|
Подскажите, пожалуйста, планируете ли вы возобновление программ высшего образования? Если да, есть ли какие-то примерные сроки? Спасибо! |
Опубликован: 20.12.2010 | Доступ: свободный | Студентов: 0 / 0 | Оценка: 4.27 / 3.91 | Длительность: 39:39:00
ISBN: 978-5-9963-0353-3
Тема: Базы данных
Специальности: Администратор баз данных
Лекция 19:
Проектирование кубов данных
Аннотация: В настоящей лекции рассматриваются основы проектирования кубов данных для OLAP-хранилищ данных. На примере показана методика построения куба данных с помощью CASE-инструмента.
Ключевые слова: куб данных, olap-хранилища данных, Измерение, факт, атрибут, иерархия, метрика, многомерная диаграмма, OLAP, программный продукт, язык программирования, доступ, аналитик, информация, представление, очередь, БД, метаданные, трансформация данных, анализ данных, СУБД, вычисление, сервер, SQL, soft, excel, средства разработки, decision, cube, элементы управления, статистика, приложение, время выполнения, Oracle, server, analysis, crystal, SAS, базы данных, multidimensional, hybrid, хранение данных, unbalanced, rag, pivot, pivot table, CASE, киоски данных, коммерческая информация, ассоциация, population, отображение, источник данных, запрос, связь, mapping, editor, меню, скрипт, физические модели данных, команда
Цель лекции
Изучив материал настоящей лекции, вы будете знать:
- что такое куб данных в OLAP-хранилище данных ;
- как проектировать куб данных для OLAP-хранилищ данных ;
- что такое измерение куба данных ;
- как факт связан с кубом данных ;
- что такое атрибуты измерения ;
- что такое иерархия ;
- что такое метрика куба данных ;
и научитесь:
- строить многомерные диаграммы ;
- проектировать простые многомерные диаграммы.
Литература: [14], [28], [31], [42].
Введение
Технология OLAP — это не отдельно взятый программный продукт, не язык программирования. Если постараться охватить OLAP во всех его проявлениях, то это совокупность концепций, принципов и требований, лежащих в основе программных продуктов, облегчающих аналитикам доступ к данным.
Аналитики являются основными потребителями корпоративной информации. Задача аналитика состоит в том, чтобы находить закономерности в больших массивах данных. Поэтому аналитик не будет обращать внимания на отдельно взятый факт, что в определенный день покупателю Иванову была продана партия шариковых авторучек, — ему нужна информация о сотнях и тысячах подобных событий. Одиночные факты в ХД могут заинтересовать, к примеру, бухгалтера или начальника отдела продаж, в компетенции которого находится сопровождение определенного контракта. Аналитику одной записи недостаточно — ему, например, может понадобиться информация обо всех контрактах точки продажи за месяц, квартал или год. Аналитика может не интересовать ИНН покупателя или его телефон, — он работает с конкретными числовыми данными, что составляет сущность его профессиональной деятельности.
Централизация и удобное структурирование — это далеко не все, что нужно аналитику. Ему требуется инструмент для просмотра, визуализации информации. Традиционные отчеты, даже построенные на основе единого ХД, лишены, однако, определенной гибкости. Их нельзя "покрутить", "развернуть" или "свернуть", чтобы получить необходимое представление данных. Чем больше "срезов" и "разрезов" данных аналитик может исследовать, тем больше у него идей, которые, в свою очередь, для проверки требуют все новых и новых "срезов". В качестве такого инструмента для исследования данных аналитиком выступает OLAP.
Хотя OLAP и не представляет собой необходимый атрибут ХД, он все чаще и чаще применяется для анализа накопленных в этом ХД сведений.
Оперативные данные собираются из различных источников, очищаются, интегрируются и складываются в ХД. При этом они уже доступны для анализа при помощи различных средств построения отчетов. Затем данные (полностью или частично) подготавливаются для OLAP-анализа. Они могут быть загружены в специальную БД OLAP или оставлены в реляционном ХД. Важнейшим элементом использования OLAP являются метаданные, т. е. информация о структуре, размещении и трансформации данных. Благодаря им обеспечивается эффективное взаимодействие различных компонентов хранилища.
Таким образом, OLAP можно определить как совокупность средств многомерного анализа данных, накопленных в ХД. Теоретически средства OLAP можно применять и непосредственно к оперативным данным или их точным копиям. Однако при этом существует риск подвергнуть анализу данные, которые для этого анализа не пригодны.
OLAP на клиенте и на сервере
В основе OLAP лежит многомерный анализ данных. Он может быть произведен с помощью различных средств, которые условно можно разделить на клиентские и серверные OLAP-средства.
Клиентские OLAP-средства представляют собой приложения, осуществляющие вычисление агрегатных данных (сумм, средних величин, максимальных или минимальных значений) и их отображение, при этом сами агрегатные данные содержатся в кэше внутри адресного пространства такого OLAP-средства.
Если исходные данные содержатся в настольной СУБД, вычисление агрегатных данных производится самим OLAP-средством. Если же источник исходных данных — серверная СУБД, многие из клиентских OLAP-средств посылают на сервер SQL-запросы, содержащие оператор GROUP BY, и в результате получают агрегатные данные, вычисленные на сервере.
Как правило, OLAP-функциональность реализована в средствах статистической обработки данных (из продуктов этого класса на российском рынке широко распространены продукты компаний Stat Soft и SPSS) и в некоторых электронных таблицах. В частности, неплохими средствами многомерного анализа обладает Microsoft Excel 2000. С помощью этого продукта можно создать и сохранить в виде файла небольшой локальный многомерный OLAP-куб и отобразить его двух- или трехмерные сечения.
Многие средства разработки содержат библиотеки классов или компонентов, позволяющие создавать приложения, реализующие простейшую OLAP-функциональность (такие, например, как компоненты Decision Cube в Borland Delphi и Borland C++Builder). Помимо этого многие компании предлагают элементы управления ActiveX и другие библиотеки, реализующие подобную функциональность.
Отметим, что клиентские OLAP-средства применяются, как правило, при малом числе измерений (обычно рекомендуется не более шести) и небольшом разнообразии значений этих параметров — ведь полученные агрегатные данные должны умещаться в адресном пространстве подобного средства, а их количество растет экспоненциально при увеличении числа измерений. Поэтому даже самые примитивные клиентские OLAP-средства, как правило, позволяют произвести предварительный подсчет объема требуемой оперативной памяти для создания в ней многомерного куба.
Многие (но не все) клиентские OLAP-средства позволяют сохранить содержимое кэша с агрегатными данными в виде файла, что, в свою очередь, позволяет не производить их повторное вычисление. Отметим, что нередко такая возможность используется для отчуждения агрегатных данных с целью передачи их другим организациям или для публикации. Типичным примером таких отчуждаемых агрегатных данных является статистика заболеваемости в разных регионах и в различных возрастных группах, которая является открытой информацией, публикуемой министерствами здравоохранения различных стран и Всемирной организацией здравоохранения. При этом собственно исходные данные, представляющие собой сведения о конкретных случаях заболеваний, являются конфиденциальными данными медицинских учреждений и ни в коем случае не должны попадать в руки страховых компаний и тем более становиться достоянием гласности.
Идея сохранения кэша с агрегатными данными в файле получила свое дальнейшее развитие в серверных OLAP-средствах, в которых сохранение и изменение агрегатных данных, а также поддержка содержащего их хранилища осуществляются отдельным приложением или процессом, называемым OLAP-сервером. Клиентские приложения могут запрашивать подобное многомерное хранилище и в ответ получать те или иные данные. Некоторые клиентские приложения могут также создавать такие хранилища или обновлять их в соответствии с изменившимися исходными данными.
Преимущества применения серверных OLAP-средств по сравнению с клиентскими OLAP-средствами сходны с преимуществами применения серверных СУБД по сравнению с настольными: в случае применения серверных средств вычисление и хранение агрегатных данных происходит на сервере, а клиентское приложение получает лишь результаты запросов к ним, что позволяет в общем случае снизить сетевой трафик, время выполнения запросов и требования к ресурсам, потребляемым клиентским приложением. Отметим, что средства анализа и обработка данных масштаба предприятия, как правило, базируются именно на серверных OLAP-средствах, например, таких как Oracle Express Server, Microsoft SQL Server 2000 Analysis Services, Hyperion Essbase, продуктах компаний Crystal Decisions, Business Objects, Cognos, SAS Institute. Поскольку все ведущие производители серверных СУБД производят (либо лицензировали у других компаний) те или иные серверные OLAP-средства, выбор их достаточно широк, и почти во всех случаях можно приобрести OLAP-сервер того же производителя, что и у самого сервера баз данных.
Отметим, что многие клиентские OLAP-средства (в частности, Microsoft Excel 2003, Seagate Analysis и др.) позволяют обращаться к серверным OLAP-хранилищам, выступая в этом случае в роли клиентских приложений, выполняющих подобные запросы. Помимо этого имеется немало продуктов, представляющих собой клиентские приложения к OLAP-средствам различных производителей.
Технические аспекты многомерного хранения данных
В многомерных ХД содержатся агрегатные данные различной степени подробности, например, объемы продаж по дням, месяцам, годам, по категориям товаров и т.п. Цель хранения агрегатных данных — сократить время выполнения запросов, поскольку в большинстве случаев для анализа и прогнозов интересны не детальные, а суммарные данные. Поэтому при создании многомерной базы данных всегда вычисляются и сохраняются некоторые агрегатные данные.
Отметим, что сохранение всех агрегатных данных не всегда оправданно. Дело в том, что при добавлении новых измерений объем данных, составляющих куб, растет экспоненциально (иногда говорят о "взрывном росте" объема данных). Если говорить более точно, степень роста объема агрегатных данных зависит от количества измерений куба и членов измерений на различных уровнях иерархий этих измерений. Для решения проблемы "взрывного роста" применяются разнообразные схемы, позволяющие при вычислении далеко не всех возможных агрегатных данных достичь приемлемой скорости выполнения запросов.
Как исходные, так и агрегатные данные могут храниться либо в реляционных, либо в многомерных структурах. Поэтому в настоящее время применяются три способа хранения данных.
- MOLAP (Multidimensional OLAP) — исходные и агрегатные данные хранятся в многомерной базе данных. Хранение данных в многомерных структурах позволяет манипулировать данными как многомерным массивом, благодаря чему скорость вычисления агрегатных значений одинакова для любого из измерений. Однако в этом случае многомерная база данных оказывается избыточной, так как многомерные данные полностью содержат исходные реляционные данные.
- ROLAP (Relational OLAP) — исходные данные остаются в той же реляционной базе данных, где они изначально и находились. Агрегатные же данные помещают в специально созданные для их хранения служебные таблицы в той же базе данных.
- HOLAP (Hybrid OLAP) — исходные данные остаются в той же реляционной базе данных, где они изначально находились, а агрегатные данные хранятся в многомерной базе данных.
Некоторые OLAP-средства поддерживают хранение данных только в реляционных структурах, некоторые — только в многомерных. Однако большинство современных серверных OLAP-средств поддерживают все три способа хранения данных. Выбор способа хранения зависит от объема и структуры исходных данных, требований к скорости выполнения запросов и частоты обновления OLAP-кубов.
Отметим также, что подавляющее большинство современных OLAP-средств не хранит "пустых" значений (примером "пустого" значения может быть отсутствие продаж сезонного товара вне сезона).
Основные понятия OLAP
Тест FAMSI
Технология комплексного многомерного анализа данных получила название OLAP (On-Line Analytical Processing). OLAP — это ключевой компонент организации ХД. Концепция OLAP была описана в 1993 году Эдгаром Коддом, известным исследователем баз данных и автором реляционной модели данных. В 1995 году на основе требований, изложенных Коддом, был сформулирован так называемый тест FASMI (Fast Analysis of Shared Multidimensional Information) — быстрый анализ разделяемой многомерной информации, включающий следующие требования к приложениям для многомерного анализа:
- Fast (Быстрый) — предоставление пользователю результатов анализа за приемлемое время (обычно не более 5 с), пусть даже ценой менее детального анализа;
- Analysis (Анализ) — возможность осуществления любого логического и статистического анализа, характерного для данного приложения, и его сохранения в доступном для конечного пользователя виде;
- Shared (Разделяемый) — многопользовательский доступ к данным с поддержкой соответствующих механизмов блокировок и средств авторизованного доступа;
- Multidimensional (Многомерный) — многомерное концептуальное представление данных, включая полную поддержку для иерархий и множественных иерархий (это ключевое требование OLAP);
- Information (Информация) — приложение должно иметь возможность обращаться к любой нужной информации, независимо от ее объема и места хранения.
Следует отметить, что OLAP-функциональность может быть реализована различными способами, начиная с простейших средств анализа данных в офисных приложениях и заканчивая распределенными аналитическими системами, основанными на серверных продуктах.
Многомерное представление информации
Кубы
OLAP предоставляет удобные быстродействующие средства доступа, просмотра и анализа деловой информации. Пользователь получает естественную, интуитивно понятную модель данных, организуя их в виде многомерных кубов (Cubes). Осями многомерной системы координат служат основные атрибуты анализируемого бизнес-процесса. Например, для продаж это могут быть товар, регион, тип покупателя. В качестве одного из измерений используется время. На пересечениях осей измерений (Dimensions) находятся данные, количественно характеризующие процесс — меры (Measures). Это могут быть объемы продаж в штуках или в денежном выражении, остатки на складе, издержки и т. п. Пользователь, анализирующий информацию, может "разрезать" куб по разным направлениям, получать сводные (например, по годам) или, наоборот, детальные (по неделям) сведения и осуществлять прочие манипуляции, которые ему придут в голову в процессе анализа.
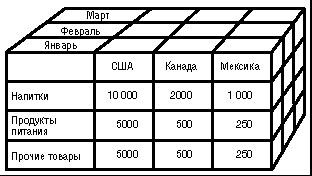
В качестве мер в трехмерном кубе, изображенном на рис. 26.1, использованы суммы продаж, а в качестве измерений — время, товар и магазин. Измерения представлены на определенных уровнях группировки: товары группируются по категориям, магазины — по странам, а данные о времени совершения операций — по месяцам. Чуть позже мы рассмотрим уровни группировки ( иерархии ) подробнее.
"Разрезание" куба
Даже трехмерный куб сложно отобразить на экране компьютера так, чтобы были видны значения интересующих мер. Что уж говорить о кубах с количеством измерений, большим трех. Для визуализации данных, хранящихся в кубе, применяются, как правило, привычные двумерные, т. е. табличные представления, имеющие сложные иерархические заголовки строк и столбцов.
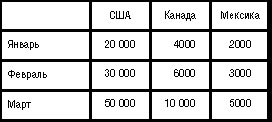
Двумерное представление куба можно получить, "разрезав" его поперек вдоль одной или нескольких осей ( измерений ): мы фиксируем значения всех измерений, кроме двух, — и получаем обычную двумерную таблицу. В горизонтальной оси таблицы (заголовки столбцов) представлено одно измерение, в вертикальной (заголовки строк) — другое, а в ячейках таблицы — значения мер. При этом набор мер фактически рассматривается как одно из измерений: мы либо выбираем для показа одну меру (и тогда можем разместить в заголовках строк и столбцов два измерения ), либо показываем несколько мер (и тогда одну из осей таблицы займут названия мер, а другую — значения единственного "неразрезанного" измерения ).
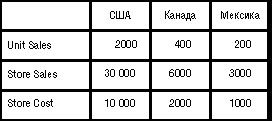
Взгляните на рис. 26.2. Здесь изображен двумерный срез куба для одной меры — Unit Sales (продано штук) и двух "неразрезанных" измерений — Store (Магазин) и Время (Time).
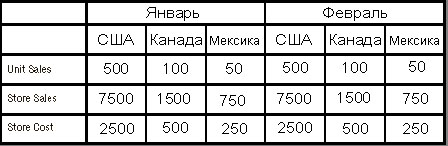
На рис. 26.3 представлено лишь одно "неразрезанное" измерение — Store, но зато отображаются значения нескольких мер — Unit Sales (продано штук), Store Sales (сумма продажи) и Store Cost (расходы магазина).
Двумерное представление куба возможно и тогда, когда "неразрезанными" остаются и более двух измерений. При этом на осях среза (строках и столбцах) будут размещены два или более измерений "разрезаемого" куба — см. рис. 26.4.
Метки
Значения, "откладываемые" вдоль измерений, называются членами или метками (members). Метки используются как для "разрезания" куба, так и для ограничения (фильтрации) выбираемых данных — когда в измерении, остающемся "неразрезанным", нас интересуют не все значения, а их подмножество, например, три города из нескольких десятков. Значения меток отображаются в двумерном представлении куба как заголовки строк и столбцов.
Иерархии и уровни
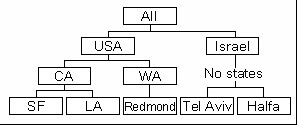
Метки могут объединяться в иерархии, состоящие из одного или нескольких уровней (levels). Например, метки измерения "Магазин" (Store) естественно объединяются в иерархию с уровнями:
В соответствии с уровнями иерархии вычисляются агрегатные значения, например, объем продаж для США (уровень "Country") или для штата Калифорния (уровень "State"). В одном измерении можно реализовать более одной иерархии — скажем, для времени: {Год, Квартал, Месяц, День} и {Год, Неделя, День}.
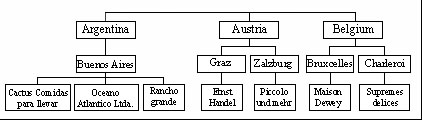
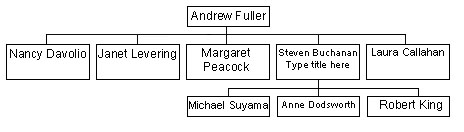
Отметим, что иерархии могут быть сбалансированными (balanced), как, например, иерархия, представленная на рис. 26.5, а также иерархии, основанные на данных типа "дата-время", и несбалансированными (unbalanced). Типичный пример несбалансированной иерархии — иерархия типа "начальник-подчиненный" (ее можно построить, например, используя значения поля Salesperson исходного набора данных из рассмотренного выше примера), как показано на рис. 26.6.
Иногда для таких иерархий используется термин Parent-child hierarchy.
Существуют также иерархии, занимающие промежуточное положение между сбалансированными и несбалансированными (они обозначаются термином ragged — "неровный"). Обычно они содержат такие члены, логические "родители" которых находятся непосредственно на вышестоящем уровне (например, в географической иерархии есть уровни Country, City и State, но при этом в наборе данных имеются страны, не имеющие штатов или регионов между уровнями Country и City ( рис. 26.7)).
Отметим, что несбалансированные и "неровные" иерархии поддерживаются далеко не всеми OLAP-средствами. Например, в Microsoft Analysis Services 2000 поддерживаются оба типа иерархии, а в Microsoft OLAP Services 7.0 — только сбалансированные. Различными в разных OLAP-средствах могут быть и число уровней иерархии, и максимально допустимое число членов одного уровня, и максимально возможное число самих измерений.
Архитектура OLAP-приложений
Все, что говорилось выше про OLAP, по сути, относилось к многомерному представлению данных. То, как данные хранятся, грубо говоря, не волнует ни конечного пользователя, ни разработчиков инструмента, которым клиент пользуется.
Многомерность в OLAP-приложениях может быть разделена на три уровня.
- Многомерное представление данных — средства конечного пользователя, обеспечивающие многомерную визуализацию и манипулирование данными; слой многомерного представления абстрагирован от физической структуры данных и воспринимает данные как многомерные.
- Многомерная обработка — средство (язык) формулирования многомерных запросов (традиционный реляционный язык SQL здесь оказывается непригодным) и процессор, умеющий обработать и выполнить такой запрос.
- Многомерное хранение — средства физической организации данных, обеспечивающие эффективное выполнение многомерных запросов.
Первые два уровня в обязательном порядке присутствуют во всех OLAP-средствах. Третий уровень, хотя и является широко распространенным, не обязателен, так как данные для многомерного представления могут извлекаться и из обычных реляционных структур; процессор многомерных запросов в этом случае транслирует многомерные запросы в SQL-запросы, которые выполняются реляционной СУБД.
Конкретные OLAP-продукты, как правило, представляют собой либо средство многомерного представления данных (OLAP-клиент — например, Pivot Tables в Excel 2000 фирмы Microsoft или ProClarity фирмы Knosys), либо многомерную серверную СУБД (OLAP-сервер — например, Oracle Express Server или Microsoft OLAP Services).
Слой многомерной обработки обычно бывает встроен в OLAP-клиент и/или в OLAP-сервер, но может быть выделен в чистом виде, как, например, компонент Pivot Table Service фирмы Microsoft.
Владислав Нагорный
Лариса Парфенова
|
1) Можно ли экстерном получить второе высшее образование "Программная инженерия" ? 2) Трудоустраиваете ли Вы выпускников? 3) Можно ли с Вашим дипломом поступить в аспирантуру?
|