







|
Подскажите, пожалуйста, планируете ли вы возобновление программ высшего образования? Если да, есть ли какие-то примерные сроки? Спасибо! |
Спонсор: Microsoft
Вы можете этот курс.
Опубликован: 20.12.2010 | Доступ: свободный | Студентов: 2412 / 165 | Оценка: 4.27 / 3.91 | Длительность: 39:39:00
ISBN: 978-5-9963-0353-3
Тема: Базы данных
Специальности: Администратор баз данных
Теги:
Лекция 11:
Проектирование и разработка процесса ETL
Конструирование процесса заполнения таблиц измерений
Для таблиц измерений ХД, которые не будут изменяться со временем, в разработке процесса ETL первой основной задачей является выбор первичного ключа таблицы. Выбор ключа осуществляется проектировщиком ХД на основе анализа источников данных.
Второй основной задачей является проверка наличия в измерении отношений "один к одному" и "один ко многим". Как правило, для такой проверки используется сортировка.
Затем следует рассмотреть изменяющиеся измерения, определить тип изменений и описать процедуры работы с такими измерениями.
Загрузка таблиц измерений выполняется либо путем перезаписи таблицы измерения (для небольших по объему таблиц), либо загружаются только изменения в данных таблиц измерений.
Конструирование процесса заполнения таблиц фактов
При конструировании процесса заполнения таблиц фактов проектировщик решает следующие основные задачи:
- проанализировать построенные таблицы фактов;
- рассмотреть процесс загрузки таблиц фактов;
- рассмотреть и проанализировать построенные агрегаты;
- рассмотреть процесс загрузки агрегатов.
Процесс загрузки таблиц фактов бывает двух типов: первоначальная загрузка и периодическая загрузка изменений.
Проблемы, связанные с первоначальной загрузкой, состоят в том, что с большой долей вероятности вы не получите корректных исторических данных из-за больших объемов данных. Поэтому важно оценить, какой тип загрузки для какой таблицы фактов подходит наилучшим образом.
Отметим, что в процессе ETL таблицы измерения должны обновляться до обновления таблиц фактов, поскольку релевантные строки таблиц измерений должны быть размещены для загружаемых новых фактов.
Классификация типов источников данных
Источники данных для ХД можно разбить на следующие основные типы.
- Не корпоративные источники данных:
- моментальные снимки -- полная копия источника;
- специфические источники данных - унаследованные системы;
- журналы транзакций БД источников -- переписываются только изменения;
- наборы данных, получаемые в результате запроса SQL.
- Корпоративные источники данных:
- реплицируемые источники данных, работающие по механизмам публикации или подписки;
- источники, работающие по вызову (Call back sources), когда в случае изменений вызываются процедуры ETL-процесса;
- источники, работающие по факту изменений данных, когда ETL-процесс запускается, как только данные в источнике изменились, например, по механизму триггеров БД.
Отметим, что стратегия извлечения данных в значительной степени зависит от типа источника данных.
Элементы ETL-процесса
Извлечение данных
Целью процесса извлечения данных является быстрое извлечение релевантных данных из источников данных.
Процесс извлечения данных из источников данных можно разбить на следующие основные типы:
- извлечение данных при помощи приложений, основанных на выполнении SQL-команд. Эти приложения функционируют совместно с другими приложениями систем источников данных;
- извлечение данных при помощи встроенных в СУБД механизмов импорта/экспорта данных. Использование таких механизмов, как правило, обеспечивает более быстрое извлечение данных, чем с помощью команд SQL;
- извлечение данных с помощью специально разработанных приложений.
Процесс извлечения данных может выполняться ежедневно, еженедельно или, в редких случаях, ежемесячно. Отметим, что существует целый класс систем бизнес-аналитики, которые требуют извлечения данных в режиме реального времени: например, системы, анализирующие биржевые операции (каждую секунду), или системы в области телекоммуникаций.
Процесс извлечения данных может выполняться либо в среде оперативных систем обработки данных (источников), либо в среде функционирования ХД.
Преобразование данных
Процесс преобразования данных источников включает в себя следующие основные действия.
- Преобразование типов данных:
- Преобразования, связанные с нормализацией или денормализацией схемы данных:
- Преобразования ключей, связанные с обеспечением соответствия бизнес-ключей суррогатным ключам ХД.
- Преобразования, связанные с обеспечением качества данных в ХД.
Как правило, данные источников не обладают необходимым уровнем качества данных. Заметим, что данные в ХД должны быть:
- точными – данные должны содержать правильные количественные значения метрик или давать объяснения, почему невозможно такие значения иметь;
- полными – пользователи ХД должны знать, что имеют доступ ко всем релевантным данным;
- согласованными – никакие противоречия в данных не допускаются: агрегаты должны точно соответствовать подробным данным;
- уникальными – одни и те же объекты предметной области должны иметь одинаковые наименования и идентифицироваться в ХД одинаковыми ключами;
- актуальными – пользователи ХД должны знать, с какой частотой данные обновляются (т.е. на какую дату данные действительны).
Для обеспечения качества данные при преобразовании подвергаются процедуре очистки. Процедура очистки данных необходима, поскольку системы бизнес-аналитики не работают с несогласованными и неточными данными, иначе бизнес-анализ становится бессмысленным.
Процедура очистки данных включает в себя согласование форматов данных, кодирование данных, исключение ненужных атрибутов (например, комментариев), замещение кодов значениями (например, почтового индекса наименованием населенного пункта), комбинирование данных из различных источников под общим ключом (например, собрать все данные о покупателях), обнаружение одинаково поименованных атрибутов, которые содержат различные по смыслу значения.
Очистку данных можно разделить на следующие типы:
- конвертация и нормализация данных (приведение к одинаковому кодированию текста, форматам даты и т. д.);
- стандартизация написания имен, представления адресов, устранение дубликатов;
- стандартизация наименований таблиц, индексов и т.д.;
- очистка, основанная на бизнес-правилах предметной области.
Процедуры очистки также включают в себя создание меток статуса фактов в таблицах измерения (нормальный, ненормальный, невозможный, выходящий за границы, анализируемый или нет и т.д.), распознавание случайных и зашумленных значений (замещение их NULL-значением или оценкой), унификация использования NULL-значений, маркирование фактов с изменившимся статусом (например, покупатель аннулировал контракт), агрегирование фактов и т.п.
Загрузка данных
Основная цель процесса загрузки данных состоит в быстрой загрузке данных в ХД. Отметим некоторые особенности выполнения процесса загрузки данных в ХД.
Во-первых, загрузка данных, основанная на использовании команд обновления SQL, является медленной. Каждая команда SQL выполняется СУБД по определенному плану выполнения, и ее обработка включает выполнение нескольких фаз. Поэтому загрузка с помощью встроенных в СУБД средств импорта/экспорта является предпочтительной.
Во-вторых, индексы таблиц загружаются медленно. Во многих случаях целесообразно удалить индекс и построить его заново.
В-третьих, следует максимально использовать параллелизм при загрузке данных. Измерения могут производиться одновременно с фактами и секциями таблиц. Аналогично факты и секции таблиц могут загружаться одновременно с измерениями.
Следует заметить, что при загрузке данных должна быть гарантирована ссылочная целостность данных, а агрегаты должны быть построены и загружены одновременно с подробными данными.
Настройка производительности загрузки данных в ХД выполняется администратором ХД с помощью набора процедур, предусмотренных используемой СУБД.
Таким образом, мы рассмотрели в общих чертах основные элементы ETL-процесса. Теперь разберем, как проектировать ETL-процессы.
Проектирование процессов преобразования данных с помощью CASE-инструментов
В компьютерных системах организации информация хранится в различных БД систем оперативной обработки данных, корпоративных приложениях и ХД. Для использования этой информации необходима ее систематизация. Систематизация информации приводит к решению задач комбинирования информации из различных источников, преобразованию ее к единому формату для производства корпоративной отчетности и интеллектуального анализа данных.
Для решения поставленной выше задачи используются две технологии – технология ETL-процессов и технология процессов интеграции данных, или технология EII- (Enterprise Information Integration) процессов.
Как уже указывалось в этой лекции, ETL является процессом в складировании данных, который выполняет три функции в одной программной среде: чтение данных из определенных источников ( извлечение ), преобразование данных в соответствии с принятыми соглашениями (преобразование) и запись преобразованных данных в источник назначения ( загрузка ).
EII комбинирует необработанные данные посредством управления и организации запросов к различным системам без предварительной агрегации контента. Полученные данные не помещаются, как правило, на хранение в какие-либо БД или ХД.
CASE-инструменты предоставляют графическую среду для моделирования и документирования ETL- и EII-процессов. В CASE PowerDesigner для этого служит модель движения данных (Information Liquidity Model, или ILM).
ILM предоставляет проектировщику ХД средства моделирования и анализа преобразования данных как на общем уровне рассмотрения, так и на детальном уровне рассмотрения.
-
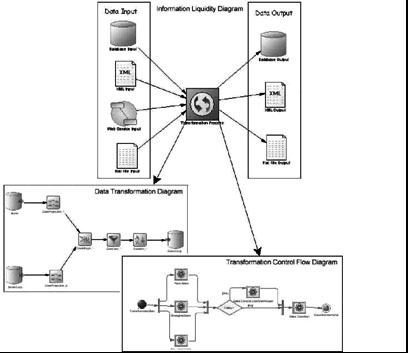
Диаграмма движения данных (Information liquidity diagram) - это диаграмма высокого уровня, которая позволяет моделировать преобразование данных посредством определения:
- входных источников данных (БД, XML-документов, бизнес-процессов, неструктурированных файлов);
- процесса преобразования (Transformation process), позиции, где преобразования выполняются. Процесс преобразования включает в себя набор диаграмм преобразования (transformation diagrams), которые описывают преобразования данных на более детальном уровне;
- выходных источников данных (БД, XML-документов, неструктурированных файлов).
- Диаграмма преобразования данных (Data transformation diagram) - это диаграмма низкого уровня, которая позволяет моделировать конкретные задачи преобразования посредством определения того, как данные извлекаются из входного источника данных, как преобразуются и как загружаются в выходной источник данных.
- Диаграмма управления преобразованием (Transformation control flow diagram) - это диаграмма низкого уровня модели, которая позволяет определить последовательность выполнения серии задач преобразования.
На рис. 15.6 приведен пример того, как могут быть связаны входные и выходные источники данных на высоком уровне и как преобразования моделируются на диаграммах более низкого уровня.
Моделирование движения данных (Information Liquidity Modeling)
Движение данных — один из главных вопросов для любой организации. Моделирование движения данных позволяет определить в модели, где данные генерируются, где загружаются в систему и как они преобразуются в процессе их использования.
PowerDesigner Information Liquidity Model (ILM) является графическим инструментом моделирования движения данных, который позволяет построить модели:
- репликации данных (Data replication) – данные реплицируются из БД источника в БД назначения посредством механизма репликации, такого как Replication Server;
- преобразования данных (Data transformation) – данные из различных источников объединяются для того, чтобы быть извлеченными, преобразованными и загруженными в другой источник посредством процесса ETL (Extract Transform and Load) и EII (Enterprise Information Integration).
Теперь построим модель движения данных (ILM), содержащую диаграмму движения данных (Information Liquidity Diagrams), диаграмму управления преобразованием (Transformation Control Flow Diagrams) и диаграммы преобразования данных (Data Transformation Diagrams), и создадим тем самым модель ETL-процесса.
Создание ILM-модели
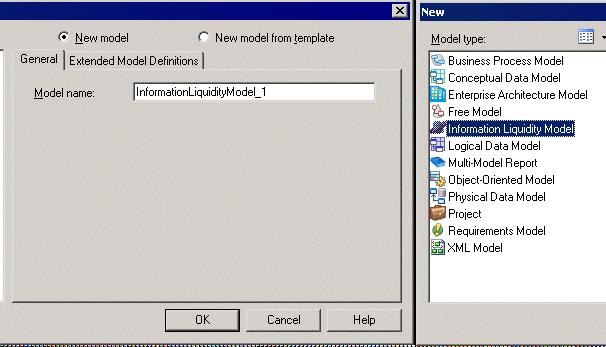
Для того чтобы создать ILM-модель, необходимо выполнить следующую последовательность действий.
- Выбрать пункт меню File -> New
В результате на экране будет показано диалоговое окно, как на рис. 15.7.
- В качестве типа модели выберите из списка моделей Information Liquidity Model.
- Установите поле "Новая модель" ( New Model ) для создания новой стандартной модели.
- В текстовом поле "Имя модели" ( Model Name ) наберите имя модели.
- Щелкните правой кнопкой мыши на кнопке OK.
Таким образом, ILM-модель создана. Теперь ее нужно наполнить диаграммами.
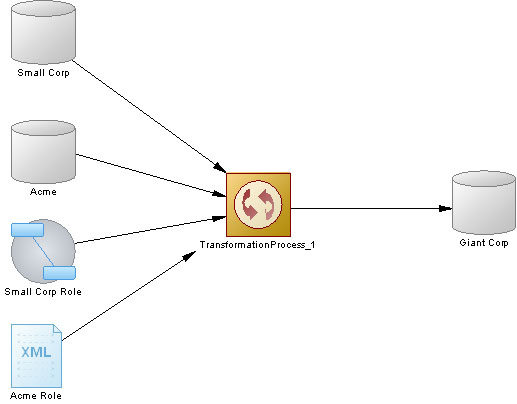
Создадим диаграмму преобразования. Диаграмма преобразования является диаграммой высокого уровня для документирования ETL- и EII-процессов. На ней показываются входные и выходные источники данных, вовлекаемые в процесс преобразования. Источники связываются процессом преобразования, которое определяется на последующих диаграммах преобразования данных.
Предположим, в наше ХД Giant Corp данные поступают из следующих источников: двух оперативных БД системы организации Small Corp и Acme, модели бизнес-процессов Small Corp Role и XML-модели Acme Role.
С помощью палитры инструментов ( рис. 15.8) разметим объекты модели.
| Действие | Пиктограмма |
|---|---|
| три источника данных типа БД | |
| один источник данных типа "XML-документ" | |
| один источник данных типа "Бизнес-процесс" | |
| установим "Процесс преобразования" |
Установим связи между ними с помощью стрелок и таким образом получим диаграмму преобразования, как показано на рис. 15.9.
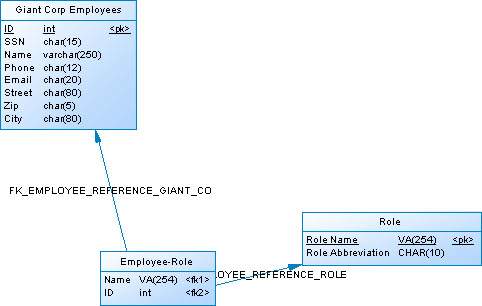
Теперь необходимо связать объекты диаграммы с описанием источников данных. Пусть для нашего примера БД Small Corp имеет схему, как показано на рис. 15.10, БД Small Corp — схему, как на рис. 15.11, ХД Giant Corp — как на рис. 15.12, Acme Role XML-документ имеет модель, как показано на рис. 15.13.
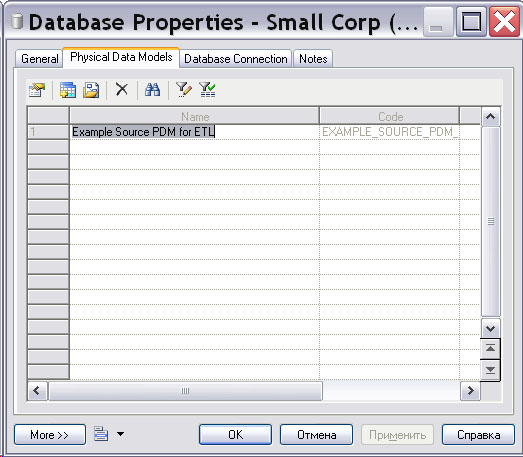
Покажем на примере БД Small Corp, как связать объект диаграммы с описанием источника данных. Дважды щелкнем левой кнопкой на пиктограмме объекта, на панели " Database property sheet " откроем вкладку " Physical Data Models ". Щелкнем кнопкой мыши на пиктограмме " Add Physical Data Models ", откроется список моделей. Выберем из списка соответствующую модель и щелкнем кнопкой мыши на ОК (см. рис. 15.14). Связь установлена.
Владислав Нагорный
Лариса Парфенова
|
1) Можно ли экстерном получить второе высшее образование "Программная инженерия" ? 2) Трудоустраиваете ли Вы выпускников? 3) Можно ли с Вашим дипломом поступить в аспирантуру?
|