2 | 4 |
| Восток | Рубашки | 80 | 3 | 6 |
| Восток | Свитеры | 75 | 4 | 7 |
| Восток | Футболки | 60 | 5 | 11 |
| Восток | Ремни | 50 | 6 | 12 |
| Восток | Брюки | 20 | 7 | 14 |
| Запад | Ботинки | 100 | 1 | 2 |
| Запад | Жакеты | 99 | 2 | 3 |
| Запад | Футболки | 89 | 3 | 5 |
| Запад | Свитеры | 75 | 4 | 7 |
| Запад | Рубашки | 75 | 4 | 7 |
| Запад | Ремни | 66 | 6 | 10 |
| Запад | Брюки | 45 | 7 | 13 |
Функция NTILE
Функция NTILE() делит упорядоченную секцию на указанное число групп, называемых бакетами ( buckets ), и назначает номер бакета каждой строке в секции. Для каждой строки функция NTILE() возвращает номер группы, которой принадлежит строка. NTILE() — очень полезная функция, поскольку дает возможность разделить набор данных на 40, 30 или другое число групп.
Бакеты вычисляются так, чтобы каждый из них имел одинаковое число строк, назначенное ему, или на одну больше. Например, если есть 100 строк в секции и находится функция NTILE для 4 бакетов, то 25 строк будет назначаться каждому бакету.
Если число строк в секции не делится нацело (на число бакетов), то число строк, назначаемое каждому бакету в начале, будет отличаться по крайней мере на 1. Например, если есть 103 строки в секции, к которой применяется функция NTILE(5), первые 21 строк будут назначены 1 бакету, следующие 21 — 2 бакету, следующие 21 — 3 бакету, следующие 20 — 4 бакету и последние 20 — 5 бакету.
Синтаксис:
NTILE (integer_expression) OVER ( [ <partition_by_clause> ] < order_by_clause > )
integer_expression - положительное целое выражение-константа, указывающее количество групп, на которые необходимо разделить каждую секцию. Аргумент integer_expression может иметь тип int или bigint.
<partition_by_clause> делит результирующий набор, сформированный предложением FROM.
< order_by_clause > определяет порядок назначения значений функции NTILE строкам секции.
Аргумент integer_expression может ссылаться только на столбцы в предложении PARTITION BY и не может ссылаться на столбцы, перечисленные в текущем предложении FROM.
Пример 23.7. Использование функции NTILE()
Пусть нам нужно провести группировку проданных товаров по объему продаж, используя схему на рис. 23.5. Это можно сделать с помощью следующего запроса:
SELECT p_productkey, s_amount, NTILE(4) (ORDER BY s_amount DESC AS '4_tile' FROM product, sales WHERE product.p_productkey = sales.p_productkey;
Результат выполнения запроса приведен ниже.
Вывод 8.
| P_PRODUCTKEY | S_AMOUNT | 4_TILE |
|---|---|---|
| Костюмы | 110 | 1 |
| Ботинки | 100 | 1 |
| Жакеты | 90 | 1 |
| Рубашки | 89 | 2 |
| Футболки | 84 | 2 |
| Свитеры | 75 | 2 |
| Джинсы | 75 | 3 |
| Ремни | 75 | 3 |
| Брюки | 69 | 3 |
| Ленты | 56 | 4 |
| Носки | 45 | 4 |
NTILE() является недетерминистической функцией. Равные значения могут распределяться различным бакетам (75 назначено бакетам 2 и 3); бакеты '1', '2' и '3' имеют по 3 элемента — на один больше, чем бакет '4'. В результирующем множестве "джинсы" можно было бы назначить бакету 2 (вместо 3) и "свитеры" — бакету 3 (вместо 2), потому что не существует упорядочивания по колонке p_productkey. Для того чтобы быть уверенным в детерминистическом результате, вы должны упорядочить результирующее множество по уникальному ключу.
Владислав Нагорный
Лариса Парфенова
|
1) Можно ли экстерном получить второе высшее образование "Программная инженерия" ? 2) Трудоустраиваете ли Вы выпускников? 3) Можно ли с Вашим дипломом поступить в аспирантуру?
|