Московский государственный открытый университет им. В.С. Черномырдина
Опубликован: 22.08.2012 | Доступ: свободный | Студентов: 8986 / 5007 | Оценка: 4.20 / 3.40 | Длительность: 26:36:00
Темы: Экономика, Менеджмент
Специальности: Администратор информационных систем
Теги:
Лекция 11:
Интеллектуальные задачи в экономике
Другие алгоритмы обучения многослойного персептрона
Выше было описано, как с помощью алгоритма обратного распространения осуществляется градиентный спуск по поверхности ошибок. Вкратце дело происходит так: в данной точке поверхности находится направление скорейшего спуска, затем делается прыжок вниз на расстояние, пропорциональное коэффициенту скорости обучения и крутизне склона, при этом учитывается инерция, те есть стремление сохранить прежнее направление движения. Можно сказать, что метод ведёт себя как слепой кенгуру - каждый раз прыгает в направлении, которое кажется ему наилучшим. На самом деле шаг спуска вычисляется отдельно для всех обучающих наблюдений, взятых в случайном порядке, но в результате получается достаточно хорошая аппроксимация спуска по совокупной поверхности ошибок. Существуют и другие алгоритмы обучения MLP, однако все они используют ту или иную стратегию скорейшего продвижения к точке минимума.
В некоторых задачах бывает целесообразно использовать такие - более сложные - методы нелинейной оптимизации. В пакете ST Neural Networks реализованы два подобных метода: методы спуска по сопряженным градиентам и Левенберга -Маркара (Bishop, 1995; Shepherd, 1997), представляющие собой очень удачные варианты реализации двух типов алгоритмов: линейного поиска и доверительных областей.
Алгоритм линейного поиска действует следующим образом: выбирается какое-либо разумное направление движения по многомерной поверхности. В этом направлении проводится линия, и на ней ищется точка минимума (это делается относительно просто с помощью того или иного варианта метода деления отрезка пополам); затем все повторяется сначала. Что в данном случае следует считать "разумным направлением"? Очевидным ответом является направление скорейшего спуска (именно так действует алгоритм обратного распространения). На самом деле этот вроде бы очевидный выбор не слишком удачен. После того, как был найден минимум по некоторой прямой, следующая линия, выбранная для кратчайшего спуска, может "испортить" результаты минимизации по предыдущему направлению (даже на такой простой поверхности, как параболоид, может потребоваться очень большое число шагов линейного поиска). Более разумно было бы выбирать "не мешающие друг другу" направления спуска - так мы приходим к методу сопряженных градиентов (Bishop, 1995).
Идея метода состоит в следующем: поскольку мы нашли точку минимума вдоль некоторой прямой, производная по этому направлению равна нулю. Сопряженное направление выбирается таким образом, чтобы эта производная и дальше оставалась нулевой - в предположении, что поверхность имеет форму параболоида (или, грубо говоря, является "хорошей и гладкой"). Если это условие выполнено, то для достижения точки минимума достаточно будет N эпох. На реальных, сложно устроенных поверхностях по мере хода алгоритма условие сопряженности портится, и тем не менее такой алгоритм, как правило, требует гораздо меньшего числа шагов, чем метод обратного распространения, и дает лучшую точку минимума (для того, чтобы алгоритм обратного распространения точно установился в некоторой точке, нужно выбирать очень маленькую скорость обучения).
Метод доверительных областей основан на следующей идее: вместо того, чтобы двигаться в определенном направлении поиска, предположим, что поверхность имеет достаточно простую форму, так что точку минимума можно найти (и прыгнуть туда) непосредственно. Попробуем смоделировать это и посмотреть, насколько хорошей окажется полученная точка. Вид модели предполагает, что поверхность имеет хорошую и гладкую форму (например, является параболоидом), - такое предположение выполнено вблизи точек минимума. Вдали от них данное предположение может сильно нарушаться, так что модель будет выбирать для очередного продвижения совершенно не те точки. Правильно работать такая модель будет только в некоторой окрестности данной точки, причем размеры этой окрестности заранее неизвестны. Поэтому выберем в качестве следующей точки для продвижения нечто промежуточное между точкой, которую предлагает наша модель, и точкой, которая получилась бы по обычному методу градиентного спуска. Если эта новая точка оказалась хорошей, передвинемся в нее и усилим роль нашей модели в выборе очередных точек; если же точка оказалась плохой, не будем в нее перемещаться и увеличим роль метода градиентного спуска при выборе очередной точки (а также уменьшим шаг). В основанном на этой идее методе Левенберга-Маркара предполагается, что исходное отображение является локально линейным (и тогда поверхность ошибок будет параболоидом).
Метод Левенберга-Маркара (Levenberg, 1944; Marquardt, 1963; Bishop, 1995) - самый быстрый алгоритм обучения из всех, которые реализованы в пакете ST Neural Networks, но, к сожалению, на его использование имеется ряд важных ограничений. Он применим только для сетей с одним выходным элементом, работает только с функцией ошибок сумма квадратов и требует памяти порядка W**2 (где W - количество весов у сети; поэтому для больших сетей он плохо применим). Метод сопряженных градиентов почти так же эффективен, как и этот метод, и не связан подобными ограничениями.
При всем сказанном метод обратного распространения также сохраняет свое значение, причем не только для тех случаев, когда требуется быстро найти решение (и не требуется особой точности). Его следует предпочесть, когда объем данных очень велик, и среди данных есть избыточные. Благодаря тому, что в методе обратного распространения корректировка ошибки происходит по отдельным случаям, избыточность данных не вредит (если, например, приписать к имеющемуся набору данных еще один точно такой же набор, так что каждый случай будет повторяться дважды, то эпоха будет занимать вдвое больше времени, чем раньше, однако результат ее будет точно таким же, как от двух старых, так что ничего плохого не произойдет). Методы же Левенберга-Маркара и сопряженных градиентов проводят вычисления на всем наборе данных, поэтому при увеличении числа наблюдений продолжительность одной эпохи сильно растет, но при этом совсем не обязательно улучшается результат, достигнутый на этой эпохе (в частности, если данные избыточны; если же данные редкие, то добавление новых данных улучшит обучение на каждой эпохе). Кроме того, обратное распространение не уступает другим методам в ситуациях, когда данных мало, поскольку в этом случае недостаточно данных для принятия очень точного решения (более тонкий алгоритм может дать меньшую ошибку обучения, но контрольная ошибка у него, скорее всего, не будет меньше).
Кроме уже перечисленных, в пакете ST Neural Networks имеются две модификации метода обратного распространения - метод быстрого распространения (Fahlman, 1988) и дельта-дельта с чертой (Jacobs, 1988), - разработанные с целью преодолеть некоторые ограничения этого подхода. В большинстве случаев они работают не лучше, чем обратное распространение, а иногда и хуже (это зависит от задачи). Кроме того, в этих методах используется больше управляющих параметров, чем в других методах, и поэтому ими сложнее пользоваться.
Радиальная базисная функция
В предыдущем разделе было описано, как многослойный персептрон моделирует функцию отклика с помощью функций "сигмоидных склонов" - в задачах классификации это соответствует разбиению пространства входных данных посредством гиперплоскостей. Метод разбиения пространства гиперплоскостями представляется естественным и интуитивно понятным, ибо он использует фундаментальное простое понятие прямой линии.
Столь же естественным является подход, основанный на разбиении пространства окружностями или (в общем случае) гиперсферами. Гиперсфера задается своим центром и радиусом. Подобно тому, как элемент MLP реагирует (нелинейно) на расстояние от данной точки до линии "сигмоидного склона", в сети, построенной на радиальных базисных функциях (Broomhead and Lowe, 1988; Moody and Darkin, 1989; Haykin, 1994), элемент реагирует (нелинейно) на расстояние от данной точки до "центра", соответствующего этому радиальному элементу. Поверхность отклика радиального элемента представляет собой гауссову функцию (колоколообразной формы), с вершиной в центре и понижением к краям. Наклон гауссова радиального элемента можно менять подобно тому, как можно менять наклон сигмоидной кривой в MLP (рис.11.13).
Элемент многослойного персептрона полностью задается значениями своих весов и порогов, которые в совокупности определяют уравнение разделяющей прямой и скорость изменения функции при отходе от этой линии.
До действия сигмоидной функции активации уровень активации такого элемента определяется гиперплоскостью, поэтому в системе ST Neural Networks такие элементы называется линейными (хотя функция активации, как правило, нелинейна).
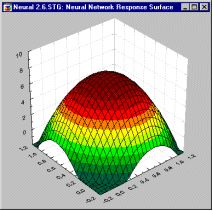
В отличие от них, радиальный элемент задаётся своим центром и "радиусом". Положение точки в N-мерном пространстве определяется N числовыми параметрами, т.е. их ровно столько же, сколько весов у линейного элемента, и поэтому координаты центра радиального элемента в пакете ST Neural Networks хранятся как "веса". Его радиус (отклонение) хранится как "порог". Следует отчетливо понимать, что "веса" и "пороги" радиального элемента принципиально отличаются от весов и порогов линейного элемента, и если забыть об этом, термин может ввести в заблуждение. Радиальные веса на самом деле представляют точку, а радиальный порог - отклонение.
Сеть типа радиальной базисной функции (RBF) имеет промежуточный слой из радиальных элементов, каждый из которых воспроизводит гауссову поверхность отклика. Поскольку эти функции нелинейны, для моделирования произвольной функции нет необходимости брать более одного промежуточного слоя. Для моделирования любой функции необходимо лишь взять достаточное число радиальных элементов. Остается решить вопрос о том, как следует скомбинировать выходы скрытых радиальных элементов, чтобы получить из них выход сети. Оказывается, что достаточно взять их линейную комбинацию (т.е. взвешенную сумму гауссовых функций). Сеть RBF имеет выходной слой, состоящий из элементов с линейными функциями активации (Haykin, 1994; Bishop, 1995).
Сети RBF имеют ряд преимуществ перед сетями MLP. Во-первых, как уже сказано, они моделируют произвольную нелинейную функцию с помощью всего одного промежуточного слоя, и тем самым избавляют нас от необходимости решать вопрос о числе слоев. Во-вторых, параметры линейной комбинации в выходном слое можно полностью оптимизировать с помощью хорошо известных методов линейного моделирования, которые работают быстро и не испытывают трудностей с локальными минимумами, так мешающими при обучении MLP. Поэтому сеть RBF обучается очень быстро (на порядок быстрее MLP).
С другой стороны, до того, как применять линейную оптимизацию в выходном слое сети RBF, необходимо определить число радиальных элементов, положение их центров и величины отклонений. Соответствующие алгоритмы, хотя и работают быстрее алгоритмов обучения MLP, в меньшей степени пригодны для отыскания субоптимальных решений. В качестве компенсации, Автоматический конструктор сети пакета ST Neural Networks сможет выполнить за Вас все необходимые действия по экспериментированию с сетью.
Другие отличия работы RBF от MLP связаны с различным представлением пространства модели: "групповым" в RBF и "плоскостным" в MLP.
Опыт показывает, что для правильного моделирования типичной функции сеть RBF, с ее более эксцентричной поверхностью отклика, требует несколько большего числа элементов. Конечно, можно специально придумать форму поверхности, которая будет хорошо представляться первым или, наоборот, вторым способом, но общий итог оказывается не в пользу RBF. Следовательно, модель, основанная на RBF, будет работать медленнее и потребует больше памяти, чем соответствующий MLP (однако она гораздо быстрее обучается, а в некоторых случаях это важнее).
С "групповым" подходом связано и неумение сетей RBF экстраполировать свои выводы за область известных данных. При удалении от обучающего множества значение функции отклика быстро спадает до нуля. Напротив, сеть MLP выдает более определенные решения при обработке сильно отклоняющихся данных. Достоинство это или недостаток - зависит от конкретной задачи, однако в целом склонность MLP к некритическому экстраполированию результата считается его слабостью. Экстраполяция на данные, лежащие далеко от обучающего множества, - вещь, как правило, опасная и необоснованная.
Сети RBF более чувствительны к "проклятию размерности" и испытывают значительные трудности, когда число входов велико. Как уже говорилось, обучение RBF- сети происходит в несколько этапов. Сначала определяются центры и отклонения для радиальных элементов; после этого оптимизируются параметры линейного выходного слоя.
Расположение центров должно соответствовать кластерам, реально присутствующим в исходных данных. Рассмотрим два наиболее часто используемых метода.
Расположение центров должно соответствовать кластерам, реально присутствующим в исходных данных. Рассмотрим два наиболее часто используемых метода.
Выборка из выборки. В качестве центров радиальных элементов берутся несколько случайно выбранных точек обучающего множества. В силу случайности выбора они "представляют" распределение обучающих данных в статистическом смысле. Однако, если число радиальных элементов невелико, такое представление может быть неудовлетворительным (Haykin, 1994).
Алгоритм K-средних. Этот алгоритм (Bishop, 1995) стремится выбрать оптимальное множество точек, являющихся центроидами кластеров в обучающих данных. При K радиальных элементах их центры располагаются таким образом, чтобы:
- Каждая обучающая точка "относилась" к одному центру кластера и лежала к нему ближе, чем к любому другому центру;
- Каждый центр кластера был центроидом множества обучающих точек, относящихся к этому кластеру.
После того, как определено расположение центров, нужно найти отклонения. Величина отклонения (ее также называют сглаживающим фактором) определяет, насколько "острой" будет гауссова функция. Если эти функции выбраны слишком острыми, сеть не будет интерполировать данные между известными точками и потеряет способность к обобщению. Если же гауссовы функции взяты чересчур широкими, сеть не будет воспринимать мелкие детали. На самом деле сказанное - еще одна форма проявления дилеммы пере/недообучения. Как правило, отклонения выбираются таким образом, чтобы колпак каждой гауссовой функций захватывал "несколько" соседних центров. Для этого имеется несколько методов:
Явный. Отклонения задаются пользователем.
Изотропный. Отклонение берётся одинаковым для всех элементов и определяется эвристически с учётом количества радиальных элементов и объёма покрываемого пространства (Haykin, 1994).
K ближайших соседей. Отклонение каждого элемента устанавливается (индивидуально) равным среднему расстоянию до его K ближайших соседей (Bishop, 1995). Тем самым отклонения будут меньше в тех частях пространства, где точки расположены густо, - здесь будут хорошо учитываться детали, - а там, где точек мало, отклонения будут большими (и будет производиться интерполяция).
После того, как выбраны центры и отклонения, параметры выходного слоя оптимизируются с помощью стандартного метода линейной оптимизации - алгоритма псевдообратных матриц (сингулярного разложения) (Haykin, 1994; Golub and Kahan, 1965).
Могут быть построены различные гибридные разновидности радиальных базисных функций. Например, выходной слой может иметь нелинейные функции активации, и тогда для его обучения используется какой-либо из алгоритмов обучения многослойных персептронов, например, метод обратного распространения. Можно также обучать радиальный (скрытый) слой с помощью алгоритма обучения сети Кохонена - это ещё один способ разместить центры так, чтобы они отражали расположение данных.
Вероятностная нейронная сеть
В предыдущем разделе, говоря о задачах классификации, мы кратко упомянули о том, что выходы сети можно с пользой интерпретировать как оценки вероятности того, что элемент принадлежит некоторому классу, и сеть фактически учится оценивать функцию плотности вероятности. Аналогичная полезная интерпретация может иметь место и в задачах регрессии - выход сети рассматривается как ожидаемое значение модели в данной точке пространства входов. Это ожидаемое значение связано с плотностью вероятности совместного распределения входных и выходных данных.
Задача оценки плотности вероятности (p.d.f.) по данным имеет давнюю историю в математической статистике (Parzen, 1962) и относится к области байесовой статистики. Обычная статистика по заданной модели говорит нам, какова будет вероятность того или иного исхода (например, что на игральной кости шесть очков будет выпадать в среднем одном случае из шести). Байесова статистика переворачивает вопрос вверх ногами: правильность модели оценивается по имеющимся достоверным данным. В более общем плане, байесова статистика дает возможность оценивать плотность вероятности распределений параметров модели по имеющимся данных. Для того, чтобы минимизировать ошибку, выбирается модель с такими параметрами, при которых плотность вероятности будет наибольшей.
При решении задачи классификации можно оценить плотность вероятности для каждого класса, сравнить между собой вероятности принадлежности различным классам и выбрать наиболее вероятный. На самом деле именно это происходит, когда мы обучаем нейронную сеть решать задачу классификации - сеть пытается определить (т.е. аппроксимировать) плотность вероятности.
Традиционный подход к задаче состоит в том, чтобы построить оценку для плотности вероятности по имеющимся данным. Обычно при этом предполагается, что плотность имеет некоторый определенный вид (чаще всего - что она имеет нормальное распределение). После этого оцениваются параметры модели. Нормальное распределение часто используется потому, что тогда параметры модели (среднее и стандартное отклонение) можно оценить аналитически. При этом остается вопрос о том, что предположение о нормальности не всегда оправдано.
Другой подход к оценке плотности вероятности основан на ядерных оценках (Parzen, 1962; Speckt, 1990; Speckt, 1991; Bishop, 1995; Patterson, 1996). Можно рассуждать так: тот факт, что наблюдение расположено в данной точке пространства, свидетельствует о том, что в этой точке имеется некоторая плотность вероятности. Кластеры из близко лежащих точек указывают на то, что в этом месте плотность вероятности большая. Вблизи наблюдения имеется большее доверие к уровню плотности, а по мере отдаления от него доверие убывает и стремится к нулю. В методе ядерных оценок в точке, соответствующей каждому наблюдению, помещается некоторая простая функция, затем все они складываются и в результате получается оценка для общей плотности вероятности. Чаще всего в качестве ядерных функций берутся гауссовы функции (с формой колокола). Если обучающих примеров достаточное количество, то такой метод дает достаточно хорошее приближение к истинной плотности вероятности.
Метод аппроксимации плотности вероятности с помощью ядерных функций во многом похож на метод радиальных базисных функций, и таким образом мы естественно приходим к понятиям вероятностной нейронной сети (PNN) и обобщенно-регрессионной нейронной сети (GRNN) (Speckt 1990, 1991). PNN-сети предназначены для задач классификации, а GRNN - для задач регрессии. Сети этих двух типов представляют собой реализацию методов ядерной аппроксимации, оформленных в виде нейронной сети.
Сеть PNN имеет по меньшей мере три слоя: входной, радиальный и выходной. Радиальные элементы берутся по одному на каждое обучающее наблюдение. Каждый из них представляет гауссову функцию с центром в этом наблюдении. Каждому классу соответствует один выходной элемент. Каждый такой элемент соединен со всеми радиальными элементами, относящимися к его классу, а со всеми остальными радиальными элементами он имеет нулевое соединение. Таким образом, выходной элемент просто складывает отклики всех элементов, принадлежащих к его классу. Значения выходных сигналов получаются пропорциональными ядерным оценкам вероятности принадлежности соответствующим классам, и, пронормировав их на единицу, мы получаем окончательные оценки вероятности принадлежности классам.
Базовая модель PNN-сети может иметь две модификации.
В первом случае мы предполагаем, что пропорции классов в обучающем множестве соответствуют их пропорциям во всей исследуемой популяции (или так называемым априорным вероятностям). Например, если среди всех людей больными являются 2%, то в обучающем множестве для сети, диагностирующей заболевание, больных должно быть тоже 2%. Если же априорные вероятности будут отличаться от пропорций в обучающей выборке, то сеть будет выдавать неправильный результат. Это можно впоследствии учесть (если стали известны априорные вероятности), вводя поправочные коэффициенты для различных классов.
Второй вариант модификации основан на следующей идее. Любая оценка, выдаваемая сетью, основывается на зашумлённых данных и неизбежно будет приводить к отдельным ошибкам классификации (например, у некоторых больных результаты анализов могут быть вполне нормальными). Иногда бывает целесообразно считать, что некоторые виды ошибок обходятся "дороже" других (например, если здоровый человек будет диагностирован как больной, то это вызовет лишние затраты на его обследование, но не создаст угрозы для жизни; если же не будет выявлен действительный больной, то это может привести к смертельному исходу). В такой ситуации те вероятности, которые выдает сеть, следует домножить на коэффициенты потерь, отражающие относительную цену ошибок классификации. В пакете ST Neural Networks в вероятностную нейронную сеть может быть добавлен четвертый слой, содержащий матрицу потерь. Она умножается на вектор оценок, полученный в третьем слое, после чего в качестве ответа берется класс, имеющий наименьшую оценку потерь. (Матрицу потерь можно добавлять и к другим видам сетей, решающих задачи классификации.)
Вероятностная нейронная сеть имеет единственный управляющий параметр обучения, значение которого должно выбираться пользователем, - степень сглаживания (или отклонение гауссовой функции). Как и в случае RBF-сетей, этот параметр выбирается из тех соображений, чтобы шапки "определённое число раз перекрывались": выбор слишком маленьких отклонений приведет к "острым" аппроксимирующим функциям и неспособности сети к обобщению, а при слишком больших отклонениях будут теряться детали. Требуемое значение несложно найти опытным путём, подбирая его так, чтобы контрольная ошибка была как можно меньше. К счастью, PNN-сети не очень чувствительны к выбору параметра сглаживания.
Наиболее важные преимущества PNN-сетей состоят в том, что выходное значение имеет вероятностный смысл (и поэтому его легче интерпретировать), и в том, что сеть быстро обучается. При обучения такой сети время тратится практически только на то, чтобы подавать ей на вход обучающие наблюдения, и сеть работает настолько быстро, насколько это вообще возможно.
Существенным недостатком таких сетей является их объём. PNN-сеть фактически вмещает в себя все обучающие данные, поэтому она требует много памяти и может медленно работать.
PNN-сети особенно полезны при пробных экспериментах (например, когда нужно решить, какие из входных переменных использовать), так как благодаря короткому времени обучения можно быстро проделать большое количество пробных тестов. В пакете ST Neural Networks PNN-сети используются также в Нейрогенетическом алгоритме отбора входных данных - Neuro-Genetic Input Selection, который автоматически находит значимые входы (будет описан ниже).
Виталий Елин
|
Здравствуйте! Здесь вначале говориться что выдается диплом, а внизу страницы сказано что нет |
{kind=link}
{kind=link}