

|
Reference = add reference, в висуал студия 2010 не могу найти в вкладке Solution Explorer, Microsoft.Xna.Framework. Его нету. |
Опубликован: 28.04.2009 | Доступ: свободный | Студентов: 1865 / 121 | Оценка: 4.36 / 4.40 | Длительность: 16:40:00
Темы: Компьютерная графика, Программирование, Игры
Специальности: Программист
Лекция 2:
Визуализация примитивов
2.3. Введение в HLSL
В этом разделе мы познакомимся с языком High Level Shader Language (язык высокого уровня для программирования шейдеров), или сокращенно HLSL. HLSL используется для программирования вершинных и пиксельных процессоров графического ускорителя. Программа для вершинного процессора называется вершинным шейдером, а для пиксельного процессора - пиксельным шейдером. Поддержка шейдеров впервые появилась в 8-й версии DirectX. Правда шейдеры DirectX 8 имели множество ограничений и программировались на низкоуровневом ассемблеро-подобном языке, однако в 9-й версии DirectX возможности шейдеров значительно возросли, что привело к появлению надобности в языках высокого уровня. Было создано несколько языков высокого уровня для написания шейдеров DirectX5Например, NVIDIA Cg , однако стандартом де-факто стал язык HLSL, входящий в состав DirectX 9. В XNA Framework шейдеры так же пишутся на языке HLSL, а сам XNA Framework при работе с шейдерами на платформе Windows в значительной степени опирается на функциональность DirectX.
Так язык HLSL тесно связан с архитектурой графического процессора, мы начнем этот раздел с знакомства с основами архитектуры современного графического процессора.
2.3.1. Графический конвейер
В разделе 2.2 вы получили представлении о визуализации примитивов средствами XNA Framework. При этом собственно процесс визуализации изображения (метод GraphicsDevice.DrawUserPrimitives ) оставался для нас черным ящиком. Настало время наверстать упущенное. Итак, при вызове метода GraphicsDevice.DrawUserPrimitives вершины из графического буфера поступают на обработку в графический конвейер XNA Framework, представляющий собой последовательность ступеней (простых операций), выполняемых над вершинами в определенном порядке (рисунок 2.2). Рассмотрим эти ступени в порядке выполнения:
- В начале вершины обрабатываются вершинным процессором по программе, называемой вершинным шейдером. На выходе из вершинного процессора получаются так называемые трансформированные (преобразованные) вершины. К вершинам могут быть "привязаны" различные параметры: цвет вершины, текстурные координаты6Текстурные координаты будут рассмотрены в разделе 5.x. и так далее. Координаты трансформированных вершин задаются в логической системе однородных координат, называемой clip space. Однородные координаты вершины определяются четырьмя числами: (x, y, z, w). Перевод однородных координат в обычные геометрические осуществляется путем деления первых трех компонентов на четвертый компонент w: (x/w, y/w, z/w. Например, вершине с однородными координатами (1, 2, 3, 4) в трехмерном пространстве соответствует точка с координатами (1/4, 2/4, 3/4) = (0.25,0.5,0.75) Использование четвертого компонента обусловлено рядом особенностей алгоритмов визуализации трехмерных изображений, используемых в 3D графике. При визуализации двухмерных изображений компонент w обычно полагают равным 1. В этом случае нижнему левому углу клиентской области формы соответствует точка с координатами (-1, -1, 0, 1), правому верхнему углу клиентской области - (1, 1, 0, 1), а центру клиентской области - соответственно (0, 0, 0, 1).
-
На следующей ступени графического конвейера видеокарта производит преобразование координат вершины из логической системы координат в оконную. По-умолчанию координаты трансформируются таким образом, чтобы растянуть изображение на всю поверхность элемента управления. В большинстве случаев этот процесс полностью прозрачен для приложения.
Примечание
DirectX позволяет программисту задавать координаты вершин в оконных координатах. В этом случае, при вызове метода Device.DrawUserPrimitives вершины сразу поступают на третью стадию графического конвейера, минуя первую и вторую стадии. Managed DirectX и XNA Framework Beta 1 позволяют задавать координаты в оконной системе координат, однако начиная с XNA Framework Beta 2 эта функциональность почему-то пропала. По видимости, это обусловлено стремлением сделать XNA Framework как можно более платформо-независимым.
- Далее идет сборка примитивов. На этой стадии вершины объединяются в примитивы. Тип примитивов определяется первым параметром метода GraphicsDevice.DrawUserPrimitives. Так при использовании параметра PrimitiveType.TriangleStrip вершины трактуются, как опорные точки (вершины) полосы треугольников. При этом каждый треугольник из полосы является независимым примитивов и обрабатывается независимо от других треугольников этой полосы. Полосы треугольников подробно будут рассмотрены в разделе 2.6.3.
- Затем происходит растеризация примитивов – преобразование каждого примитива в набор пикселей экрана. Параметры внутренних пикселей примитива (например, цвет) определяются путем интерполяции соответствующих параметров вершин вдоль поверхности примитива. Как мы увидим в следующих разделах, благодаря этой интерполяции при закраске треугольника с разноцветными вершинами образуются красивые цветовые переходы.
-
Следующий этап – обработка пикселей пиксельным процессором с использованием программы, называемой пиксельным шейдером. На вход пиксельному процессору подаются параметры пикселя (цвет, текстурные координаты и т.д.), полученные путем интерполяции соответствующих вершинных параметров вдоль поверхности примитива. После обработки входных параметров, пиксельный процессор возвращает цвет пикселя.
Технические подробности
В современных графических процессорах имеется массив вершинных и пиксельных процессоров, что позволяет им одновременно обрабатывать несколько вершин и пикселей. Так графический процессор NV40 корпорации NVIDIA, используемый в видеокартах семейства GeForce 6800, имеет 6 вершинных и 16 пиксельных процессоров, соответственно, он может параллельно обрабатывать до 6-ти вершин и 16-ти пикселей.
- Полученные цвета пикселей заносятся в кадровый буфер. При этом возможно выполнение некоторой простой постобработки изображения вроде смешивания цветов при эффекте полупрозрачности.
В заключении стоит отметить, что этот логический конвейер DirectX не обязательно соответствует физической организации видеокарты. К примеру, видеокарта NVIDIA GeForce 8800 GTX, основанная на GPU G80, содержит 8 универсальных блоков, которые могут выполнять как вершинные, так и пиксельные шейдеры .
После прочтения этого раздела у вас, возможно, сложились несколько сумбурные представления о графическом конвейере. Ничего страшного – в следующем разделе вы познакомитесь с языком HLSL и напишете несколько шейдеров, после чего все встанет на свои места.
|
Дополнительная информация Все современные графические подсистемы построены по принципу конвейера. Идея конвейера, впервые реализованная Генри Фордом, заключается в следующем: если сложный процесс разбить на последовательность простых операций (конвейер), то на выходе конвейера мы получим производительность равную производительности самой медленной операции в этой цепочке. В качестве примера конвейера рассмотрим процесс производства популярных процессоров AMD Athlon. Создание одного процессора занимает около двух месяцев. Соответственно, при классической организации производственного процесса одно подразделение может выпускать около шести процессоров в год. Однако на современных фабриках AMD производственный процесс разбивается на 400 стадий. В процессе производства каждый будущий процессор проходит через все эти 400 стадий. Как только процессор проходит текущую стадию производства, на его место приходит следующий. В итоге, на различных стадиях производства одновременно может находиться до 400 процессоров. В итоге, на выходе конвейера получается производительность труда порядка 400 процессоров в два месяца или 2400 процессоров в год. Иными словами производительность труда вырастает примерно в 400 раз. Стороннему наблюдателю может показаться, что за день один конвейер производит около 7-ми процессоров (400/60). Но в реальности, между поступлением заготовки процессора и выходом готового процессора по-прежнему проходит два месяца. Это явление получило название латентность конвейера. При нормальном функционировании конвейера на это обстоятельство можно не обращать внимания; однако в случае неполадок латентность конвейера не замедлит проявиться. Предположим, что была обнаружена и исправлена очень опасная ошибка в архитектуре процессора, после чего исправленная версия процессора немедленно поступила в производство. Но, не смотря на всю оперативность исправления ошибки, первые исправленные образцы процессоров выйдут с конвейера лишь через два месяца. А ведь подобная задержка может принести фирме заметные убытки… Другое следствие латентности – низкая эффективность конвейера при производстве небольших партий процессоров. К примеру, при производстве одного процессора темп производства будет равен 0.017 процессоров в день (один процессор за 60 дней), при производстве 28 процессоров – 0.44 процессора в день, при 100 процессорах - уже 1.33 процессоров в день и т.д. Более-менее, нормальный темп будет достигнут только при производстве партии из нескольких тысяч процессоров (рисунок 2.3). К слову, графический конвейер не является исключением из правил. Он также малоэффективен при визуализации небольшого количества примитивов. Поэтому для эффективного использования графического конвейера программист должен стараться минимизировать количество вызовов метода GraphicsDevice.DrawUserPrimitives, визуализируя за один присест как можно больше примитивов. |
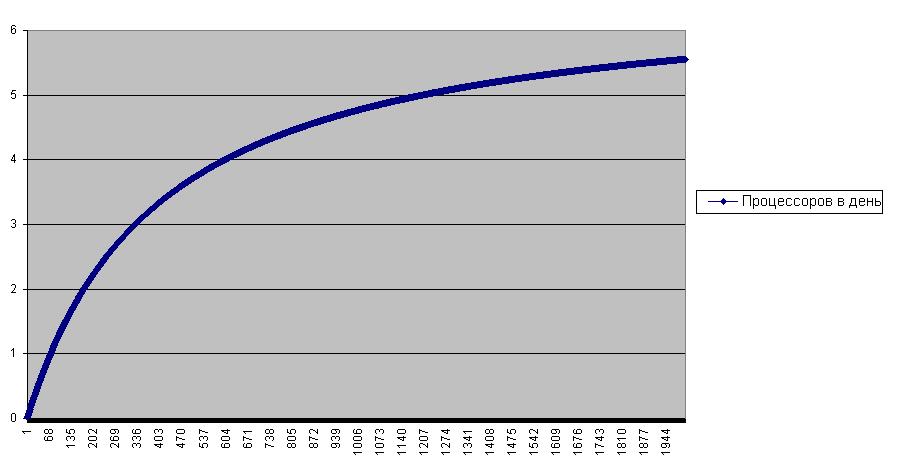
увеличить изображение
Рис. 2.3. Зависимость производительности конвейера от количества выпускаемых процессоров. Производительность оценивается по числу процессоров, выпускаемых в среднем за сутки
2.3.2. Язык HLSL
В начале XXI века корпорация 3dfx работала над революционным GPU Rampage, имеющим на борту массив вершинных и пиксельных процессоров. Для программирования этих процессоров Microsoft в тесном сотрудничестве с 3dfx разработала два похожих ассемблеро-подобных языка, которые были включены в DirectX 8. Язык для программирования вершинных процессоров получил название Vertex Shader 1.0 (VS 1.0), а язык для программирования пиксельных процессоров – Pixel Shader 1.0 (PS 1.0). Соответственно, программы, написанные на этих языках, стали называться вершинными и пиксельными шейдерами7Название шейдер ( shader ) обусловлено применением первых вершинных и пиксельных процессоров преимущественно для более точной передачи игры света и тени ( shade ) на поверхности объектов . К сожалению, графический процессор Rampage так и не поступил в массовое производство по финансовым причинам: компания 3dfx была объявлена банкротом и вскоре куплена NVIDIA, а проект Rampage закрыт.
Примечание
Если быть более точным, зачатки пиксельных шейдеров8Эти шейдеры получили неофициальное обозначение Pixel Shader 0.5 впервые появились в GPU NV10 (1999 год). Однако по ряду причин Microsoft не захотела включить поддержку этих шейдеров в DirectX. В результате, с точки зрения DirectX -программиста, в NV10 отсутствует какая-либо поддержка шейдеров. Единственная возможность задействовать шейдеры NV10 – воспользоваться API OpenGL.
Первым действительно массовым GPU с вершинными и пиксельными процессорами стал NV20 (NVIDIA GeForce3), появившийся в 2001 году. Для программирования вершинных и пиксельных процессоров NV20 корпорация Microsoft совместно с NVIDIA разработала языки Vertex Shader 1.1 и Pixel Shader 1.1, являющиеся расширенными версиями Vertex Shader 1.0 и Pixel Shader 1.0. Вскоре после NV20 вышел NV25 (GeForce4) , функциональность пиксельных процессоров которого была несколько расширена.
Соответственно язык Pixel Shader 1.1 был обновлен до версии 1.328. Потом появился процессор GPU R200 (Radeon 8500) корпорации ATI и язык Pixel Shader 1.4, затем R300 (Radeon 9700 Pro) с Vertex Shader 2.0 и Pixel Shader 2.0 и так далее.
В итоге к началу 2002-го года на рынке творилась полная неразбериха среди языков программирования шейдеров. К счастью Microsoft предвидела подобный поворот, и поэтому заранее сделала языки Vertex Shader и Pixel Shader независимыми от системы команд графического процессора. Фактически каждая версия языка Vertex/Pixel Shader является языком программирования для некоторого виртуального процессора, приближенного к некоторому реальному прототипу. Компиляция шейдера в систему команд физического процессора происходит непосредственно перед загрузкой шейдера в GPU. Таким образом, языки Vertex Shader и Pixel Shader являются аналогами языка IL в .NET.
Независимость языков Vertex Shader и Pixel Shader от системы команд физического процессора теоретически позволяет GPU выполнять любой ассемблерный код, независимо о версии шейдера.
Например, GPU R200 корпорации ATI наряду с родными Pixel Shader 1.4 может выполнять Pixel Shader 1.0, Pixel Shader 1.1, Pixel Shader 1.2 и Pixel Shader 1.3. Это достигается путем перекомпиляции чужеродных шейдеров в родной код. К сожалению, обратное преобразование не всегда возможно. Например, R200 не может выполнять Pixel Shader 2.0, так как программа, использующая продвинутые возможности этой версии шейдеров не может быть втиснута в прокрустово ложе архитектуры R200.
По мере роста возможностей GPU программы для вершинных и пиксельных процессоров становились все сложение и сложнее. Например, если в Pixel Shader 1.1 длина программы не могла превышать 16 ассемблерных команд, то в Pixel Shader 2.0 максимально возможное число ассемблерных инструкций превысило сотню. Соответственно возрастала трудоемкость разработки и поддержки шейдеров с использованием ассемблера-подобного языка. Таким образом, возникла реальная потребность в переходе на языки программирования шейдеров высокого уровня.
В 2002 году Microsoft выпустила высокоуровневый язык программирования шейдеров High Level Shader Language (HLSL). HLSL – это язык программирования высокого уровня, предназначенный для написания программ (шейдеров) для вершинных и пиксельных процессоров. HLSL является C-подобным языком программирования с многочисленными заимствованиями из C++ и C#. В тоже время в HLSL имеется ряд важных расширений, полезных при программировании графического процессора. Программа, написанная на HLSL, компилируется в один из ассемблеро-подобных языков DirectX. Таким образом, процесс компиляции HLSL программы очень напоминает компиляцию C# -программы сначала на промежуточный язык ( IL ), а затем в машинный для конкретного центрального процессора (рисунок 2.4).
Самой крупной логической единицей HLSL является эффект ( Effect ), хранящийся в отдельном текстовом файле с расширением .fx. В принципе, эффект можно считать аналогом материала в 3DS MAX. Каждый эффект состоит из одной или нескольких техник ( technique ). Техника – это способ визуализации материала. Например, эффект визуализации мраморного материала может содержать три техники для различных графических процессоров: технику High для ускорителей класса High End, Medium для ускорителей среднего класса, и Low – максимальная производительность при низком качестве изображения9Для программирования пиксельных процессоров NV25 (GeForce4) планировалось использовать язык Pixel Shader 1.2. Однако после выхода NV25 оказалась, что его функциональность несколько шире, чем предполагалось. Соответственно язык Pixel Shader 1.2 оказался не удел, и вскоре был обновлен до версии 1.3.. Каждой технике сопоставлен пиксельный и вершинный шейдер, при этом несколько техник могут использовать общий шейдер.
Количество техник и их названия могут быть произвольными.
Андрей Леонов