













|
как начать заново проходить курс, если уже пройдено несколько лекций со сданными тестами? |
Опубликован: 02.03.2017 | Доступ: свободный | Студентов: 2609 / 615 | Длительность: 21:50:00
Тема: Безопасность
Лекция 6:
Классические шифры
6.9 Энтропия на знак, избыточность и расстояние единственности
Мерой среднего количества информации, приходящейся на одну букву открытого текста языка 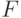 , который будем рассматривать как источник случайных текстов, служит величина
, который будем рассматривать как источник случайных текстов, служит величина  , называемая энтропией языка. Интерес представляет энтропия вероятностной схемы на
, называемая энтропией языка. Интерес представляет энтропия вероятностной схемы на 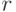 -граммах, деленная на . Известно, что существует конечный предел, который и принимается за определение энтропии языка F:
-граммах, деленная на . Известно, что существует конечный предел, который и принимается за определение энтропии языка F:

При этом формула

определяет избыточность языка . Как известно, если длина криптограммы не большая, то результат расшифрования может дать несколько осмысленных текстов.
Найдём оценку для числа ложных ключей. Для этого рассмотрим связь между энтропиями вероятностных распределений  ,
,  ,
,  , заданных на компонентах
, заданных на компонентах  ,
, 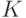 ,
,  произвольного шифра
произвольного шифра  .
.
Назовем условную энтропию  неопределенностью шифра
неопределенностью шифра  по ключу. Она измеряет среднее количество информации о ключе, которую дает шифртекст. Аналогично вводится неопределенность шифра по открытому тексту
по ключу. Она измеряет среднее количество информации о ключе, которую дает шифртекст. Аналогично вводится неопределенность шифра по открытому тексту  . Эти величины являются мерой теоретической стойкости шифра.
. Эти величины являются мерой теоретической стойкости шифра.
Рассмотрим произвольный поточный шифр замены , для которого множество открытых текстов представляет собой множество возможных осмысленных текстов в данном алфавите  (например, русском, английском или некотором другом), состоящим из
(например, русском, английском или некотором другом), состоящим из  букв. Зафиксируем некоторое число
букв. Зафиксируем некоторое число  и будем интересоваться числом ложных ключей, отвечающих данной криптограмме
и будем интересоваться числом ложных ключей, отвечающих данной криптограмме  . Предполагается, что служит также алфавитом шифрованного текста. Введем обозначение:
. Предполагается, что служит также алфавитом шифрованного текста. Введем обозначение:

 есть множество ключей, для каждого из которых
есть множество ключей, для каждого из которых  является результатом шифрования некоторого осмысленного текста длины
является результатом шифрования некоторого осмысленного текста длины 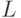 . Если мы располагаем криптограммой , то число ложных ключей равно
. Если мы располагаем криптограммой , то число ложных ключей равно  , так как лишь один из допустимых ключей является истинным. Определим среднее число ложных ключей
, так как лишь один из допустимых ключей является истинным. Определим среднее число ложных ключей  (относительно всех возможных шифртекстов длины ) формулой:
(относительно всех возможных шифртекстов длины ) формулой:

которая легко приводится к виду

Теорема 6.4 Для любого рассматриваемого шифра с равновероятными ключами при достаточно больших значениях имеет место неравенство

где  - избыточность данного языка.
- избыточность данного языка.
Назовем расстоянием единственности для шифра натуральное число (обозначим его  ), для которого ожидаемое число ложных ключей
), для которого ожидаемое число ложных ключей  равно нулю. По сути, расстояние единственности есть средняя длина шифртекста, необходимая для однозначного восстановления истинного ключа (без каких-либо ограничений на время его нахождения).
равно нулю. По сути, расстояние единственности есть средняя длина шифртекста, необходимая для однозначного восстановления истинного ключа (без каких-либо ограничений на время его нахождения).

Большинство криптосистем слишком сложны для точного определения расстояния единственности, однако в некоторых случаях оно может быть аппроксимировано соотношением  .
.
Оценим расстояние единственности шифра Виженера со случайным ключевым словом длиной 4 символа для сообщений на английском языке.
Ключ шифра - это набор из четырех чисел, каждое из которых является случайным сдвигом в диапазоне от 0 до 25. Энтропия ключа  . Для языка из 26 символов
. Для языка из 26 символов  . Для длинных сообщений на английском языке оценка
. Для длинных сообщений на английском языке оценка  составляет от 1 до 1,5. Взяв значение
составляет от 1 до 1,5. Взяв значение  , можно вычислить
, можно вычислить  . Таким образом, однозначное дешифрование шифра Виженера с 4-х символьным ключом возможно при длине шифртекста не менее 6 символов.
. Таким образом, однозначное дешифрование шифра Виженера с 4-х символьным ключом возможно при длине шифртекста не менее 6 символов.
Пример 6.14 ([6]) Пусть источник порождает буквы из алфавита  с вероятностями
с вероятностями  ,
,  ,
,  . Пусть у нас источник без памяти. Шифрование состоит в замене буквы в исходном сообщении, используя перестановку символов в соответствии с ключом:
. Пусть у нас источник без памяти. Шифрование состоит в замене буквы в исходном сообщении, используя перестановку символов в соответствии с ключом:  , то есть ключ принимает значения от 1 до 6 и если, например, k=5, то производится следующая замена символов текста:
, то есть ключ принимает значения от 1 до 6 и если, например, k=5, то производится следующая замена символов текста:  . Пусть противник перехватил шифрованное сообщение cccbc и пытается определить значение ключа. Оценим вероятности использования всех возможных ключей.
. Пусть противник перехватил шифрованное сообщение cccbc и пытается определить значение ключа. Оценим вероятности использования всех возможных ключей.
Используем формулу Байеса:

где  - некоторые события,
- некоторые события,  попарно несовместны и
попарно несовместны и  . В нашем случае событие
. В нашем случае событие 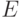 - это получение шифрованного сообщения
- это получение шифрованного сообщения  , t=6, а
, t=6, а 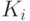 означает, что выбран ключ
означает, что выбран ключ  .
.
Мы предполагаем, что все ключи равновероятны, т.е.

Тогда
Отсюда легко находим

и получаем по формуле Байеса апостериорную вероятность того, что был использован ключ 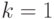 , при условии, что получено сообщение
, при условии, что получено сообщение  :
:

Продолжая аналогично, находим наиболее вероятные ключи для  и
и  :
:
а вероятности всех остальных ключей меньше 0.01.
Мы видим, что, перехватив всего пять букв, противник может определить ключ почти однозначно. Если избыточность сообщения равна нулю, то ключ никогда не будет определен. Уменьшение избыточности может быть достигнуто за счет сжатия данных. Это объясняется тем, что при сжатии энтропия "сжатого" текста сохраняется, а длина уменьшается. Следовательно, энтропия на букву в сжатом тексте больше, чем в исходном, а избыточность меньше. Таким образом, после сжимающего кодирования расстояние единственности шифра увеличивается. Поясним примером , как взаимная зависимость символов увеличивает избыточность и тем самым уменьшает расстояние единственности.
Пример 6.15 Пусть имеется марковский источник сообщений, вероятность  появления
появления  -го символа после
-го символа после  -го задаётся матрицей:
-го задаётся матрицей:

Заданы начальные вероятности:  ,
,  ,
,  . Возможные ключи:
. Возможные ключи:  ,
,  ,
,  ,
,  ,
,  ,
,  .
.
Пусть перехвачен шифртекст:  . Какой ключ использовался при шифровании?
. Какой ключ использовался при шифровании?
Зная матрицу переходов, мы можем сделать вывод: сочетание 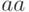 невозможно (после буквы
невозможно (после буквы  вероятность появления снова буквы равна нулю), вероятность появления
вероятность появления снова буквы равна нулю), вероятность появления  после равна 0,1 , то есть сочетание
после равна 0,1 , то есть сочетание 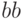 маловероятно. Поэтому наиболее вероятная первая пара букв открытого текста
маловероятно. Поэтому наиболее вероятная первая пара букв открытого текста 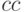 , у нас есть гипотеза: при зашифровании была проведена замена:
, у нас есть гипотеза: при зашифровании была проведена замена:  . Тогда другие замены возможные:
. Тогда другие замены возможные:  и
и  либо
либо  и
и  . В первом варианте паре букв шифртекста ac соответствует пара букв открытого текста
. В первом варианте паре букв шифртекста ac соответствует пара букв открытого текста  . Но сочетание невозможно, как видно из матрицы переходов, а сочетание
. Но сочетание невозможно, как видно из матрицы переходов, а сочетание  возможно. Следовательно,наиболее вероятным ключом является подстановка:
возможно. Следовательно,наиболее вероятным ключом является подстановка:  Для проверки нашей гипотезы вычислим вероятности использования различных ключей. Заметим, что вероятность сообщения равна произведению вероятности начальной буквы и вероятностей переходов от одной буквы к другой.
Для проверки нашей гипотезы вычислим вероятности использования различных ключей. Заметим, что вероятность сообщения равна произведению вероятности начальной буквы и вероятностей переходов от одной буквы к другой.
Применяем формулу полной вероятности:

Тепрерь по формуле Байеса апостериорные вероятности использования ключей при условии получения шифртекста bbacbac следующие:

Вычисления подтверждают нашу гипотезу.